

서 론
재료 및 방법
1. 재배 조건
2. 환경 및 생육 조사
3. 설명변수, 반응변수의 선정
4. 더미 변수의 생성
5. 더미 변수 포함에 따른 데이터 전처리
6. 생육 모델의 비교
결 과
1. 시험 기간 중 환경 및 유묘 생육 비교
2. 설명변수, 반응변수의 선정 및 월별 더미변수의 생성
3. 월별 더미변수를 포함하지 않은 생육예측 모델 비교
4. 월별 더미계수를 포함한 생육예측 모델의 비교
5. 최적 파라미터 선정 및 모델 학습
고 찰
서 론
육묘는 정식하기에 적합한 묘를 키워내는 과정으로 작물 재배에서 묘 품질은 정식 이후 생육과 수량에 큰 영향을 끼치는 요인이다(KREI, 2011). ‘우량묘’는 품종 고유의 특성을 갖추고 지상부와 지하부의 균형 및 균일도가 높아야 하므로 정밀하고 안정적인 환경관리가 요구된다(RDA, 2008). 그 중 고추(Capsium annum L.)는 우리나라의 주요 양념채소로 환경 및 생육 변화에 따른 수량 변화가 크기 때문에 작물생장모델을 활용한 생육예측이 필요하다(Kim, 2018).
작물생장모델은 환경과 작물의 생리적 과정 간 상호작용을 수학적으로 모델링하여 생육과 수량을 예측할 수 있게 한다. 환경조건과 작물의 생리적 반응간의 관계를 파악해 멜론, 딸기, 토마토 등 다양한 작물의 생장을 최적화하기 위한 재배 환경관리에 이용되고 있다(Kwack 등, 2021; Rodríguez 등, 1999). 최근 다양한 변수간의 복잡한 상호작용을 빠르게 처리할 수 있는 머신러닝과 인공지능 기술의 활용으로 작물생장모델에도 다중 회귀모형, 랜덤포레스트, 캣부스트 등의 모델이 적용되고 있다.
온도, 강수량, 일조량 등 8가지 변수와 변수간의 상호작용을 고려한 다중 회귀분석을 통해 밀과 옥수수의 수량을 높은 예측 정확도(R2 0.95 이상)로 예측하였다(Lobell과 Asner, 2003; Matsumura 등, 2015). 랜덤 포레스트 모델은 여러 개의 의사결정 나무를 결합하여 예측 정확도를 높일 수 있으며, 수치형 및 범주형 변수를 모두 사용할 수 있다는 장점이 있다. 캣부스트 모델은 범주형 데이터 처리에 강점을 가진 모델이며 데이터를 처리할 때 이상치를 효과적으로 감지할 수 있다(Uribeetxebarria 등, 2023). 위 모델을 활용해 밀과 보리 등을 수량예측 하였을 때 기존 선형 회귀모델, Support Vector Machine(SVM) 등 다른 모델보다 높은 예측 성능을 나타내어 수량 예측 시 머신러닝 모델의 활용 가능성이 높다는 것을 보여준다(Gupta 등, 2023; Jeong 등, 2016).
그러나 작물 생육과 수확량은 계절에 따라 큰 변동을 보일 수 있어 계절 변화를 반영한 생육 예측이 필요하다. 이를 위해 더미변수(Dummy Variables), 이동평균(Moving Average), ARIMA(Autoregressive Integrated Moving average Model) 모형 등이 활용될 수 있으나 더미 변수가 특정 시점(월, 분기)을 기준으로 데이터 변동을 반영하기 때문에 복잡한 시계열 모델에 비해 직관적으로 계절성을 설명할 수 있으며(Wildt 등, 1997), 데이터의 급격한 변화와 비선형적인 영향을 효과적으로 반영할 수 있다. 더미 변수는 계절적 기후변화에 민감한 작물의 수량 예측에 사용될 수 있으며, 더미 변수를 활용해 옥수수와 밀의 수량예측 했을 때 설명력이 15% 향상된다고 보고되었다(Guera 등, 2023; Hara 등, 2021).
그러나 육묘 분야는 짧은 재배기간과 산업적 규모가 작물 생산보다 크지 않아 생장 모델의 개발이 전무하여 환경제어와 같은 표준화된 공정육묘 시스템에 적용이 부족한 실정이며, 인력에 의해 묘의 생육관리와 품질 검사가 이루어지고 있다(Kim, 2015).
이에 본 연구는 고추 유묘의 생육모델을 제시하고자 다년간 환경정보와 이에 따른 생육정보를 수집하였다. 수집된 자료의 상관분석으로 주요 환경지표와 생육지표를 선발하고 계절성 반영을 위한 지표의 가공과 월별 더미 변수 산출 후 다중회귀모형, 랜덤포레스트, 캣부스트 모델의 예측 정확도를 비교하였다.
재료 및 방법
1. 재배 조건
본 연구는 나주시에 위치한 전라남도농업기술원(35°1’29N, 126°49’44E) 단동형 시험온실(W8m×H7m×L23m)내에 설치된 육묘베드(W1.5m×L10m×H1.3m)에서 2021년 9월부터 2023년 12월까지 총 11회 육묘를 수행하였다.
고추 ‘청양 (Capsicum annuum L., cv. Cheongyang)’을 육묘용 트레이(54cm×28cm×6cm, 50구)에 육묘용 상토(코코피트 7, 피트모스 2, 펄라이트 1, EC 0.2)를 충진하여 파종하였다. 관수량은 봄·가을 1-1.5L/day, 여름 1-2.5L/day, 겨울 1-1.5L/2day로 계절과 묘 생육에 따라 변화를 주었으며, 본엽 발생 이후 수용성 복합비료(멀티피드, N-P-K 12-12-12)를 EC 0.8dS/m로 희석하여 관수하였다. 온실 환경은 복합환경제어기(마그마, ㈜ GreenCS, Korea)를 이용하여 주간 25℃, 야간 15℃로 설정하여 관리하였다.
2. 환경 및 생육 조사
시험 기간 동안 환경 데이터는 내부 온도(℃), 상대 습도(%), 일사량(W/m2) 등의 온실 환경 데이터를 1시간 단위로 복합환경제어기(마그마, ㈜ GreenCS, Korea)를 통해 수집하였다. 생육 데이터는 본엽 발생 후 3일 간격으로 모판당 10주 3반복으로 초장, 줄기굵기, 엽장, 엽폭, 엽수를 시험연구사업 조사요령(RDA, 2012)에 맞춰 파괴 조사하였다.
3. 설명변수, 반응변수의 선정
고추 유묘 생육예측을 위해 수집한 데이터 중에서 환경지표와 생육지표를 선택하였으며, 그 후 생육지표를 반응변수로, 환경지표를 설명변수로 정하였다. 생육지표 선정을 위해 초장, 줄기굵기, 엽장, 엽폭, 엽수에 대한 각각의 다중 상관분석을 진행해 가장 높은 상관성이 보이는 지표를 선정하였다.
이후 수집된 환경 데이터에 대하여 Table 1과 같이 일별 최고, 최저, 평균, 일최고-일최저 차이, 적산 등의 가공을 통해 12개의 변수로 가공하였다.
Table 1.
Processing of explanatory variables generated from collected environmental data.
환경지표를 설명변수로 선정할 때, 설명변수 증가 시 변수간 상관성이 증가하는 다중선형성이 발생할 수 있다. 이를 방지하고자 변수선택법(Recursive Feature Elimination, RFE)을 통해 주요 환경변수 5개를 선택하였으며 이를 설명변수로 하였다.
4. 더미 변수의 생성
계절적 변동 요인(Garavaglia 등, 1997)을 반영하고자 “기준 월”을 선정하고 기준 월을 뺀 11개의 더미변수를 생성했다. “기준 월”은 한국의 고추 재배작형에서 육묘 및 재배가 적은 시기인 12월로 선택했다(RDA, 2017). 시간 데이터로부터 월을 추출해 더미변수를 생성한 후 이 더미변수를 포함한 회귀식을 생성하였다.
Di : i번째 월의 더미변수(i= 1, 2, ...... 11, 기준 월=12)
t=시간 데이터(2019-05-01)
M(t)=시간 데이터 t로부터 추출한 월(1-11월)
Yt = β0 + β1X1 + β2X2 + ... + γ1D1 + γ2D2 + ... + γiDi + εt
Yt : t 작기의 반응변수
βi : 회귀 계수, Xi : 변수
Di : i번째 월의 더미변수(i= 1, 2, ...... 11, 기준 월=12)
- i번째 월에 해당될 때 1, 해당되지 않는 경우 0이 삽입됨
ε : 오차
γi : i번째 월의 더미 계수(i= 1, 2, ...... 11, 기준 월=12)
5. 더미 변수 포함에 따른 데이터 전처리
데이터 분석을 위해 생성된 설명변수와 반응변수의 데이터 양이 같아야 하나 설명변수의 단위는 일간이며 반응변수의 단위는 3일 간격으로 맞지 않아 반응변수 ‘초장’에 대하여 선형 보간법을 통해 결측치를 채웠다. 이후 각 설명변수간의 데이터 분포 차이가 크기 때문에 Min-max 정규화를 통해 값을 0에서 1 사이로 조정하였다.
이후 머신러닝 데이터 학습은 Weng(2021)과 Muraina(2022)의 방법에 따라 학습 데이터와 테스트 데이터를 8:2의 비율로 분할하여 데이터를 검증하였다.
6. 생육 모델의 비교
이 논문에서는 머신러닝 회귀 모형으로 주로 쓰이는 다중선형회귀모델, 랜덤포레스트, 캣부스트 모델에 대하여 반응변수에 더미변수 포함 여부에 따른 성능을 비교하여 R2이 높으며 RMSE(Root Mean Squared Error), MAPE(Mean Absolute Percentage Error)가 낮은 모델을 선정하였다. 이후 선정 모델에 대한 최적 파라미터를 선정한 후 최종 모델 학습을 진행하였다.
결 과
1. 시험 기간 중 환경 및 유묘 생육 비교
고추 ‘청양’ 육묘 기간은 봄, 가을 48일, 여름철 43일, 겨울철 53일로 계절별 차이를 보였다(Table 2). 육묘 온실의 계절별 평균온도는 봄 21.7℃, 여름 28.1℃, 가을 21.4℃, 겨울 17.9℃로 시험 기간 중 평균온도는 22.3℃였으며, 최대온도와 최저온도는 여름철 35℃, 겨울철 10℃였다(Fig. 1A). 일 평균 일사량은 1,510J/cm2로 여름철 2,500J/cm2, 겨울철 1,000J/cm2 이하였으며(Fig. 1B), 적산온도(℃)와 적산일사량(KJ/cm2)은 각각 856-1402℃와 57.4-95.1KJ/cm2의 분포를 보였으며, 적산온도와 적산일사량 모두 여름철이 높고 겨울철이 낮았다(Table 2).
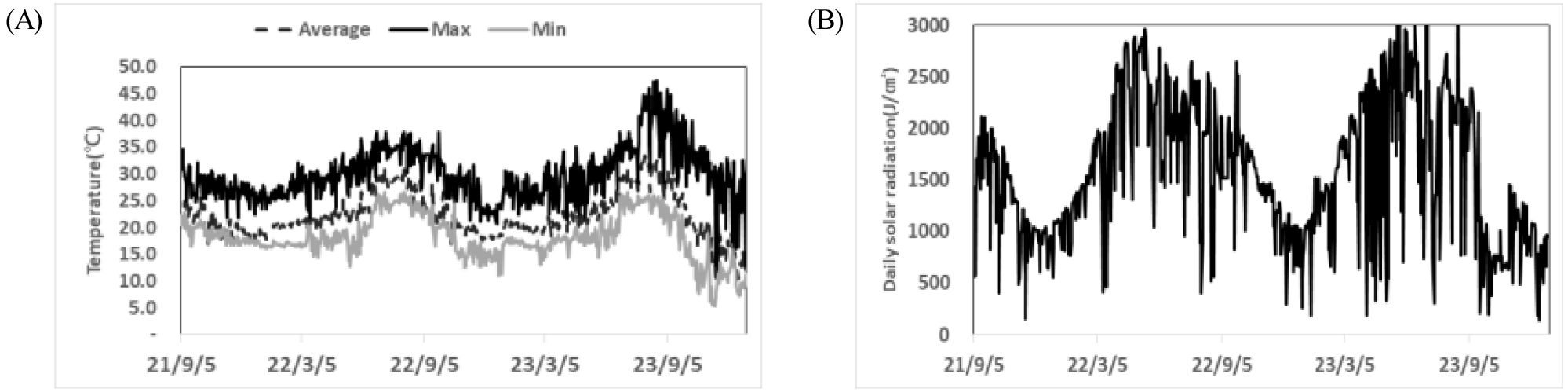
Table 2.
Accumulated temperature and Solar radiation of pepper ‘Cheongyang’ during the seedling growth period.
작기 종료시점 유묘의 평균 생육량은 초장 22.2cm, 줄기굵기 3.5mm, 엽장 7.1cm였다. 여름철(4, 5, 10작기) 작기 초장은 24.4cm로 평균보다 2.2cm, 잎의 길이는 7.6cm로 평균보다 0.5cm 길게 나타났다. 전 작기 엽수는 13.7매인데 여름 작기가 12.1매로 나타나 초장 생육에 비해 엽수가 적어 마디 간격이 길게 나타났다(Table 3).
Table 3.
Final growth characteristics of pepper ‘Cheongyang’ during seedling growth period.
2. 설명변수, 반응변수의 선정 및 월별 더미변수의 생성
생육 예측을 위한 설명변수 및 월별 더미변수를 선정한 결과는 Table 4와 같다. Table 1을 통해 생성된 12개의 변수 중 생육에 영향을 주는 주요 설명변수를 선정하고자 RFE를 진행하였다. 파종이후일수, 적산온도, 적산일사량, 일최고-일최저 온도차, 일최고-일최저 습도차를 설명변수로 선택했다.
또한 재료 및 방법 4번과 같이 환경 데이터 수집 날짜로부터 월을 추출해 더미변수 11개를 생성한 결과는 Table 4와 같다. 이후 더미변수를 포함한 생육모델 비교를 위해 기존 설명변수 5개에 더미변수 11개를 추가한 새로운 설명 변수를 생성하였다.
Table 4.
Selected explanatory variables and dummy variables for developing the pepper seedling growth prediction model.
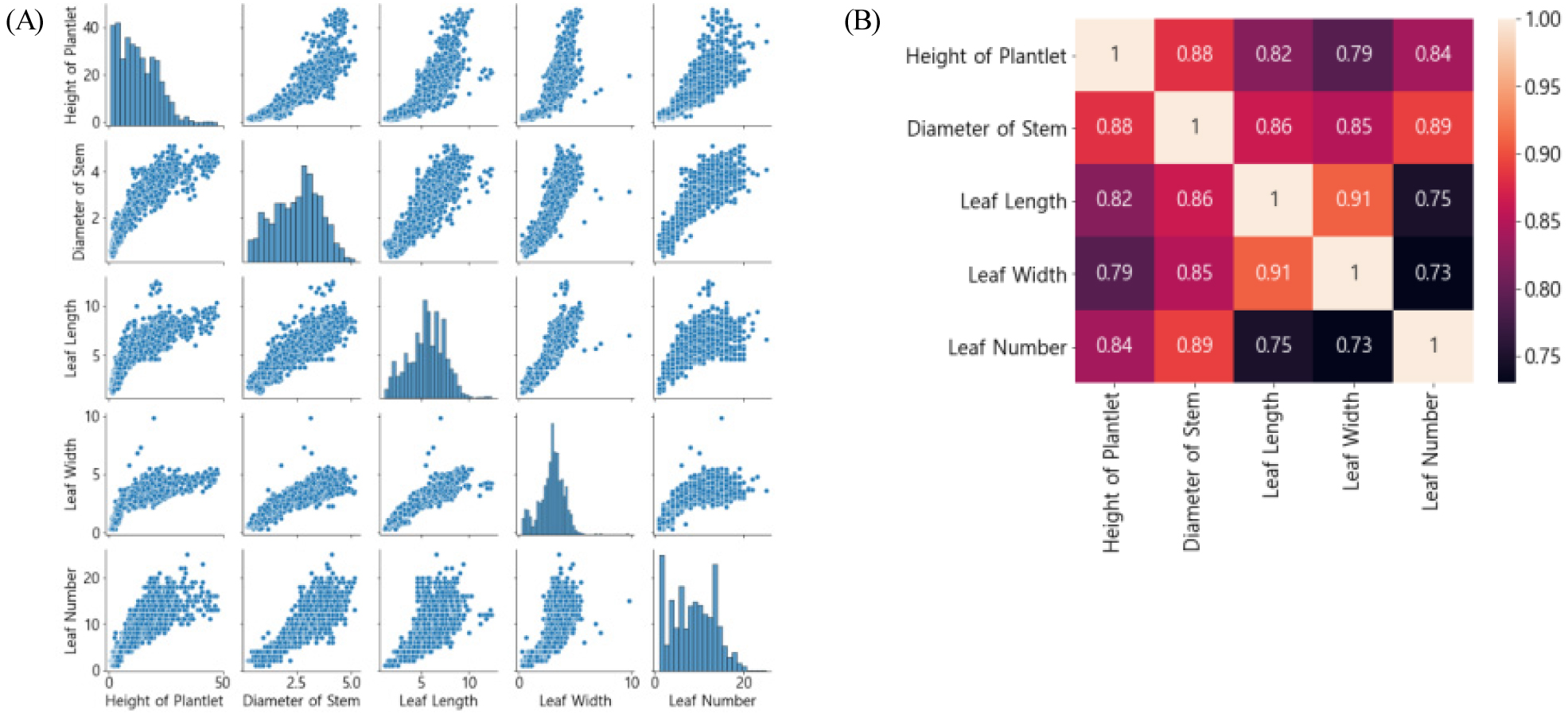
이후 반응변수 선정을 위해 초장, 줄기굵기, 엽장, 엽폭, 엽수에 대한 각각의 다중 상관분석을 진행한 결과는 Fig. 2와 같다. 초장과 줄기굵기는 엽장, 엽폭, 엽수와 각각 0.79-0.88과 0.85-0.88로 높은 상관계수를 가지고 있었다. 그 중 시간에 따른 시계열 증가 패턴을 보이며 직관적으로 생육 속도, 생육량 판별이 용이한 ‘초장’을 주요 예측 지표로 선정하였다.
3. 월별 더미변수를 포함하지 않은 생육예측 모델 비교
월별 더미변수를 포함하지 않은 설명변수를 머신러닝 모델에 입력해 고추 유묘 ‘초장’을 예측하고 그 결과를 Table 5를 통해 비교하였다. 다중선형회귀, 랜덤포레스트, 캣부스트 세 모델을 비교하였을 때 캣부스트가 설명력(R2)이 0.77로 가장 높았으나 오차 백분율을 나타내는 MAPE는 28-40%로 나타나 큰 오차를 나타냈다. 또한 전체 작기 데이터를 이용해 개발된 예측모델을 각 재배 작기 데이터에 적용하였을 때 재배 작기별 설명력은 다중회귀분석 –0.17-0.83, 랜덤포레스트 0.23-0.99, 캣부스트 0.42-0.99로 나타나 작기에 따른 차이가 크게 나타났다.
Table 5.
Performance comparison of pepper seedling growth prediction models without including dummy variables.
4. 월별 더미계수를 포함한 생육예측 모델의 비교
월별 더미변수를 포함한 설명변수를 머신러닝 모델에 입력해 고추 유묘 ‘초장’을 예측하고 그 결과를 Table 6를 통해 비교하였다. 월별 더미변수를 포함했을 때 머신러닝 모델의 설명력(R2)은 Table 5에 비해 0.87-0.96으로 개선된 설명력을 보여주었다. 모델 중에서는 캣부스트 모델의 설명력(R2)이 0.96으로 높고 오차율(MAPE)이 13.47%로 가장 낮게 나타났다.
Table 6.
Performance comparison of pepper seedling growth prediction models including dummy variable.
전체 작기 데이터를 이용해 개발된 예측모델을 각 재배 작기 데이터에 적용하였을 때 다중회귀분석의 설명력은 0.49-0.94로 Table 5에 대해 개선된 설명력을 보였으나 역시 재배 작기에 따른 오차율(MAPE)가 79.9%까지 증가하는 등 크게 나타나 작기에 따른 특이값을 잘 반영하지 못하였다. 캣부스트 모델을 활용했을 때 설명력은 0.95-1.00으로 높고 오차율도 0.76-17.18%로 가장 낮게 나타났다.
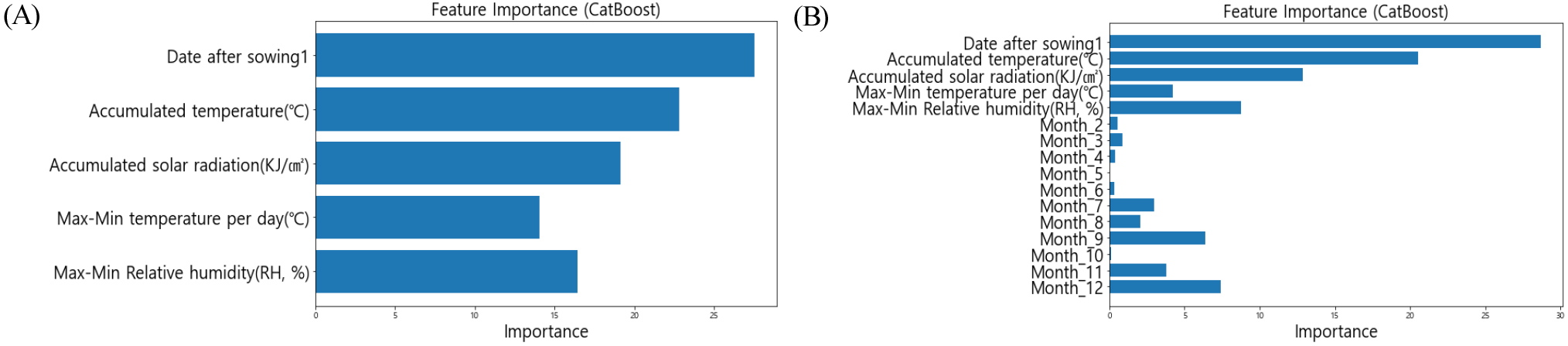
모델에 대한 변수 중요도를 파악하기 위해 더미 변수 여부에 따른 캣부스트 모델의 변수 중요도를 Fig. 3을 통해 비교하였다. 더미 변수가 없는 모델(Fig. 3A)과 더미변수가 포함된 모델(Fig. 3B) 모두 ‘파종이후일수’가 가장 중요한 변수로 나타났으며, 변수 간 중요도의 전반적인 순서는 비슷하게 유지되었다. 그러나 Fig. 3B에서 더미변수를 포함한 모델은 7-9월, 11-12월과 같은 특정 월의 중요도가 상대적으로 높게 나타났다. 이는 더미변수를 통해 모델이 각 월의 고유한 계절적 특성을 학습했음을 의미하며, 여름철과 겨울철 환경이 생육에 미치는 영향을 더욱 명확히 반영한 결과로 볼 수 있다. 변수 중요도에서 더미변수의 영향이 가장 크지 않았으나 더미변수 사용이 예측 과정에서 특정 시기의 환경적 변동성을 보다 효과적으로 포착할 수 있음을 보여준다.
5. 최적 파라미터 선정 및 모델 학습
캣부스트에 사용할 파라미터를 최적화하기 위하여 RandomizedSearchCV를 사용해 파라미터 값을 임의로 선택해 학습과 검증을 진행하였다. 파라미터를 찾기 위해 트리의 깊이(Depth), 학습률(Learning rate), 반복 횟수(Iteration)의 범위를 정해 학습을 진행했을 때 최적 파라미터의 Depth 5, Learning rate 0.13, Iteration 439가 산출되었다. Fig. 4로 이를 시각화 하여 나타냈을 때, MSE가 2.85로 가장 낮게 나타났다.
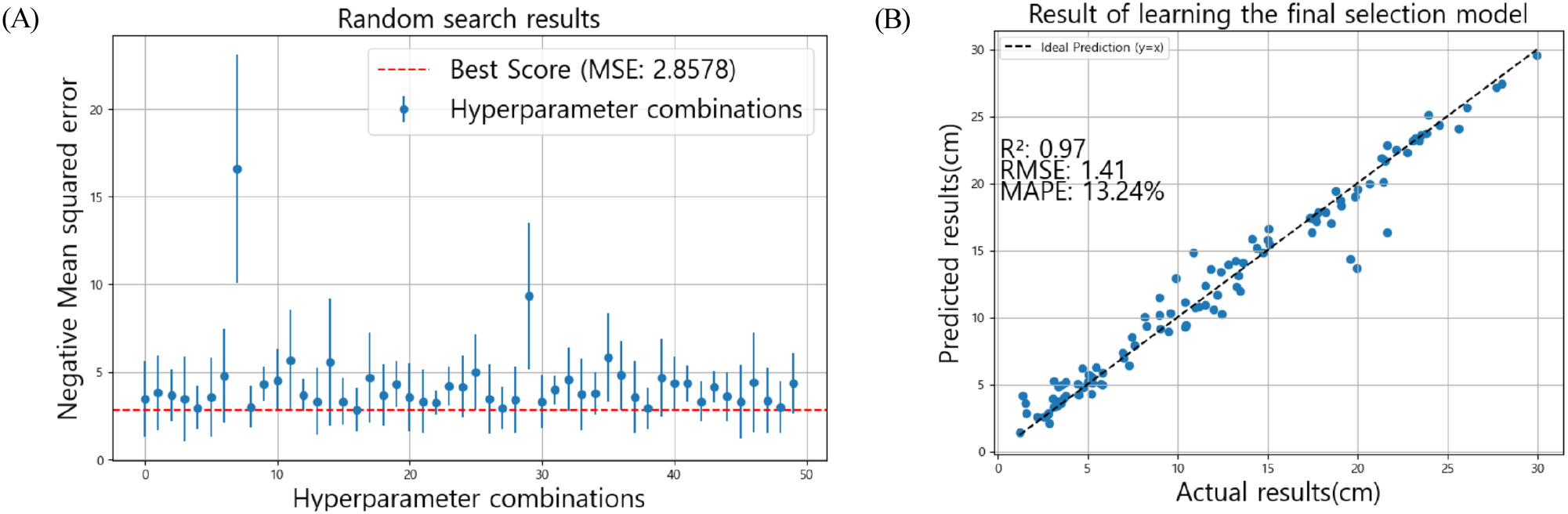
이를 활용해 최적 학습을 진행하였을 때 최종 결과는 설명력(R2)이 0.97, MAPE가 13.24%로 Table 6의 캣부스트 모델의 설명력(R2) 0.96. MAPE 13.47%에 비해 성능이 약간 개선된 결과를 보인다.
고 찰
2021년 9월부터 2023년 12월까지 11회에 걸쳐 계절에 따른 환경과 생육데이터를 수집했을 때 동일한 온실 환경 설정으로 관리하였음에도 단동형 비닐온실의 특성상 계절에 따른 환경 변화와 생육 편차가 발생함을 확인할 수 있었다. 이러한 계절별 생육 편차는 고추 우량묘 생산의 저해 요소이며 재배 농업인의 피해가 발생될 수 있다. 계절에 따라 연중 생산되는 모종의 품질 균일화와 공정화가 필요하며 이를 위해 환경 변화에 따른 생육모델 개발이 필요하다.
시계열 증가 패턴을 보이는 ‘초장’을 주요 예측 지표로 선정하고, 가공된 11개 환경변수 중 변수선택법(RFE)를 활용해 선택된 5개 변수를 선택해 다중회귀분석을 수행한 결과 설명력(R2)은 0.72를 보이나 MAPE가 40.5%로 높았으며, 1-11작기에 적용했을 때 작기별 설명력(R2)은 –0.17-0.83, 오차율(MAPE) 19.2-100.7%로 큰 편차를 보였다. 이에 이상치에 민감하지 않으며 비선형 관계 처리가 가능한 랜덤포레스트, 캣부스트 모델로 생육을 예측하였음에도 랜덤포레스트 0.23-0.99, 캣부스트 0.42-0.99로 작기별 작기별 설명력의 편차는 컸다. 이는 육묘에 필요한 적산온도와 적산일사량에 도달하는 소요 기간과 생장속도가 작기에 따라 다르게 나타나는데 이를 반영하지 못했기 때문으로 판단된다.
이를 보완하기 위해 월별 시계열 변화에 따른 데이터 변동값을 반영할 수 있는 월별 더미변수를 기존 설명변수에 추가하여 예측력을 개선하고자 하였다. 더미변수를 반영한 각 모델의 설명력(R2)은 다중회귀분석 0.87, 랜덤포레스트 0.96, 캣부스트 0.96으로 개선되었으며 캣부스트 활용 모델이 가장 높았다. 각 재배 작기별 설명력(R2) 또한 다중회귀분석 0.49-0.97, 랜덤포레스트 0.94-0.99, 캣부스트 0.95-1.00으로 높아졌고 MAPE은 감소하였다. 이는 더미 변수가 없이 적산온도, 적산일사량 등으로 예측하면 전 작기의 ‘적산온도’라는 값 자체가 묶여서 y를 추정하게 되지만 더미 변수가 포함되면 9월이 0이거나 1일 때, 10월이 0이거나 1일 때 등의 정보가 포함되어 월에 따른 증감 패턴이 반영되기 때문으로 판단된다. 또한 캣부스트을 활용한 모델의 설명력이 가장 높은 것은 본 연구의 설명변수가 범주형 변수(월별 더미변수)와 연속형 변수를 모두 가지고 있기 때문으로 보인다.
향후 이미지를 활용한 육묘 생육 자동 계측에 적용하여 대단위 생육 데이터의 수집과 최적의 생육예측 모델 도출 및 육묘장 정밀환경제어를 위한 기초자료로 활용할 수 있을 것으로 판단된다.
