

서 론
재료 및 방법
1. 데이터 수집 및 전처리
2. FAO 56-PM 공식을 이용한 기준 작물 증발산량 계산
3. 9가지 회귀 알고리즘
4. 모델 평가 방법
결과 및 고찰
1. 모델 예측 분석
2. 최종 모델 선정
3. 모델을 이용하여 계산된 ETo 평가
4. 특징 중요도 분석
서 론
증발산(Evapotranspiration, ETo)은 물 순환의 중요한 구성 요소로, 지표면에서 물이 증발하는 과정과 식물의 기공을 통한 증산 과정이 결합된 현상이다(Allen 등, 2006). 작물의 물 사용은 물 순환에서 주요한 손실 원인 중 하나로, 이는 수문학적, 농업적, 환경적 연구에서 중요한 변수로 작용한다(Djaman 등, 2018). 이러한 이유로 기준 작물 증발산(ETo)을 정확하게 결정하는 것이 중요하며, 이를 위해 다양한 직간접적 방법이 사용되어 왔다. 직접적인 방법으로는 라이시미터(lysimeter)나 증발접시(evaporimeter)를 통한 현장 측정이 있지만(Lu 등, 2018; Parisi 등, 2009), 이러한 방법은 시간 소모가 크고, 에너지 균형 보웬 비율(Bowen ratio) 및 에디 공변량 플럭스(eddy covariance flux) 측정 시스템을 이용한 미세 기상학적 방법은 비용이 많이 들고 복잡하여 널리 적용하는 데 한계가 있다(Drexler 등, 2004).
이러한 한계를 극복하기 위해 물리적, 수학적 공식에 기반한 간접적인 방법이 실용적인 대안으로 채택되었다(Allen 등, 2011). ETo는 온도, 습도, 풍속, 일사량과 같은 여러 기후 요인이 복잡하게 상호작용하는 과정으로, 이를 정확하게 추정하기 위한 데이터가 부족하면 부정확한 결과를 초래할 수 있다(Vyas와 Subbaiah, 2016). 따라서 관측된 기상 데이터를 활용하여 신뢰성 있고 정확한 ETo 추정 모델을 개발하려는 연구가 활발히 진행되었다(Allen 등, 1998; George 등, 2002; Itenfisu 등, 2003). 그 중 Penman-Monteith 방정식(FAO 56-PM)은 완전한 기상 데이터를 활용한 ETo 계산의 표준 방법으로 FAO에서 권장된다(Allen 등, 2006; Smith 등, 1990). 이 방정식은 높은 정확성을 보장하지만, 많은 기상 데이터를 요구한다는 단점이 있어, 일부 지역에서는 이러한 데이터를 확보하는 데 어려움이 있다. 이를 해결하기 위해 데이터 가용성의 문제를 극복하려는 다양한 시도가 이어졌으며(Dai 등, 2009; Ge 등, 2022), 최근 연구에서는 제한된 데이터 세트를 사용하여 ETo를 추정하는 방법으로 역전파 인공 신경망(Backpropagation Neural Networks, BPNN)을 적용하여, 일사량, 최대 온도, 상대 습도 등의 최소한의 기상 데이터를 활용해도 좋은 성능을 보이는 모델을 개발했다(Kim 등, 2019). 하지만 여전히 현장 센서 설치와 같은 물리적 인프라가 필요하고, 이는 관리 및 유지보수의 어려움과 더불어 농촌 지역에서의 통신 취약으로 인해 데이터 수집이 제한될 수 있다는 문제가 있다. 따라서, 본 연구의 목적은 현장 센서 없이 ETo를 계산할 수 있도록 인근 기상청의 데이터를 사용하여 ETo 계산에 필요한 기상 데이터를 예측하는 것이다. 기상청에서 제공하는 시간별 기상 데이터를 입력으로 활용하여 현장 센서 없이 다양한 알고리즘을 통해 평균, 최소 및 최대 온도, 상대 습도, 풍속, 일사량 등을 예측하는 모델을 개발하고, 이를 최적화하여 예측 결과의 신뢰성과 활용 가능성을 평가하는 데 중점을 둔다.
재료 및 방법
1. 데이터 수집 및 전처리
본 연구에서는 대한민국 대전광역시 유성구에 위치한 대전지방기상청(36° 37'19'' N, 127° 37'21'' E, 해발 67.79m)에서 22개의 기상 변수를 수집하였으며, 농업 생산 현장(36° 22'02'' N, 127° 21'12'' E, 해발 47.00m)에 설치된 Smart Weather Sensor(WS500-UMB)를 통해 증발산량 추정에 필요한 6가지 주요 기상 인자, 즉 평균, 최대 및 최소 기온(Tavg, Tmax, Tmin, °C), 상대 습도(RH, %), 풍속(WS, m/s) 및 일사량(SI, W/m2) 데이터를 수집하였다. 지리적인 거리의 경우 직선거리로 1.72km이며, 기상환경적 차이의 경우 농업생산현장은 평지이며, 대전지방기상청의 경우 산 중턱에 위치해 약 20m 정도의 해발고도가 차이가 있고, 산 하나를 사이에 두고 있어 기상청과 농업생산현장에는 일사와 풍속에서 차이가 발생한다.
모든 데이터는 2023년 1월 1일부터 2024년 8월 26일까지 수집되었으며, 센서 오작동으로 인해 발생한 오류 데이터는 제거하였다. 시간 단위 FAO 56-PM 공식을 적용하기 위해 1시간 단위 데이터가 필요했으므로, 기상청 데이터는 1시간 단위로 수집하였고, 센서 데이터는 2분 간격으로 측정된 기상 인자 중 일사량을 제외한 나머지 변수를 1시간 단위 평균으로 통합하였다. 온도의 경우 1시간 단위로 최대 및 최소값을 계산하였고, 일사량은 1시간마다 누적한 후 W/m2 단위를 MJ로 변환하였다(Allen 등, 1998).
기상 데이터는 시간에 따른 변화를 포함하는 시계열 데이터이기 때문에, 머신러닝에 활용하기 위해 시간 관련 정보인 날짜 열은 제거하였다. 22개의 입력 변수 중 범주형 데이터인 운형 데이터에 대해서는 라벨 인코딩(Label Encoding)을 적용하여 수치형 데이터로 변환하였다. 이렇게 전처리된 데이터를 무작위로 8:2 비율로 훈련 세트와 테스트 세트로 나누었으며, 모델평가 및 성능 향상을 위한 학습에는 동일한 데이터셋이 사용되어야 하므로 매 훈련마다 random state를 42로 고정하였다. 과적합 방지를 위해 모든 학습에서 5번의 교차검증을 시행하였습니다. 모델에 사용된 입력 데이터(기상청 값)와 결과 데이터(센서 값)에 대한 약어와 설명, 훈련 세트와 테스트 세트에서 각 기상데이터의 범위는 Table 1과 같다.
Table 1.
Description and range of 22 input data points collected from the Korea Meteorological Administration and 6 output data points collected from field sensors.
모든 전처리 작업과 모델 훈련은 Python을 사용하였으며, 데이터 간의 크기가 예측에 미치는 영향을 제거하기 위해 Python에서 제공하는 StandardScaler 라이브러리를 사용하여 표준화하였다. StandardScaler에 적용된 공식은 다음과 같다.
는 표준화된 값이고, 는 원본 데이터이다. 는 원본 데이터의 평균이며, 는 원본 데이터의 분산이다.
2. FAO 56-PM 공식을 이용한 기준 작물 증발산량 계산
FAO 56-PM 공식은 토양 표면에서의 증발과 작물 잎에서의 증산을 계산하여 손실되는 물의 양을 정량화하기 위해 개발되었다. 이 공식을 사용하여 추정한 기준 증발산량은 6가지 기상인자(Tavg, Tmax, Tmin, RH, WS 및 SI)를 입력값으로 필요로 하며, 이는 기준 작물인 잔디에 대한 증발산량이며 공식은 다음과 같다(Allen 등, 1998):
여기서 ETo는 기준 작물 증발산량[mm hour-1], Rn은 작물 표면의 순 복사량[MJ m-2 hour-1], G는 토양 열 유속 밀도[MJ m-2 hour-1], T는 2m 높이에서의 평균 일일 기온[°C], u2는 2m 높이에서의 풍속[m s-1], es는 포화 수증기압[kPa], ea는 실제 수증기압[kPa], es – ea는 포화 수증기압 차[kPa], Δ는 경사 수증기압 곡선[kPa °C-1], γ는 건습계 상수[kPa °C-1]이다.
3. 9가지 회귀 알고리즘
기상인자를 예측하기 위한 알고리즘으로 총 9가지 회귀모델을 선정하고(Table 2), 평가방법에 따라 성능을 비교하였다(Table 3). 모델 선정 방법은 온실에서 ETo를 예측하는 연구에서 8가지 회귀 모델을 사용하였으며, 전반적으로 높은 성능을 보였으며, 가장 높은 성능을 보인 모델은 XGBoost 모델이었다(Ge 등, 2022). 따라서 본 연구에서는 트리 기반 모델에 속하는 3가지 모델과 부스팅 기법을 사용한 모델 2가지, 기본 모델인 선형 회귀 모델, 인공 신경망 모델인 다층 퍼셉트론 모델 및 이전 연구에서 사용한 모델 일부를 사용하였다. 딥러닝의 경우 비교적 많은 데이터가 필요하며, 기상인자의 경우 시계열 데이터로 분류되기 때문에 순환 신경망 계열의 모델을 사용해야 되나, 데이터 양의 문제 및 필요한 비용 측면의 문제를 고려하여 머신러닝 모델로만 선정하였다.
Table 2.
Characteristics of nine models used to predict meteorological factors.
| Model | Description | Reference |
| Linear Regression (LR) |
• Suitable for modeling linear relationships • Simple and easy to interpret • Fast and efficient • Limited flexibility and sensitive to outliers | Montgomery et al., 2021 |
|
Decision Tree Regression (DTR) |
• Simple and easy to interpret • Can handle both categorical and numeric data • Vulnerable to overfitting • Sensitive to data changes | Loh et al., 2011 |
|
Random Forest Regression (RFR) |
• Ensemble model of multiple decision trees • Bootstrap Aggregation (Bagging) method • Robust to overfittiong • Slow and difficult to interpret when processing large datasets compared to individual trees. | Breiman et al., 2001 |
|
Gradient Boosting Regression (GBR) |
• Boosting method • High-accuracy boosting model that sequentially minimizes residual errors • Computationally intensive and requires careful hyperparameter tuning | Friedman et al., 2001 |
| XGBost Regression (XGBR) |
• Boosting method • Effectively handle missing data • An efficient and scalable boosting algorithm that includes regularization to reduce over fitting. • Requires computational resources and careful hyperparameter tuning to improve performance | Chen et al., 2016 |
| AdaBoost Regression (ABR) |
• Boosting algorithm that improves accuracy by repeatedly • combining weak learners. • Sensitive to noise and needs careful tunning to balance adaptability and robustness. | Freund et al., 1997 |
|
K Neighbors Regression (KNR) |
• A simple, intuitive, non-parametric algorithm ideal for small datasets. • Predictions based on proximity • Computationally expensive on large datasets and sensitive to feature scaling. | Hastie et al., 1995 |
| Support Vector Regression (SVR) |
• Effective for high-dimensional data • Capable of kernel functions and nonlinear data processing • Can be computationally expensive and requires expert knowledge in kernel selection for optimal results | Cortes, 1995 |
|
Multi-Layer Perceptron Rgression (MLPR) |
• Neural network models are excellent for modeling complex no nlinear relationships in large datasets. • High computational cost and regularization required to prevent overfitting | Rumelhart et al., 1986 |
Table 3.
Performance evaluation of weather factor prediction using various machine learning algorithms.
4. 모델 평가 방법
평균 제곱 오차(MSE), 평균 제곱근 오차(RMSE), 평균 절대 오차(MAE), 및 결정 계수(R2)가 모델의 정확도를 평가하는데 사용되었다. MSE, RMSE, MAE 값은 낮을수록 예측 정확도가 높음을 나타낸다. 일반적으로 각 오차에 대한 지표를 사용하여 모델의 성능을 높이는 방향성을 결정하거나 모델 선택의 지표로 사용한다. MSE는 예측값과 실제값 사이의 오차를 제곱한 값의 평균으로, 오차를 제곱하기 때문에 이상치가 있는 경우 에러가 크게 측정되는 경향이 있어 이상치가 중요한 작업의 경우 유용하다. RMSE는 MSE에 루트를 씌운 값으로 데이터 단위로 결과를 변환시켜주기 때문에 직관적으로 해석할 수 있도록 변환한다. MAE는 예측값과 실제값 사이의 절대 오차의 평균으로 절대값을 취하기 때문에 오차 크기를 평균적으로 측정할 수 있다. 큰 오차에 민감하지 않아 안정적인 지표로 사용되며, MSE, RMSE와 달리 이상치에 덜 민감하다는 특징이 있어 이상치가 많을 때 주로 사용한다. R2는 모델의 예측 값과 측정 값 사이의 적합도를 나타내며, 값이 1에 가까우면 모델이 잘 맞다는 것을 의미한다(Chipanshi 등, 2015; Hara 등, 2021; Suntaranont, 2020). 방정식은 다음과 같다.
결과 및 고찰
1. 모델 예측 분석
기상청 데이터의 22개 변수를 이용하여 농업현장에서 기준 작물 증발산량 산출을 위한 기상센서의 6가지 기상인자를 예측하고, 최적의 모델을 찾기 위해 9개의 회귀 알고리즘을 선택했다. 9개의 알고리즘은 XGBR, LR, DTR, SVR, KNR, RFR, ABR, GBR, MLPR이다. 각 알고리즘을 이용한 성능평가 결과는 XGBR가 가장 좋았다(Table 3). 온도의 경우 모든 모델에서 높은 성능을 보였으며, 선형 회귀 모델에서 높은 성능을 보인 것은 온도가 특정 변수와 선형적인 상관관계가 높을 것으로 사료된다. 풍속은 전체적으로 낮은 성능을 보였으나, 앙상블 기반의 모델인 XGBR, RFR 모델에서 비교적 높은 성능을 보였다. 이는 풍속 예측에 복잡한 모델이 유효함을 시사한다.
2. 최종 모델 선정
모든 모델에서 풍속의 예측 정확도가 비교적 낮았기 때문에 풍속의 R2 값을 기준으로 상위 3개의 모델을 선정했다. 선정된 모델들은 Python 라이브러리인 GridSearch를 사용해 최적화했으며, 모델 간의 예측 정확도를 비교한 후 최종 모델을 선택했다(Table 4). 가장 높은 정확도를 보인 모델은 XGBR로, 최적의 하이퍼파라미터는 Table 5에 나와 있다. 최종 선택된 XGBR 모델은 평균온도(0.98), 최대온도(0.99), 최소온도(0.99), 습도(0.91), 일사량(0.86)에서 높은 결정계수를 보였으며, 풍속의 경우 예측은 가능했으나 0.72로 상대적으로 낮았다. 이는 풍속이 2m 높이에서 측정되기 때문에 지형 및 지리적 요인에 많은 영향을 받으며, 인근 지역 변수만으로는 예측 성능이 낮은 것으로 사료된다(Fig. 1). 오차를 나타내는 MSE, RMSE, MAE에서도 동일하게 모든 XGBR 모델이 가장 좋은 결과를 보였다(Table 6). 따라서 모델이 종속 변수의 변동성을 설명하는 정도(R2)와 평균적인 오차 정도(MAE), 이상치에 민감한 오차 정도(RMSE) 모두 XGBR 모델이 가장 뛰어났다.
Table 4.
GridSearch hyperparameter ranges for the top 3 models.
Table 5.
Optimal hyperparameters for meteorological factors in the XGBR model.
Table 6.
Performance evaluation of optimized machine learning models for weather factor prediction.
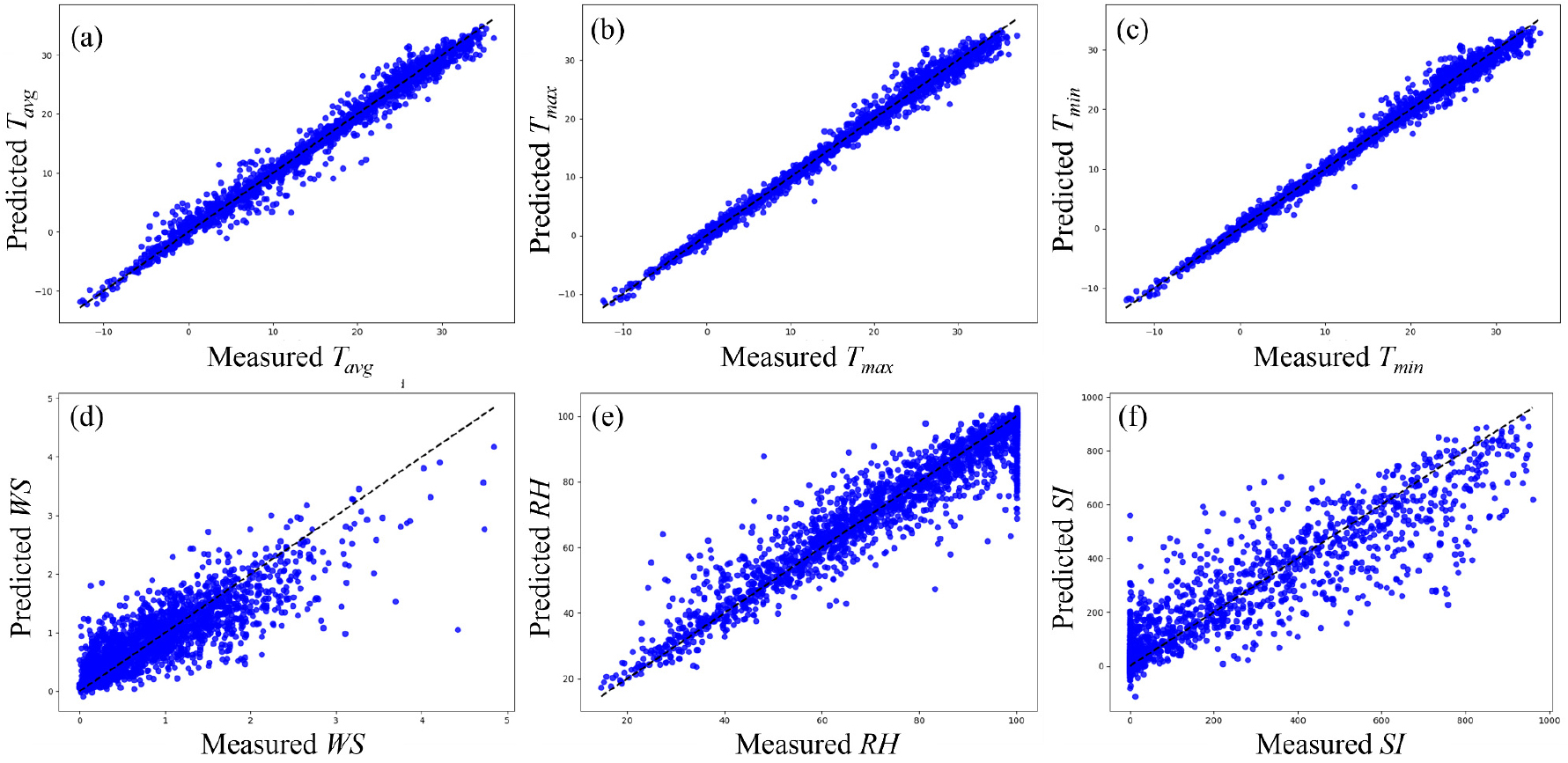
Fig. 1
Fitting results of meteorological factors predicted by the XGBR model. (a) Fitting results of measured Tavg and predicted Tavg, and (b) Fitting results of measured Tmax and predicted Tmax, and (c) Fitting results of measured Tmin and predicted Tmin, and (d) Fitting results of measured WS and predicted WS, and (e) Fitting results of measured RH and predicted RH, and (f) Fitting results of measured SI and predicted SI.
3. 모델을 이용하여 계산된 ETo 평가
XGBR 모델의 성능 평가를 위해 ETo를 기준으로 평가하였다. 평가방법은 현장센서 데이터 기반 증발산량(실제 증발산량), XGBR 모델로 예측한 데이터 기반 증발산량(예측 증발산량)과 기상청 데이터 기반 증발산량(기상청 증발산량)을 시간별 값, 테스트 기간동안 누적된 값을 비교하였으며, 기상인자별 하나씩 예측 값을 사용한 증발산량 결과로 기상인자별 증발산량 계산에 미치는 기여도를 분석하였다.
1시간 단위 기준 증발산량 산정에는 최소온도와 최대온도 대신 평균온도에서 산출한 값을 사용하므로 증발산량 계산에는 1시간 단위 평균온도, 상대습도, 일사량, 풍속 4가지 데이터를 사용하였다. 검증 데이터로 2024년 9월 1일부터 14일까지의 기상청 데이터와 센서 데이터를 수집하였다. 1시간 단위 데이터를 2주 간 수집하였기 때문에 336개의 결과가 생성되며, 일사가 0MJ/m2이 되는 시간대(야간)는 ETo 값이 음수가 되고, 관수를 하지 않기 때문에 해당 시간대를 제외한 163개의 데이터를 사용하였다.
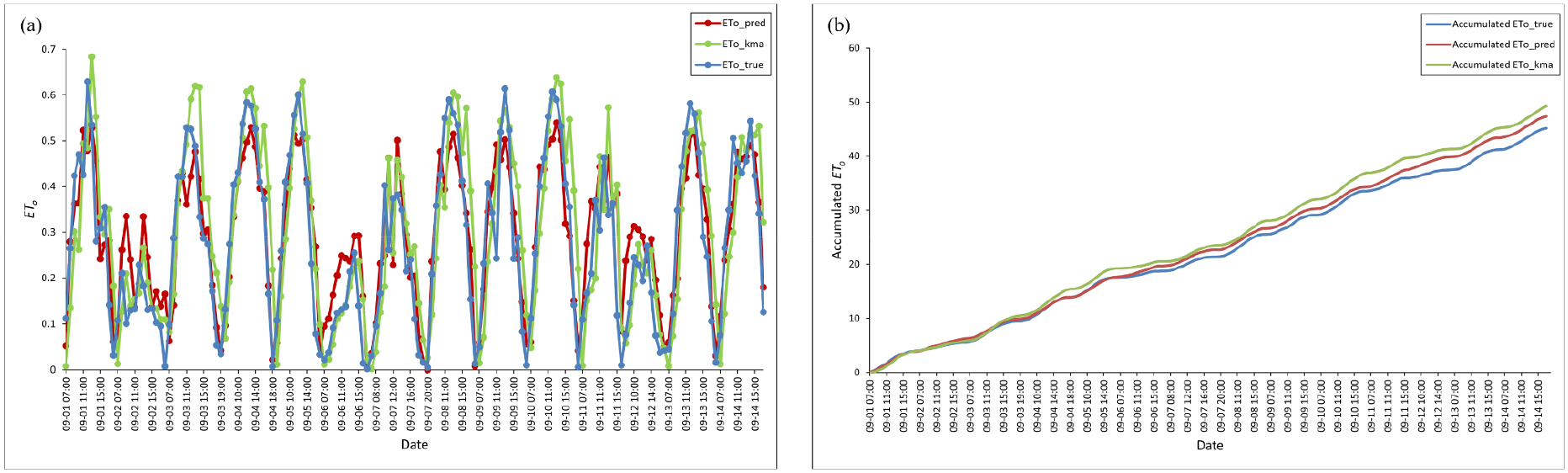
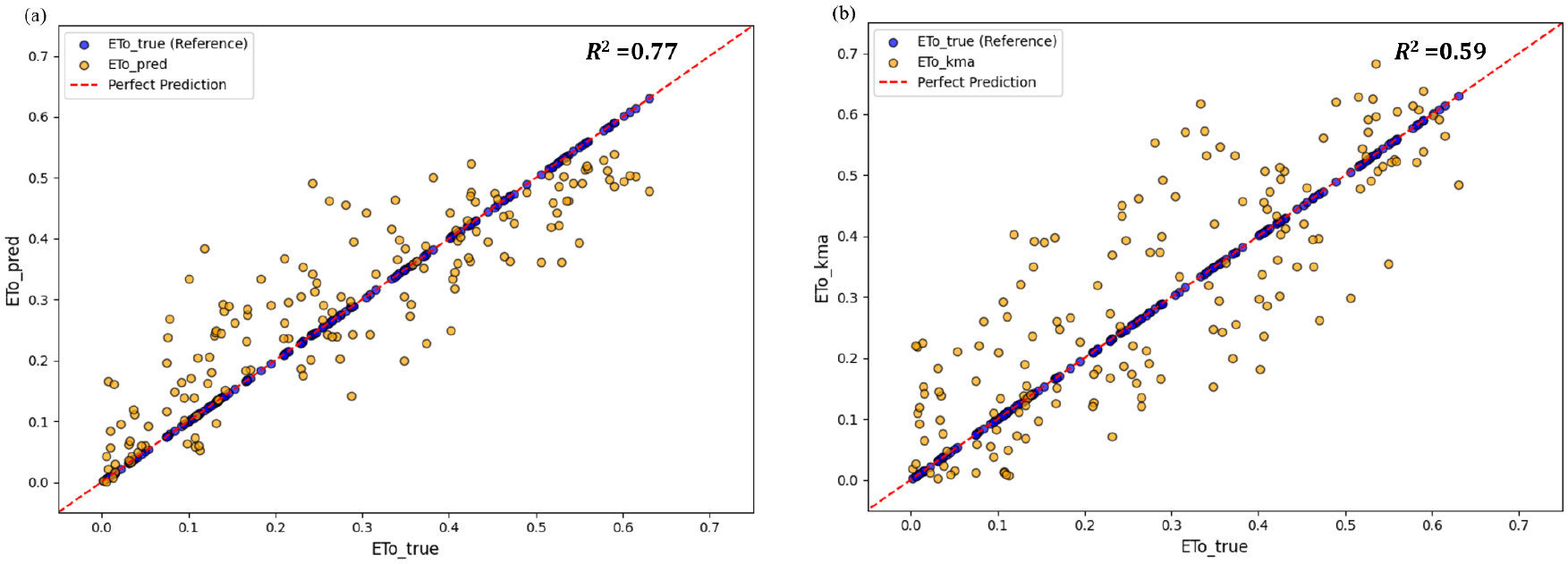
시간별 실제, 예측, 기상청 증발산량 간의 경향성은 비슷하였으나(Fig. 2a), 실제 값 대비 2주 동안 누적된 증발산량의 오차는 예측 증발산량이 2.2L·m-2, 기상청 증발산량이 4.1L·m-2로 모델이 예측한 결과가 기상청 대비 46.3%만큼 작은 오차를 나타냈다(Fig. 2b). 선형 회귀를 통해 실제 증발산량에 얼마나 적합한지 확인한 결과 예측 증발산량이 더 높은 적합도를 보였다(Fig. 3).
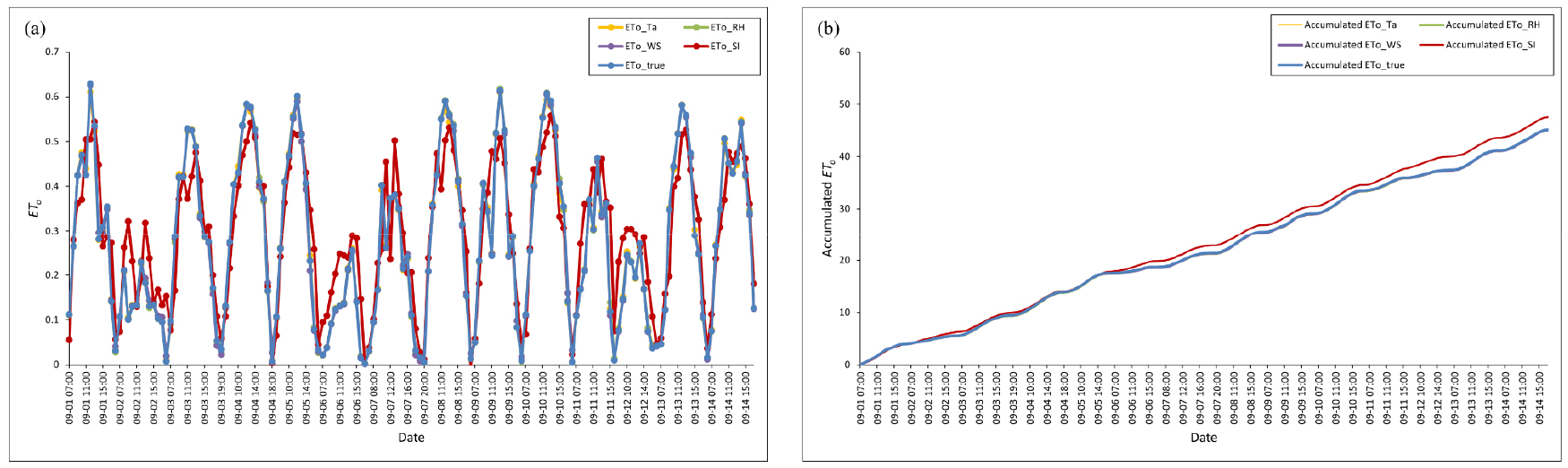
예측 증발산량의 오차에 영향을 미치는 기상인자를 확인하기 위해 각 기상인자별 하나씩 예측값을 사용했을 때 시간별, 누적 그래프에서 일사량을 제외한 3가지 인자는 경향성에서 큰 차이가 없었다(Fig. 4). 오차에서도 온도(0.1L·m-2), 상대습도(0.1L·m-2), 풍속(0.1L·m-2)을 예측값으로 사용한 증발산량은 매우 낮았으나 일사량(2.4L·m-2)을 예측값으로 사용한 증발산량은 큰 차이를 보였으며, 선형 회귀에도 동일한 결과로 나타났다(Fig. 5). 이 결과는 기상인자 중 일사량이 가장 높은 상관 관계를 보이며, 다른 기상인자에 비해 PM 방정식에서 선형적으로 반영되기 때문으로 판단된다(Ge 등, 2022). 또한, 일사량은 시간, 계절, 날씨 조건에 따라 변동 폭이 큰 반면, 평균온도나 상대습도는 일반적으로 비교적 안정적이기 때문에 ETo 변화에 영향이 적은 것으로 사료된다. 결과적으로, R2 값은 풍속에서 가장 낮게 나타났으나, 예측 오차 범위와 Penman-Monteith 방정식에 따른 계산 결과, 일사량이 증발산량에 가장 큰 영향을 미치는 변수로 확인되었다. 따라서 증발산량 계산의 정확도를 높이기 위해서는 일사량 데이터의 신뢰성과 정확성을 개선하는 것이 가장 중요할 것으로 판단된다.

4. 특징 중요도 분석
높은 정확도를 보인 모델 중 특징 중요도를 제공하는 XGBR 모델의 학습 시 중요도를 확인하였다(Fig. 2). XGBoost 모델과 같은 트리 기반 머신러닝 모델은 특징 중요도라고 하는 대상 변수에 대한 입력 변수의 중요성을 계산하는 특수 기능을 제공한다. 특징 중요도를 확인함으로써 목표를 예측할 때, 어떤 변수가 가장 큰 영향력을 발휘했는지를 상대적 지표로 나타내며, 이는 특성공학 등을 통해 예측 성능을 높이는 자료로 사용하거나, 모델의 결과를 해석하는 데 사용한다. 결과를 보면, 온도를 예측할 때 기상청 온도인 TA 변수가 압도적으로 높은 영향력을 보였다. 상대 습도는 기상청 상대습도인 HM와 일조시간인 SS, 3시간 적설량인 SD, 강수량인 RN 변수, 일사량은 SD와 기상청 일사량인 SI, 적설량인 SD.2 변수가 높은 중요도를 보였다. 풍속은 SS와 기상청 풍속인 WS 변수를 포함한 다양한 변수에서 높은 중요도를 보였다(Fig. 6).
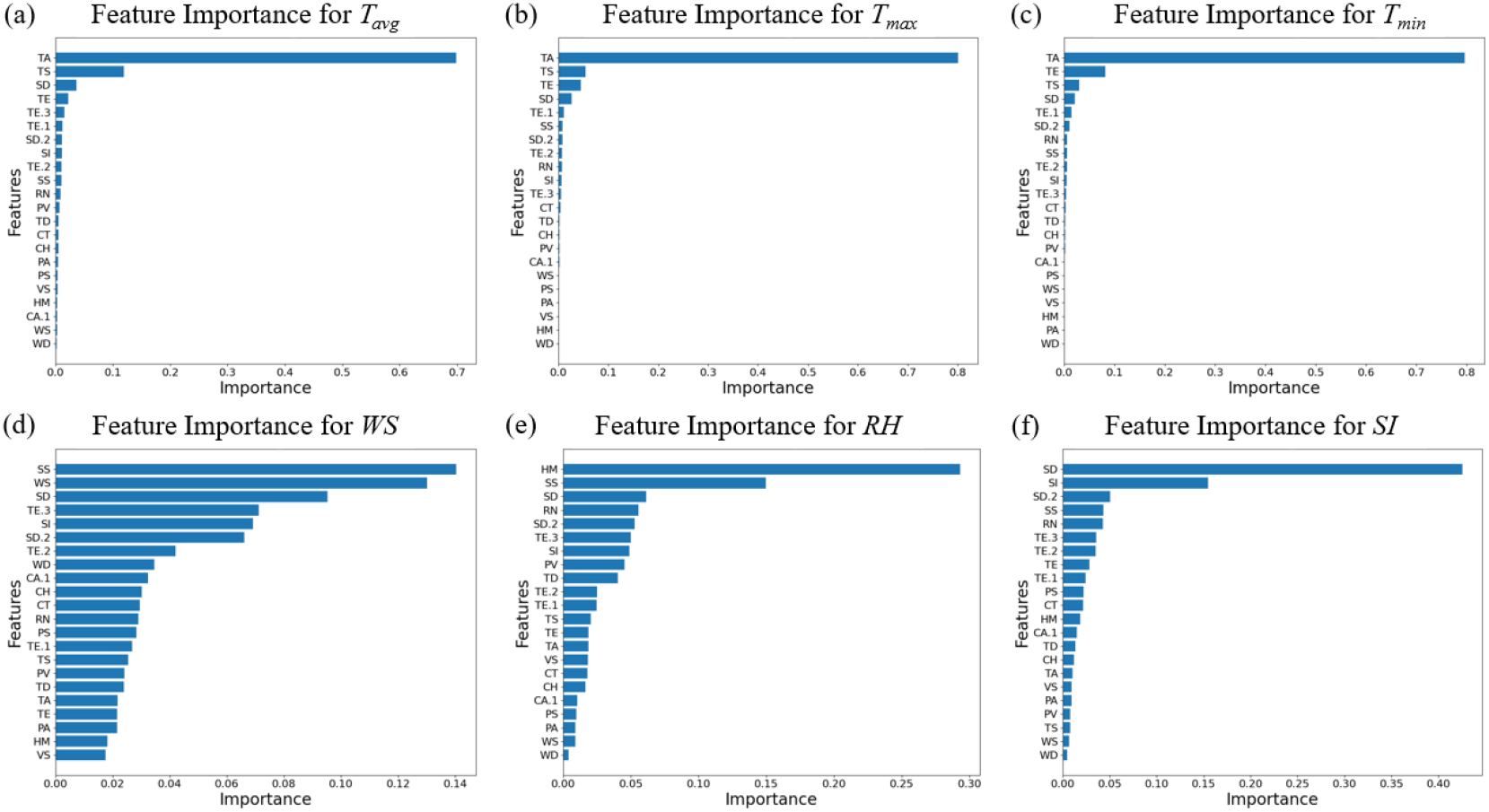
Fig. 6
Feature importance of input data of XGBR model. (a) Feature importance for predicting Tavg, and (b) Feature importance for predicting Tmax, and (c) Feature importance for predicting Tmin, and (d) Feature importance for predicting WS, and (e) Feature importance for predicting RH, and (f) Feature importance for predicting SI.
모든 인자에서 해당 인자와 관련된 변수가 특징 중요도에서 높은 중요도를 보이는 것을 확인할 수 있었다. 각 요인의 중요도를 살펴보면, 온도 관련 인자들은 지형 및 지물의 영향을 거의 받지 않기 때문에 기상청의 온도 요인과 지역의 온도 요인이 매우 높은 연관성을 보였으며 높은 예측 성능을 나타내었다. 일사량의 경우 3시간 적설량과 기상청 일사량이 높은 중요도를 보였는데, 이는 일사량인 직접적인 변수인 기상청 일사량 뿐만 아니라 3시간 적설량과 같은 변수들이 흐린 날씨의 특징을 간접적으로 표현하여 모델의 정확도에 영향을 미쳤을 것으로 판단된다. 상대습도는 기상청 상대습도가 가장 높은 중요도를 보였으며 다음으로 일조시간, 3시간 적설량, 강수량이 중요했는데 이는 상대습도에 간접적으로 영향을 미치는 요인이기 때문으로 사료된다. 풍속의 경우 가장 다양한 변수들이 비슷한 영향을 미쳤는데, 이는 풍속의 경향성이 비선형적이면서, 지형지물 등 요인의 영향을 가장 많이 받기 때문에 예측하기 어려워서 나타나는 현상으로 판단된다. 따라서 풍속 예측에는 복잡한 모델의 정확도가 높을 수 있다는 것을 나타내며, 스태킹 기법과 같은 더 다양한 모델링 기법이나 특성공학을 통한 변수창출을 통해 더 높은 성능을 기대할 수 있을 것으로 사료된다.
