

서 론
재료 및 방법
1. 데이터수집
2. 생성형 AI
3. YOLOv9
4. 평가 방법
결과 및 고찰
1. AI 생성 이미지
2. AI 생성 이미지를 통한 과실 탐지
3. AI 생성 이미지를 통한 과실 품질 평가
4. 한계 및 함의
서 론
최근 몇 년간 인공지능과 딥러닝 기술의 비약적인 발전은 이미지 분류, 객체 탐지, 의미론적 분할 등에 있어서 놀라운 성과를 이루었다(Bayoudh 등, 2022). 이러한 기술들은 정확하고 신뢰할 수 있는 성능을 발휘하기 위해 대규모의 고품질 이미지 데이터셋을 필요로 한다(Zhao 등, 2019). 그러나 농업 분야에서는 다양한 환경에서의 농작물 이미지를 포괄하는 데이터셋을 구축하는데 많은 시간과 자원이 소요되기 때문에 대규모 이미지 데이터가 매우 부족한 현실에 직면해 있다(Lu와 Young, 2020).
이러한 문제를 해결하기 위해 최근 생성 이미지가 주목받고 있다(Meor Yahaya와 Teo, 2023). 컴퓨터 알고리즘으로 생성된 합성 이미지는 헬스케어, 패션, 건축, 지리공간 연구 등 다양한 분야에서 널리 사용되어 왔다(Bermano 등, 2022; Chen 등, 2021; Choi 등, 2022; Luo 등, 2022; Sapkota 등, 2022). 전통적인 이미지 생성 방법인 파라메트릭 기법(Chen 등, 2021), 레이 트레이싱(Mildenhall 등, 2022), 물리 기반 렌더링(Hodan 등, 2019)은 합성 이미지 기술을 발전시켰다. 그러나 이러한 방법들은 복잡한 형태에 적응하기 어렵고(Velikina 등, 2013), 높은 계산 요구량과 시간 문제, 유연성 부족 등의 한계를 가지고 있다(Diolatzis 등, 2022; Eversberg 등, 2021; Sapkota 등, 2024). 반면, 생성형 AI는 기존의 데이터 증강 기법과 비교하여 훨씬 더 적은 시간과 비용으로 많은 변화와 정보를 데이터셋에 부여할 수 있는 잠재력을 가지고 있어, 연구 개발의 효율성을 크게 향상시킬 수 있다(Khalifa 등, 2022; Shorten과 Khoshgoftaar, 2019; Wong 등, 2016).
농업 분야 선행 연구에서도 토마토 잎 병해 분류, 해충 판별, 및 잡초 모델 개발에 합성 이미지를 활용한 데이터 증강이 유효한 것으로 보고된 바 있으며(Abbas 등, 2021; Chen 등, 2024; Lu 등, 2019), 생성형 AI가 농업 데이터셋 합성 및 품질 향상에 중요한 도구로 자리잡고 있음을 보여주었다. 병해충 분류 외에도 농업 생산물의 품질 평가는 이미지 데이터가 효과적으로 사용될 수 있는 주요 영역이다(Bird 등, 2022; Olatunji 등, 2020).
한편, 네트 멜론은 매력적인 외관과 향미로 인해 높은 시장 가치를 지니고 있으며, 착과기부터 수확기까지 다양한 단계를 거치며 과실의 생리적 특성과 외형이 크게 변화한다(Ezura와 Hiwasa-Tanase, 2009; Kano과 Fukuoka, 2006). 과실 비대기에는 급격한 성장과 함께 과피의 경화 및 균열이 시작되어 네트 패턴이 형성되는데, 이는 멜론의 상업적 가치를 결정하는 중요한 요소이다. 네트와 같은 공극에 대한 연구는 균열 및 패턴을 정량화하는데(Akiba 등, 2022; Gerchikov 등, 2008; Li 등, 2012), 등급 분류 및 품질 분석에 있어서 생성형 AI 연구는 아직 미진한 상황이다.
본 연구는 머스크멜론의 복잡한 패턴 재현과 다양한 변형에 있어서 생성형 이미지의 잠재력을 탐색하기 위하여 재배 환경에서의 과실 탐지와 네트 분석 방법론을 적용하고 평가하는 것을 목표로 한다. 이를 위해 생성형 이미지의 품질을 평가하고, 멜론 과실 이미지로 파인튜닝된 YOLOv9을 이용하여 생성형 이미지에서 멜론을 탐지하고, 네트 분석 방법론(Yoon 등, 2023)을 통해 네트의 밀도와 균일성을 조사하여 재현성을 평가하였다. 이를 통해 농작물의 기하학적 패턴을 정밀하게 재현하는 생성형 이미지의 가능성을 확인하고, 데이터셋의 다양성과 품질을 높이며, 실질적인 적용 가능성을 탐구하고자 한다.
재료 및 방법
1. 데이터수집
멜론 과실 이미지 획득은 과일 수확 전, 후에 수행되었다. 수확 전 이미지는 1920 × 1080 픽셀 해상도의 스마트폰(Galaxy S22, Samsung Electronics Co., Suwon, Korea)을 사용하여 자연광 조건에서 과일의 이미지를 수집했다. 수확 후 이미지는 상부에 LED 조명이 있는 직육면체 구조의 스튜디오(W80 × L80 × H80 cm)에서 위와 동일한 카메라를 사용하여 이미지를 수집했다.
2. 생성형 AI
생성형 AI 모델은 텍스트-이미지, 이미지-이미지, 및 이미지-비디오 변환 등을 통해 고품질의 이미지를 생성할 수 있다(Karras 등, 2019). 이러한 기술은 데이터 증강(data augmentation)을 통해 대규모 이미지 데이터셋의 부족 문제를 해결하는 데 큰 잠재력을 가지고 있다(Shorten과 Khoshgoftaar, 2019). 멜론 과실 이미지를 생성하기 위해 대표적인 생성형 AI 도구인 미드저니(Midjourney Basic Plan, Midjourney, San Francisco, CA, US)와 파이어플라이(Firefly, Adobe, San Joce, CA, US)를 이용하였다. 일반적인 이미지 생성 방법으로 제시되는 프롬프트를 통한 텍스트-이미지 생성은 직관적인 제어에 유용하지만, 공간적 모호성이 있고 충분한 사용자 제어를 허용하지 않는다. 본 연구에서는 생성형 이미지의 품질 변화와 복합적인 농업 시스템을 포착하기 위하여 아래 3가지 과정을 통하여 이미지를 생성하였다.
2.1 텍스트-이미지 생성
텍스트-이미지 생성은 프롬프트의 주제와 스타일, 파라미터를 통해 이미지 변화를 세심하게 포착하는 것이 수반된다. 본 연구에서는 미드저니의 ‘describe’ 명령어를 통해 이미지에서 프롬프트를 생성하였으며, 이 프롬프트를 기반으로 이미지를 생성하였다. 프롬프트에 사용된 이미지들은 멜론 재배 온실의 이미지, 수확 후 단일 과실 이미지 등을 포함한다.
2.2 수확 전 이미지-이미지 생성
이미지-이미지 생성 기법은 텍스트-이미지 생성 방법에 비해 원본 이미지의 구조, 스타일을 참조하는 동시에 선명도와 품질을 향상시키고, 정확하고 현실적인 이미지를 생성할 수 있다(Sapkota 등, 2024).
수확 전 이미지: 멜론 재배 온실의 이미지는 과실 생육 단계, 카메라 각도, 조명, 초점 등에 따라 매우 다양한 이미지셋이 구성되었고, 이러한 다양한 이미지를 참조 이미지로서 활용하여 유사한 구조의 이미지들을 생성하였다.
2.3 수확 후 이미지-이미지 생성
수확 후 이미지: 멜론 과실 이미지는 수확 후 단일 과실에 초점을 맞추어, 멜론의 외적 품질인 네트를 평가하는 목적으로 생성하였다.
3. YOLOv9
YOLOv9는 실시간 객체 탐지 기술에서 획기적인 진보를 이룬 최신 버전이다. 2024년 2월에 발표된 이 버전은 PGI (Programmable Gradient Information)와 GELAN(Generalized Efficient Layer Aggregation Network) 같은 혁신적인 기술을 도입하였다. PGI는 신경망의 순방향 패스에서 정보가 변환 과정에서 희석되거나 손실될 수 있는 문제를 해결하고, GELAN은 경량 설계, 빠른 추론, 정확성을 중시하며 정보 병목 문제를 직접 해결한다(Vo 등, 2024). YOLOv9는 다양한 지표에서 현재의 최신 모델들보다 뛰어난 성능을 보이며, 더 적은 파라미터로 동일하거나 더 높은 정확성을 유지할 수 있다. 본 연구에서는 총 700장의 실제 멜론 이미지 데이터를 이용하여 YOLOv9를 멜론 과실을 탐지하도록 파인튜닝하였으며, 다양한 환경 조건을 표현하는 AI 생성 이미지(40개)에서의 멜론 과실을 탐지하는데 이용했다. YOLOv9를 멜론 과실 탐지에 최적화하기 위해 이미지 크기 640, 배치 크기 16, 에포크 50, 그리고 hyp.scratch-high.yaml 파일을 통해 세부적인 하이퍼파라미터 값을 조정하여 훈련을 진행하였다.
4. 평가 방법
4.1 생성 이미지 평가
Peak signal to noise ratio(PSNR): PSNR은 이미지 품질을 평가하는 지표로, 원본 이미지로 표현되는 최대 잠재력과 원본 이미지와 AI 생성 이미지 간의 차이를 나타내는 노이즈의 비율로 평가한다. 이 비율은 Eq. (1)에 따라 계산되고 평균제곱오차()는 Eq. (2)에 따라 추정된다. PSNR 값이 높을수록 생성된 이미지가 원본 이미지에 더 가까워지며, 왜곡이 최소화된 것을 나타낸다(Sapkota 등, 2024). 여기서 는 픽셀 값의 최대값을 나타내며, 는 생성된 이미지()가 원본 이미지()와 픽셀 단위로 얼마나 차이가 있는지를 나타내는 지표로, 가 낮을수록 두 이미지 간의 차이가 적음을 의미한다.
Structural Similarity Index Measure(SSIM): SSIM은 PSNR과 같이 변형되거나 생성된 이미지를 평가하는 지표로, 두 이미지() 간의 상관계수를 Luminance(휘도), Contrast (대비), Structure(구조) 3가지 측면에서 평가한다(Wang 등, 2004). 휘도는 빛의 밝기, 대비는 밝기 차이, 구조는 상관관계를 나타내며, 이미지 내의 픽셀의 평균, 표준편차, 공분산을 통해 위 값을 계산할 수 있다.
4.2 YOLOv9 과실 탐지 정확성 평가
Intersection over union(IoU): IoU는 객체 검출의 정확도를 평가하는 지표로, 개별 객체에 대한 검출이 성공하였는지 결정하며, 0-1 사이의 값을 가진다. 컴퓨터 비전 및 객체 탐지 분야에서 경계 상자(바운딩 박스)는 일반적으로 2D 이미지에서 직사각형으로 표현된다. 이 표현을 기반으로, 실제 경계 상자(, Ground truth)와 예측된 경계 상자() 간의 IoU 계산은 다음과 같이 정의된다(Zhou등, 2019).
4.3 생성 이미지의 네트 품질 평가
네트 품질은 멜론 육안 검사에서 주요 평가 지표로 활용되는 네트의 밀도와 균일성을 통해 평가하였다. 네트 품질 차이를 시각화하기 위하여, 우수한 네트 품질의 기준이 되는 과실(20개)을 선별하였으며, 생성된 이미지 역시 20개로 분류하였다. 이 후, 각 데이터 세트에서 과실만을 포함한 마스크를 추출하고, 컴퓨터 비전 알고리즘을 통해 네트의 과피와 색상을 구분하였고, 픽셀 상의 과피 조각들의 평균 면적(네트 밀도)과 표준편차(네트 균일도)를 계산하였다(Yoon 등, 2023).
결과 및 고찰
1. AI 생성 이미지
텍스트를 통한 네트 멜론 이미지 생성 결과는 Fig. 1A에 나열된 바와 같다. 미드저니와 파이어플라이 두 생성형 AI 도구는 온실에서 재배되는 멜론 과실에 초점을 맞춘 이미지를 생성하였다. 미드저니는 현실적이고 자연스러운 색감을 통해 실제 사진과 같은 이미지를 생성하였으며, 세부 묘사와 자연스러운 그림자가 특징이다. 반면, 파이어플라이는 강렬하고 선명한 색감을 통해 이미지를 더욱 인상 깊게 표현하였고, 색상의 대비가 뚜렷한 것이 특징이다. 고품질 이미지 생성을 위해서는 광범위한 단어 및 파라미터 조합에 따른 프롬프트 엔지니어링과 시행착오가 요구된다. 본 연구에서는 프롬프트에 의한 이미지 편차를 줄이기 위하여, 미드저니의 프롬프트를 생성하는 기능을 이용하였다(Fig. 1B). 이는 원본 이미지를 AI가 분석하고, 의미론적 특징을 프롬프트로 출력하는 기능이다. 그 결과, 객체, 배경, 카메라 각도 및 구도, 스타일을 포함하는 다양한 프롬프트를 획득하였으며, 이를 통하여 새로운 이미지셋을 확보할 수 있었다.

이미지-이미지 생성은 참조 이미지의 구조 및 스타일을 참고하여 원본 이미지의 특징을 보존하고 선명도와 현실성을 향상시킬 수 있는 방법이다. 수확 전 과실 이미지를 참조하여 생성된 결과는 매우 현실적이며, 다양한 각도와 조명에서의 이미지들을 포함하고 있다(Fig. 2). 이는 수경 재배 하의 멜론 작물 재식 및 유인 방식, 곁가지의 특징까지 상세히 반영하였으며, 실제 온실 환경을 효과적으로 재현하였다. 한편, 수확 후 과실 이미지 결과는 멜론 과실의 외적 특징을 상세히 묘사하며, 생성형 AI가 과실의 외적 품질 평가에 유용하게 사용될 수 있음을 시사하였다(Fig. 3).


본 연구에서는 앞서 제시한 3가지 이미지 생성 방법을 이용하여 데이터 증강을 진행하였고, 이렇게 생성된 데이터셋과 원본 이미지 간의 정량적 유사성을 평가하였다(Fig. 4). 평가 결과, PSNR 값의 평균과 표준 편차는 텍스트-이미지, 이미지-이미지(수확 전), 이미지-이미지(수확 후) 데이터셋 그룹에 대해 각각 27.4 ± 0.6, 27.9 ± 0.05, 28.8 ± 0.3으로 나타났다(Table 1). 1에 가까울수록 원본 이미지와 유사성이 높은 SSIM 값은 0.06 ± 0.02, 0.12 ± 0.03, 0.42 ± 0.1로 나타났다. 이러한 결과는, 텍스트 및 수확 전 이미지를 통한 이미지 생성이 원본 이미지와 높은 유사성을 보였으나, 밝기, 대비, 및 구조 등의 변화가 많이 되었다는 점을 시사한다. 반면, 수확 후 단일 과실을 통한 데이터 증강은 제한된 배경과 과실만을 생성하기 때문에, 원본 이미지와 높은 유사성을 보이는 동시에 구조적 특징을 최대한 반영할 수 있었다. 생성형 이미지는 네트 멜론의 복잡한 외적 특징을 정밀하게 재현하는 동시에, 원본 이미지와 높은 유사성을 유지하는 다양한 이미지 데이터셋을 구축할 수 있다는 점에서 멜론 품질 평가에 유용하게 활용될 수 있다.

Table 1.
Evaluation metrics for PSNR and SSIM across different AI-generated image conditions. The PSNR and SSIM values indicate the quality and similarity of the images generated under each condition. Different letters (a, b, c) denote statistically significant differences between the groups at p < 0.05. The asterisks (***) represent the level of statistical significance determined by the Tukey HSD post-hoc test (p < 0.001).
| Metric |
Text-image (no input) |
Image-image (pre-harvest) |
Image-image (post-harvest) |
| PSNR | 27.5 c | 27.9 b | 28.8 a |
| SSIM | 0.06 c | 0.12 b | 0.42 a |
| Significance | *** | *** | *** |
2. AI 생성 이미지를 통한 과실 탐지
제안된 YOLOv9 이미지 처리 알고리즘을 사용하여 다양한 과실 발달 단계에서의 멜론을 탐지하는 결과는 다음과 같다(Fig. 5). YOLOv9의 예측은 40개의 실제 경계 상자(Ground truth)를 이용한 멜론 과실 탐지에서 IoU 결과 0.95로 매우 높은 성능을 보였다. 이는 재배 온실에서의 과실 비대기, 네트형성기 및 성숙기 등의 다양한 생육 단계에 있는 객체들이 잎의 가려짐 유무와 관계없이 효과적으로 탐지된 결과이다. 또한 YOLOv9은 생성형 AI 도구 미드저니 및 파이어플라이가 생성한 이미지들 역시 실제 이미지와 마찬가지로 효과적으로 탐지하였다. 생성 이미지들은 색감, 카메라 각도, 및 환경 조건(맑은 날, 흐린 날)에 있어서 다양성을 포함하였다.
딥러닝 모델의 탐지 및 분류 성능에 영향을 미치는 주요 요인으로는 이미지 데이터의 품질, 이미지 촬영 조건, 각 모델의 하이퍼파라미터 설정 등이 있다(Wang 등, 2021). 그러나 농업 현장은 밀식 재배, 잎과 작물에 의한 가려짐, 태양광에 의한 강한 조명 혹은 골조에 의한 차광 등 고품질 데이터 수집에 도전적인 환경이다. 따라서 연구자들은 이러한 농업 분야의 구조적 특징에 따른 모델의 오탐지를 극복해야할 중요한 과제로 삼는다. 대규모 데이터셋은 다양한 객체 클래스, 조명 조건 및 배경 등을 포함하여 모델이 광범위한 특징을 학습할 수 있도록 돕는다(Yu 등, 2015). 예를 들어, COCO, ImageNet 및 Pascal VOC와 같은 일반적인 데이터셋은 수백만 개의 주석이 달린 이미지를 포함하고 있으며, 이는 다양한 범주와 조건을 아우른다(Wang 등, 2021). 이러한 맥락에서 생성형 AI는 시간과 장소에 구애받지 않고, 다양한 재배 환경을 재현할 수 있어 모델 개발을 위한 데이터의 양과 다양성을 극대화할 수 있다는 장점을 지닌다.
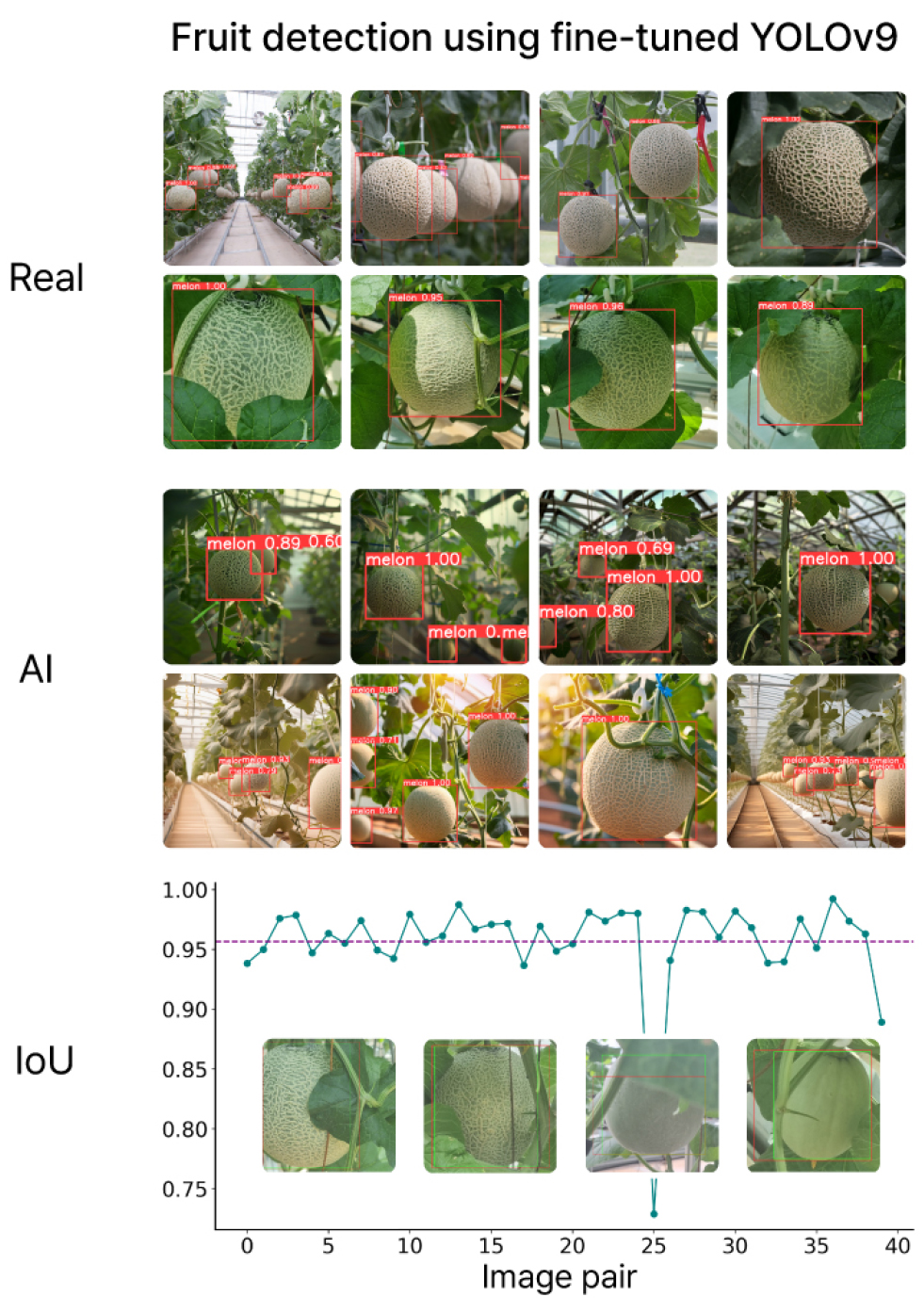
Fig. 5.
Fruit detection using fine-tuned YOLOv9 on real images and AI-generated images of melons and the Intersection over Union (IoU) evaluation. Example images within the IoU plot show the ground truth bounding boxes (green) images and predicted bounding boxes (red). The purple line represents an IoU value of 0.95.
3. AI 생성 이미지를 통한 과실 품질 평가
본 연구에서는 네트 멜론의 공극을 컴퓨터 비전 기술을 이용하여 분석하고, 네트 밀도와 균일성을 정량화하여 품질을 평가하는 방법론을 적용하였다(Yoon 등, 2023). Fig. 6AB는 관심 영역인 ROI(Region of interest)가 중첩된 대표적인 원본 이미지와 유효한 마스크를 보여주며, 우수한 품질의 실제 과실 네트와 생성된 이미지의 네트를 비교한 것이다. 이진화 기법을 통해 네트와 대조되는 과피 영역을 흰색으로 표시할 수 있었으나, 완전한 구분이 쉽지 않았다(Fig. 6C). Mono Depth Estimation 기법을 통하여 2차원 이미지 상의 얕은 영역과 깊은 영역을 탐지한 뒤, 네트와 과피를 식별할 수 있었다(Fig. 6D). 픽셀 상의 붉은 계열의 작은 과피 조각들을 개별 섬으로 간주하여, 개별 면적 값이 낮을수록 네트 밀도 값이 높고, 이러한 섬들의 면적 표준 편차 값이 낮을수록 네트 균일성이 높음을 의미한다(Fig. 6E). 이를 통해, 실제 과실과 생성된 과실의 네트 품질을 히스토그램으로 정량화할 수 있었다(Fig. 6F).
AI 생성 이미지의 네트는 실제 과실의 요철, 균열, 및 색감 등의 구체적 특징이 상세히 표현되었다. 네트 밀도는 실제 멜론의 경우 평균 4.3으로 집중되어 있으며, AI 생성 멜론의 경우 평균 7.6으로 넓은 범주의 밀도를 나타냈다. 네트 균일성은 실제 멜론의 경우 평균 9.1로 일정한 패턴을 보이는 반면, AI 생성 멜론은 평균 14.4로 더 다양한 패턴을 생성하였다. 본 실험에 활용된 과실은 우수한 네트 품질의 과실만을 선별하였기 때문에, 실제 멜론이 AI 생성 멜론에 비해 네트 밀도와 균일성이 높게 나타났다(Fig. 6F). 이러한 결과는 AI 생성 이미지가 넓은 범위의 네트의 밀도, 균일성을 표현하였으며, 실제 네트 품질 평가 방법에 이용될 수 있을 만큼 실제 멜론의 외형적 특징을 모방할 수 있음을 시사한다. 멜론의 네트는 재배 기간 동안의 정밀한 환경 조절 및 관수 전략의 결과이며, 당도와 밀접하게 관련되어 시장가치를 좌우하는 핵심 지표이다(Leiva- Valenzuela 등, 2013; Lim 등, 2020). 생성 이미지를 통한 다양한 품질의 네트 이미지 확보는 과실 품질 및 등급 분류 모델 개발에 효과적으로 이용될 수 있을 것으로 판단된다(Bird 등, 2022).
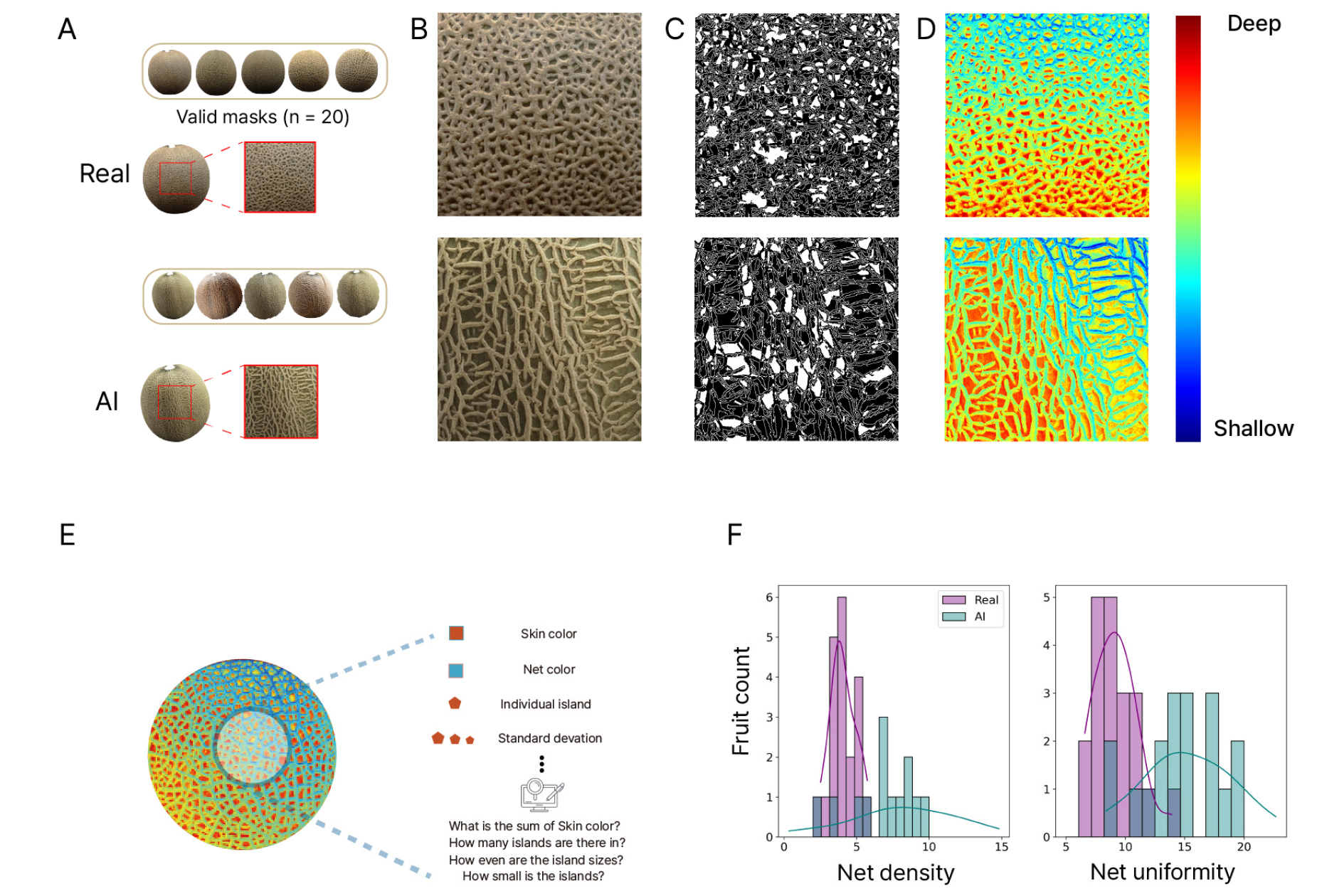
Fig. 6.
Net quality assessment process for muskmelons. Steps for analyzing melon masks: Regions of interest (ROI) on real and AI-generated melons, including valid masks from both real and AI-generated melons (n = 20) (A); Close-up views of the nets (B); Binarized images where white areas represent the exocarp area, showing that smaller and more uniform areas correspond to higher net quality (C); Depth estimation images, with red indicating the exocarp and blue indicating the net (D); Depiction of net quality quantification using computer vision (E): The exocarp color is differentiated from the net color, with each net fragment treated as a distinct island. Net density was calculated by dividing the total island area (exocarp area) by the number of islands; Quantification results of net density and uniformity, comparing real and AI-generated melons (F).
4. 한계 및 함의
본 연구에서는 텍스트-이미지 생성, 수확 전, 후 이미지-이미지 생성을 진행하여, 다양한 환경을 모사하는 멜론 이미지를 확보할 수 있었다. 텍스트-이미지 생성의 경우, 직관적으로 사용자가 원하는 이미지를 요청할 수 있으며, 창의적인 아이디어를 표현하기 쉽다(Dehouche와 Dehouche, 2023) 그러나 의미론적 모호성, 텍스트 의존성, 제한된 해석 등으로 인해 원하는 이미지를 생성하는데 어려울 수 있다. 한편, 이미지-이미지 생성은 참조 이미지를 기반으로 새로운 이미지를 생성하므로, 구체적이고 일관된 결과를 얻을 수 있는 장점이 있다. 그러나 변형 및 창의성이 제한되며, 결과가 원본 이미지 품질에 크게 좌우되며, 세부적 특징을 조정하는 것이 더 복잡할 수 있다.
이러한 한계에도 불구하고 AI 생성 이미지는 멜론 수경 재배 시스템, 수확 후 과실의 외적 품질을 상세히 묘사함으로써, 연구 개발에 큰 잠재력을 보여주었다. 멜론 과실 뿐 아니라 생성형 AI를 이용하여 다양한 작물의 영양 및 생식 생장 단계 이미지를 수집할 수 있고, 과실의 표면 상태를 정밀하게 묘사함으로써 생리장해 이미지를 확보할 수 있으며, 상품성을 기준으로 세분화된 등급 수준의 과실 이미지도 획득할 수 있다. 이는 과실 탐지 및 분류 외에도 생육 모니터링, 병해충 진단, 출하 및 유통 관리와 관련한 자동화 모델의 성능을 향상시킬 수 있는 고품질 데이터로서 활용될 수 있음을 의미한다. 현재 AI 생성 도구의 발전이 가속화됨에 따라, 본 연구의 결과는 생성형 AI의 농업 및 식물 과학 분야 적용에 기여할 것으로 기대된다.
