

서 론
재료 및 방법
1. 데이터셋 구축
2. CLIP(Contrastive Language-Image Pre-training)
3. Grounding DINO
4. SAM(Segmentation Anything Model)과 SAM3
5. SAM3 기반 어노테이션 시스템 설계 및 구현
6. 세그멘테이션 모델 및 평가 파이프라인
7. 평가 지표
결과 및 고찰
1. 텍스트 기반 세그멘테이션 모델 비교 평가
2. SAM3 기반 반자동 어노테이션 시스템 개발 및 적용
고 찰
서 론
컴퓨터 비전(Computer Vision) 기술은 농작물의 이미지를 기반으로 생육 상태 평가, 질병 진단, 수확량 추정이 가능함을 보여주었으며, 최근에는 딥러닝 기반 이미지 분석 기술의 발전으로 실시간 생육 모니터링, 질병 조기 진단, 수확량 정밀 추정이 가능해지면서 농업 현장에서의 실용성이 크게 향상되고 있다(Choi et al., 2022; Ghazal et al., 2024; Yoon et al., 2024). 이러한 기술 발전은 노동력 의존도가 높은 농업 현장에서 작물 관리의 효율성과 객관성을 제고할 수 있는 대안으로 주목받고 있으며(Kamilaris and Prenafeta-Boldú, 2018), 특히 생육 변화에 대한 지속적인 모니터링과 관리 의사결정이 요구되는 작물에서는, 영상 기반 자동 모니터링 기술의 필요성이 더욱 크다(Li et al., 2020).
느타리버섯(Pleurotus ostreatus)은 단일 균사체로부터 다수의 자실체가 동시에 발생하는 다발형 식용버섯으로, 개체별 크기와 형태의 변이가 크고 생장 속도가 매우 빠른 특성을 가진다(Sánchez, 2010; Royse et al., 2017). 국내 느타리버섯 재배는 병재배(bottle cultivation)를 기반으로 한 밀폐형 재배사에서 이루어지며, 다단 적재 구조를 통한 고밀도 생산 방식으로 연중 안정적인 생산이 가능하다(Lee et al., 2015; Lee et al., 2019). 그러나 버섯의 빠른 생육 속도와 고밀도 군집 구조로 인해 하루 이틀 사이에 수확 적기를 놓칠 경우 상품성이 급격히 저하되기 때문에(Ahmed et al., 2025; Guragain et al., 2025), 숙련 작업자의 지속적인 관리가 요구된다(Taupa et al., 2024). 수천 개의 병이 동시에 입병되는 버섯 스마트팜 환경에서는 기존 숙련 인력 중심의 목측 관리 방식의 한계가 지적되고 있으며, 디지털 기술을 활용한 인공지능 기반 모니터링 기술의 도입이 필요하다(KISTI, 2019; Charisis et al., 2025).
영상 기반 딥러닝 기술의 예측 정확도 향상 및 현장 실증을 위해서는 재배 환경을 정확히 반영한 고품질 객체 분할 학습데이터의 확보가 선행되어야 한다. 학습데이터는 양적으로 충분한 이미지 수를 확보하는 것뿐만 아니라, 질적으로 객체의 위치와 형태를 정확히 기술한 어노테이션(annotation) 정보가 필수적이다(Lin et al., 2014; Silva et al., 2024). 그러나 어노테이션은 숙련된 인적 자원과 막대한 시간 및 비용을 요구하는 작업으로서 농업용 AI 모델 과정의 주요 병목으로 지적되고 있다(Koirala et al., 2019). 느타리버섯은 자실체가 고밀도로 중첩된 형태적 특성으로 인해 객체 분할 과정에서 높은 수준의 수작업 개입이 요구되며, 마스크 생성 이후에도 각 객체에 대한 추가적인 어노테이션 작업이 필요하다. 이러한 절차는 어노테이션 과정의 복잡도를 증가시키고, 인적 오류 발생 가능성을 높여 학습데이터 품질에 부정적인 영향을 미칠 수 있다. YOLO(Redmon et al., 2016)나 Mask R-CNN(He et al., 2017)과 같은 객체 검출 및 인스턴스 세그멘테이션 모델은 높은 성능에도 불구하고 대규모 정답 레이블(ground Truth) 데이터가 필수적이라는 한계를 가진다. 이로 인해 데이터 희소성 문제는 농업용 AI 모델의 범용성과 확장성을 제한하는 구조적 요인으로 지속적으로 보고되고 있다 (Kamilaris and Prenafeta-Boldú, 2018; Yin et al., 2025). 이에 농업 환경에서도 신뢰성 있는 세그멘테이션 학습데이터를 자동으로 생성할 수 있는 방법론과 도구에 대한 연구가 필요하다.
최근 어노테이션 데이터 구축과정의 병목 현상을 해결하기 위해 파운데이션 모델을 활용한 반자동 레이블링 접근법이 주목받고 있다. 대규모 데이터로 사전 학습된 파운데이션 모델(pre-trained foundation models)은 이러한 한계를 극복할 수 있는 대안으로 제시되고 있다(Mazurowski et al., 2023). 이미지에서 객체를 추출하기 위해 텍스트로부터 의미 정보를 활용하는 CLIP(Radford et al., 2021).
LSeg(Li et al., 2022), Grounding DINO(Liu et al., 2024) 등의 모델이 제안되었으며, 이후 이미지 세그멘테이션 성능이 우수한 SAM(Kirillov et al., 2023)과 결합하는 연구가 활발히 이루어졌다. 그러나 SAM+CLIP 방식은 CLIP이 이미지 전체 수준의 시각-언어 정합에 기반하여 학습되었기 때문에, 지역 단위의 세밀한 객체 표현을 충분히 반영하지 못해 작고 밀집된 객체 환경에서 성능 저하를 보였다(Zhong et al., 2022). Grounding DINO+SAM 조합은 우수한 성능을 보였으나, 2단계 추론 구조로 인한 처리 속도 저하와 복잡한 배경에서의 위양성(false positive) 문제가 보고되었다(Mumuni et al., 2024). 또한 텍스트 프롬프트를 직접 지원하지 않아 별도의 검출 모델과 결합해야만 완전한 자동화가 가능하다는 점은 시스템의 복잡도를 높이는 요인이었다. 이러한 한계를 극복하고 다단계 파이프라인의 복잡성을 해소하며 멀티모달 이해 능력을 강화하기 위해, 최근 SAM3(Segment Anything Model 3)가 제안되었다. SAM3는 기존 SAM의 강력한 분할 성능에 시각-언어 모델의 이해력을 단일 아키텍처로 통합한 모델로, 별도의 검출기 없이도 텍스트 프롬프트를 통해 특정 개념을 직접 이해하고 분할할 수 있다(Carion et al., 2025).
본 연구는 객체 밀집도가 높고 형태적 변이가 큰 비정형 작물 영상에서 어노테이션 데이터 구축 과정의 병목을 해결하고, 레이블링 효율을 극대화할 수 있는 반자동 학습데이터 생성 시스템을 개발하는 것을 목표로 하였다. 느타리버섯 재배 환경에서 획득한 영상 데이터를 대상으로 SAM+CLIP, SAM2+CLIP, Grounding DINO+SAM, SAM3의 성능을 비교 분석하고, 그 결과를 바탕으로 SAM3 기반 텍스트 유도형 어노테이션 시스템을 설계하여 GUI 프로그램으로 구현하였다. 이를 통해 농업 분야의 다양한 비정형 객체 데이터셋 구축 자동화 가능성을 실증적으로 제시하고자 한다.
재료 및 방법
1. 데이터셋 구축
본 연구에서는 느타리버섯의 갓 부위에 대한 분할 어노테이션 효율을 향상시키기 위해, 실내 환경에서 촬영한 이미지 기반의 데이터셋을 구축하였다(Fig. 1). 데이터는 총 600장의 RGB 이미지로 구성되며, 각 이미지는 1080×1920의 고해상도로 획득하였다. 모든 이미지는 버섯 배지 상부에서 수직 하향 방향으로 촬영하였으며, 조명, 촬영 거리, 배경 등의 촬영 파라미터를 일정하게 유지하여 데이터의 일관성을 확보하였다. 분할 대상은 느타리버섯의 갓 영역으로 정의하였으며, 대(Stipe) 및 배지 배경은 제외하였다. 정답(Ground Truth) 마스크는 LabelMe 소프트웨어(Russell et al., 2008)를 사용하여 생성하였다. 작업자는 각 이미지에서 느타리버섯 자실체를 객체 단위로 구분한 뒤, 객체의 외곽 경계를 폴리곤으로 직접 지정하여 픽셀 단위 분할 마스크를 구축하였다. 어노테이션 품질을 위해 객체 정의 및 경계 기준을 사전에 통일하였으며, 작업자 간 일관성 확보를 위해 샘플 이미지를 상호 교차 검증하였다. 검증 과정에서 불일치가 확인된 객체는 재검토 후 합의된 기준으로 수정하여 최종 정답 마스크로 확정하였다.

2. CLIP(Contrastive Language-Image Pre-training)
OpenAI의 CLIP(Contrastive Language-Image Pre-training)은 텍스트와 이미지 간의 의미적 관계를 공동 임베딩 공간에서 정합되도록 대조 학습(contrastive learning) 방식으로 학습함으로써, 제로샷 분류(Zero-shot Classification)가 가능한 모델로서 별도의 재학습 없이도 새로운 객체를 인식할 수 있는 특징을 가진다(Radford et al., 2021). CLIP 모델을 기반으로 이미지와 텍스트를 동시에 입력하면, 추가적인 학습 데이터 없이도 이미지 내에서 텍스트에 해당하는 객체를 분류할 수 있는 실용적인 도구들이 제안되었다(Gao et al., 2024). 이러한 CLIP 기반 어노테이션 도구는 사용이 간편하고 이미지 전체 수준의 분류 성능은 우수한 반면, 모델 구조상 지역 단위의 시각적 특징을 명시적으로 학습하지 않기 때문에 이미지 내 객체의 정확한 위치를 식별하기 위한 픽셀 단위의 공간적 해상도(spatial resolution)가 제한적이다. 이로 인해 CLIP 단독으로는 객체 경계 정보를 요구하는 정밀한 세그멘테이션 작업에 직접 적용하기에는 구조적 제약이 존재한다(Rao et al., 2022).
3. Grounding DINO
Grounding DINO는 텍스트 기반 객체 검출(text-guided object detection)을 지원하는 파운데이션 모델로, 농업 데이터 어노테이션의 자동화를 위한 유망한 접근법으로 부상하였다. 텍스트 프롬프트를 통해 이미지 내에서 해당 의미적 특징을 가진 영역을 찾아 바운딩 박스(Bounding Box)를 생성한다(Liu et al., 2024). 수천 장의 작물 이미지에서 객체마다 수동으로 박스를 지정해야 했던 기존 방식에 비해, 텍스트 프롬프트로 1차 자동 어노테이션 후 검수 중심의 효율적인 어노테이션 파이프라인 구축이 가능해졌다. 특히 복잡한 배경 속에서 특정 작물 부위만을 검출하는 데 탁월한 성능을 보이며, SAM과의 결합을 통해 Grounded-SAM 파이프라인으로 발전하였다(Singh et al., 2025). 해당 파이프라인에서는 Grounding DINO가 텍스트 기반 객체 검출을 통해 관심 영역을 사전에 제한하고, 이후 SAM이 해당 영역 내에서 정밀한 인스턴스 세그멘테이션을 수행함으로써, 텍스트 유도형 분할 자동화를 구현한다. 이 조합은 객체 위치 검출과 세그멘테이션을 단계적으로 수행하는 방식으로, 복잡한 농업 환경에서 비교적 안정적인 성능을 제공하지만, 다단계 추론 구조로 인한 처리 속도 저하와 시스템 복잡도 증가라는 한계도 함께 지닌다.
4. SAM(Segmentation Anything Model)과 SAM3
2023년 Meta AI가 공개한 SAM(Segment Anything Model)은 11억 개의 마스크로 구성된 SA-1B 데이터셋으로 학습되어 강력한 제로샷 일반화 성능을 보여주었다(Kirillov et al., 2023). 오픈소스 커뮤니티에서는 SAM을 활용한 웹 기반 어노테이션 도구인 ‘Segment Anything Annotator’ 등이 개발되어, 기존의 수동 폴리곤 그리기 방식을 클릭 중심의 인터페이스로 대체함으로써 어노테이션 시간을 단축시켰다(He, 2023). 그러나 이러한 도구들은 여전히 개별 객체마다 포인트를 입력해야 하는 상호작용적 방식에 의존한다. 또한 SAM은 근본적으로 클래스 불가지론적(Class-Agnostic) 모델로 객체를 분할할 수는 있지만 객체의 의미적 범주를 판별하지는 못한다(Ma et al., 2024). 이로 인해 버섯 재배사와 같이 객체가 밀집되고 조명이 불균일한 복잡한 환경에서는 객체와 배경을 명확히 구분하지 못하거나, 단일 객체가 과분할되는 문제가 빈번히 발생한다(Li et al., 2023; Ji et al., 2024).
본 연구에서는 이러한 한계를 보완하고 느타리버섯 이미지의 효율적인 분할 어노테이션 작업을 위해 Meta AI가 개발한 SAM3를 적용하였다. SAM3는 기존 SAM의 기하학적 정밀성에 시각-언어 기반 의미론적 이해 능력을 결합한 최신 파운데이션 모델로, 텍스트 프롬프트를 통해 복잡한 장면에서도 특정 개념을 직접 이해하고 정밀하게 분할할 수 있다(Carion et al., 2025).
SAM3의 핵심 아키텍처는 세 가지 핵심 구성 요소로 이루어진다(Fig. 2). 첫째, 통합 지각 인코더(Unified Perception Encoder)는 이미지와 텍스트를 공유 임베딩 공간으로 매핑하여, 별도의 검출기 없이도 텍스트 기반 세그멘테이션을 가능하게 한다. 둘째, 분리된 존재 헤드(Decoupled Presence Head)는 세그멘테이션 수행 전에 입력된 개념이 이미지 내에 존재 여부를 판단하여, 복잡한 배경에서의 위양성 탐지를 감소시킨다. 셋째, 프롬프트 조건부 마스크 디코더(Prompt-Conditioned Mask Decoder)는 텍스트, 박스, 포인트 등 다양한 형태의 프롬프트를 입력받아 이에 조건화된 세그멘테이션 마스크를 생성한다(Kirillov et al., 2023).
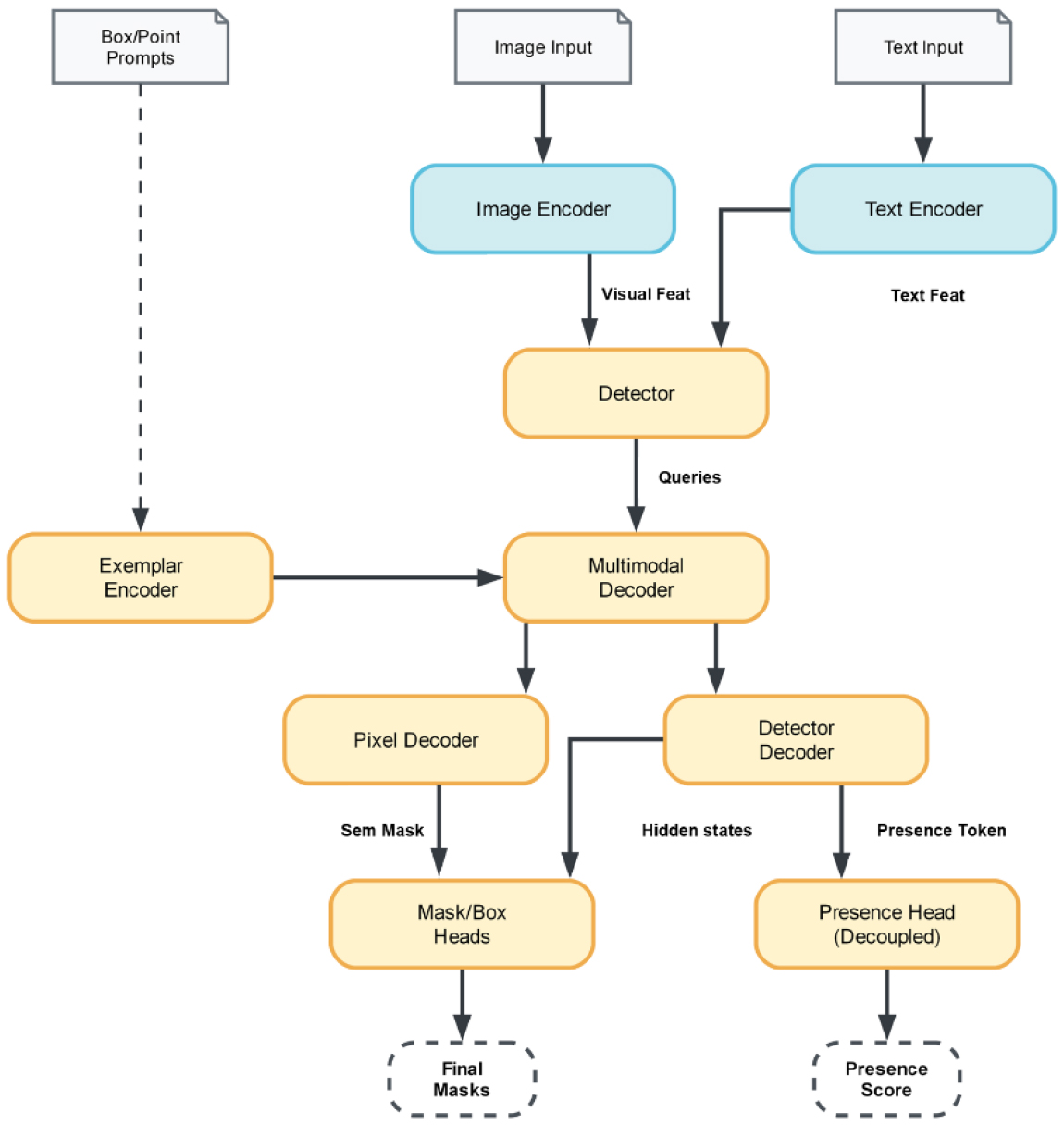
Fig. 2
Flowchart of image segmentation using the SAM3 architecture. The diagram illustrates the processing pipeline where input mushroom images and prompts are mapped through the Unified Perception Encoder and Multimodal Decoder. It highlights the generation of semantic masks via the Mask/Box Heads and the validation of object existence using the Decoupled Presence Head
SAM3는 약 400만 개의 고유한 개념 레이블을 포함하는 SA-Co(Segment Anything with Concepts) 데이터셋으로 학습되었으며, 이는 기존 SA-1B 데이터셋에서 풍부한 의미론적 정보를 확장한 것이다(Kirillov et al., 2023). 이는 “white lily”와 같은 식물 객체를 텍스트 프롬프트로 입력하여, 별도의 추가 학습 없이 제로샷 분할 성능이 실험적으로 확인되었으며, 텍스트 프롬프트 기반 개념 분할(Promptable Concept Segmentation, PCS) 성능 역시 대규모 벤치마크에서 정량적으로 검증되었다(Carion et al., 2025).
5. SAM3 기반 어노테이션 시스템 설계 및 구현
이미지의 어노테이션 효율을 향상시키기 위해 본 연구에서는 텍스트 기반 분할 기능을 중심으로 하는 반자동 어노테이션 시스템을 설계하고 구현하였다(Fig. 3). 본 시스템은 프론트엔드 사용자 인터페이스와 백엔드 추론 엔진으로 구성된 독립형 아키텍처를 기반으로 하며, 텍스트, 박스, 포인트 프롬프트를 포함한 다양한 상호작용 입력을 모두 지원하도록 구현되었다. 프론트엔드는 이미지 불러오기, 프롬프트 입력, 후보 마스크의 시각화, 사용자 보정 등을 직관적으로 수행할 수 있는 GUI 기반 인터페이스로 구성되었으며, 사용자가 분할 결과를 단계적으로 확인하고 조정할 수 있도록 설계되었다. 백엔드는 멀티모달 파운데이션 모델인 SAM3의 사전학습 가중치를 활용하여, 텍스트 임베딩 생성, 이미지 특징 추출, 후보 마스크 생성 및 예측 확신도(confidence score) 기반 분할 결과 산출을 수행한다.
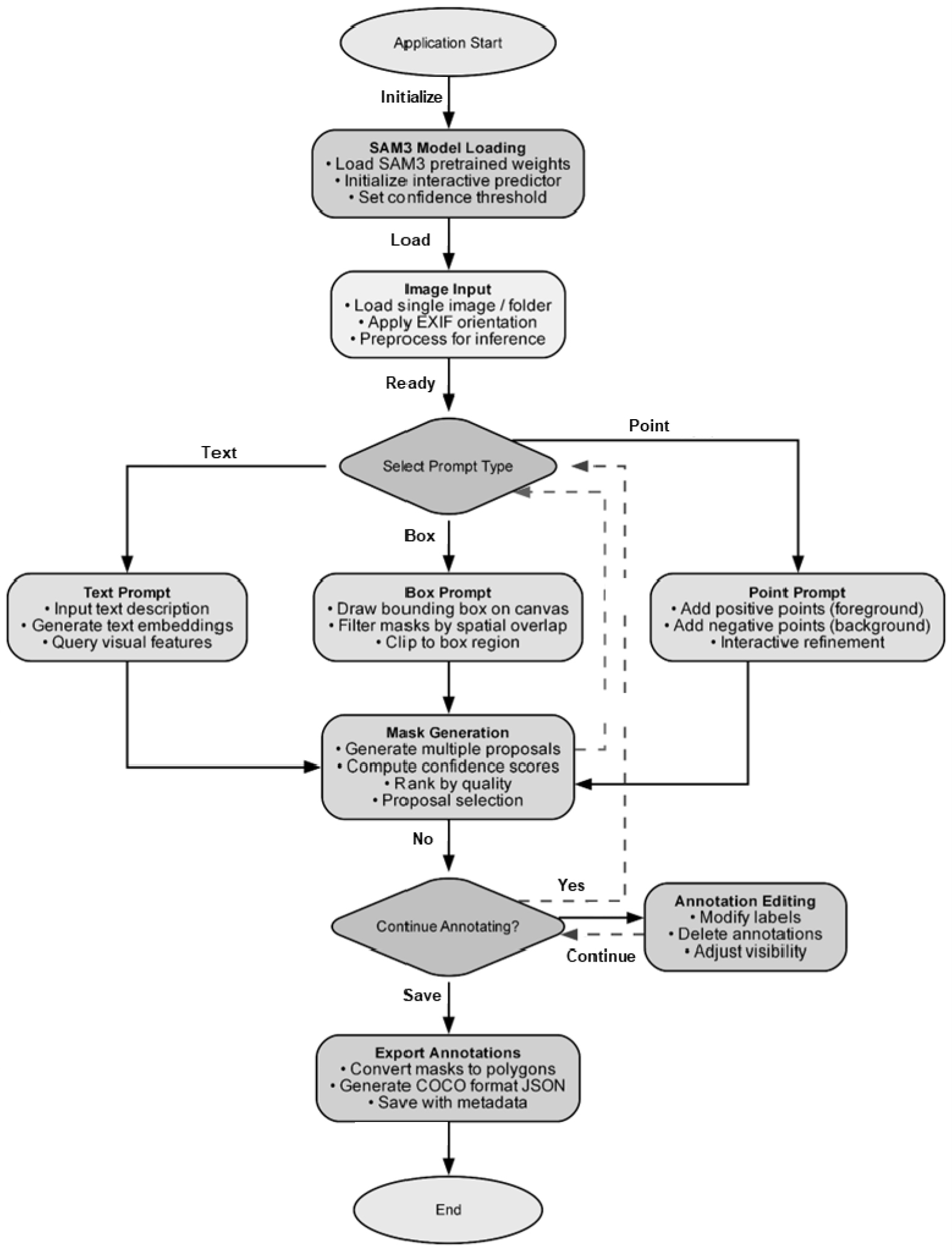
시스템의 동작 절차는 다음과 같이 구성된다. 프로그램 실행 시 SAM3 모델 가중치가 로딩되고 인터랙티브 예측기가 초기화되며, 사용자가 단일 이미지 또는 이미지 폴더를 입력하면 시스템은 자동으로 EXIF 기반 방향 보정과 크기 정규화 등 필요한 전처리 과정을 자동으로 수행한다. 이후 사용자는 텍스트, 박스 또는 포인트 프롬프트 중 하나를 선택하여 분할을 요청할 수 있다. 텍스트 프롬프트의 경우 자연어 설명을 텍스트 임베딩으로 변환한 뒤 이미지 내 시각적 특징과 매칭하여 초기 후보 마스크를 생성하며, 박스 프롬프트는 사용자 지정 영역을 중심으로 탐색 범위를 제한하여 보다 집중된 분할을 수행한다. 포인트 프롬프트는 전경 및 배경을 지정하는 방식으로 경계를 정교하게 조정할 수 있는 인터랙티브 분할에 적합하다. 각 프롬프트에 대해 생성된 후보 마스크 집합은 예측 확신도에 따라 정렬되며, 사용자는 제안된 결과 중 최적의 마스크를 선택하거나 추가 입력을 통해 반복적으로 보정할 수 있다. 최종적으로 확정된 마스크는 다각형(polygon) 형태로 변환된 후, 이미지 메타데이터와 함께 COCO JSON 형식으로 저장 및 내보내기(export)된다.
6. 세그멘테이션 모델 및 평가 파이프라인
제안된 시스템의 텍스트 기반 분할 성능을 객관적으로 평가하기 위해, 텍스트 또는 멀티모달 입력을 지원하는 기존 대표 모델들을 바탕으로 비교 실험을 수행하였다. 텍스트 프롬프트 기반 객체 분할 접근법의 구조적 차이를 비교하기 위해, 결합 파이프라인 기반 모델과 단일 통합 모델인 SAM+CLIP, SAM2+CLIP, Grounding DINO+SAM, 그리고 SAM3를 포함한 네 가지 모델 조합을 비교 대상으로 선정하였다(Table 1). 실험에 사용된 각 모델의 사전 학습 가중치는 SAM의 경우 ViT-H(sam_vit_h), SAM2는 Hiera Large(sam2.1_hiera_large), Grounding DINO는 Base 모델을 사용하였다. 모든 모델은 입력 해상도(1080×1920), NVIDIA RTX 4080 SUPER(16GB VRAM) 및 PyTorch 2.7 CUDA 12.6 환경에서 수행하여 일관된 비교 조건을 유지하였다.
Table 1.
Processing flows and key characteristics of text-prompt-based segmentation models evaluated in this study
7. 평가 지표
성능 평가는 구축된 600장의 전체 데이터셋을 대상으로 수행하였으며, 모든 실험에서 동일한 텍스트 프롬프트인 “mushroom”을 모델 입력으로 하여, 모델이 자동으로 예측한 분할 결과를 평가에 사용하였다. 세그멘테이션의 정확도를 평가하기 위해 Intersection over Union(IoU)을 사용하였다. IoU는 예측된 마스크()와 정답 마스크() 간의 교집합 영역을 합집합 영역으로 나눈 값으로 정의되며, 다음 Eq. (1)과 같다.
여기서 TP(True Positive)는 예측 마스크가 정답 버섯 인스턴스와 IoU 임계값 이상으로 1:1 매칭된 경우의 인스턴스 수, FP(False Positive)는 정답 인스턴스와 매칭되지 않은 예측 인스턴스 수, FN(False Negative)은 예측과 매칭되지 않은 정답 버섯 인스턴스 수를 의미한다. 본 연구에서 정답 인스턴스(Ground Truth Instance)는 이미지 내에서 개별 버섯 갓 하나에 대응하는 단일 분할 객체를 의미한다.
또한 모델의 전반적인 탐지 및 분할 성능을 평가하기 위해 Average Precision (AP)을 사용하였다. AP는 정밀도(Precision, P=TP/(TP+FP))와 재현율(Recall, R=TP/(TP+FN)) 곡선 아래의 면적으로 계산된다. 본 연구에서는 MS COCO 벤치마크 기준을 따라, IoU 임계값(t)을 0.50부터 0.95까지 0.05 간격으로 변화시키며 측정한 AP들의 평균값(mean Average Precision, mAP)을 최종 성능 지표로 사용하였으며, 다음 Eq. (2)와 같다.
추가적으로 Matching Rate는 IoU 0.5 이상을 만족하는 예측 마스크의 비율로 정의하여 실제 어노테이션 적용 가능성을 판단하는 실용적 지표로 활용하였다. 마지막으로 평균 추론 시간은 1080×1920 해상도 이미지 한 장을 처리하는 데 소요되는 시간을 측정하여 시스템의 실시간 어노테이션 적합성을 평가하였다.
결과 및 고찰
1. 텍스트 기반 세그멘테이션 모델 비교 평가
본 연구에서는 텍스트 기반 반자동 어노테이션 시스템의 핵심 엔진 선택을 위해 텍스트 프롬프트를 지원하는 4개의 대표적인 세그멘테이션 모델을 비교 평가하였다. 평가 대상은 SAM+CLIP, SAM2+CLIP, Grounding DINO+SAM, 그리고 SAM3이며, 구축된 600장의 느타리버섯 이미지 데이터셋과 10,129개의 정답 인스턴스를 활용하여 검출 성능, 분할 정밀도, 처리 속도를 측정하였다. 모든 모델에 동일한 텍스트 프롬프트 “mushroom”을 입력하였으며, 출력된 마스크와 정답 마스크 간의 매칭은 IoU 임계값(0.5)을 기준으로 수행하였다.
정밀도 검출 성능 측면에서 모델 간 차이가 관찰되었다 (Table 2). SAM3는 10,129개의 정답 객체 중 9,407개를 검출하여 92.9%의 매칭률을 기록하였으며, 이는 평가 대상 모델 중 가장 높은 수치였다. SAM+CLIP은 62.8%(6,358개), SAM2+CLIP은 51.6%(5,232개)의 매칭률을 보였다. 반면 Grounding DINO+SAM은 505개(5.0%)만을 검출하여 전체 객체의 95.0%를 누락하는 검출 실패를 나타냈다.
Table 2.
Comparison of matching performance across different segmentation models for mushroom detection
이러한 성능 차이는 모델의 아키텍처적 특성과 직접적으로 연관된다. SAM+CLIP과 SAM2+CLIP 파이프라인은 SAM이 생성한 후보 마스크를 CLIP의 이미지-텍스트 유사도 점수로 필터링 하는 2단계 구조를 따른다. CLIP은 이미지 전체 수준의 분류에는 우수하나, 이미지 내 특정 위치를 지정하는 능력은 제한적이다. 이로 인해 CLIP은 매칭 과정에서 공간적 해상도가 부족하여 밀집된 버섯 객체를 정확히 식별하지 못하는 한계를 보였다. 특히 하나의 배지에 수십 개의 버섯 개체가 밀집하여 군집을 형성하는 환경에서는 개체 간 시각적 경계가 모호하여 CLIP의 유사도 매칭 정확도가 저하되어 다수의 객체가 누락되었다. SAM2+CLIP은 SAM+CLIP 대비 매칭률은 감소하였으나, mAP는 오히려 증가하였다. 이는 SAM2가 경계 정밀도를 중심으로 분할 품질을 개선한 반면, 매칭률은 IoU 0.5 단일 기준의 재현율 지표로서 이러한 정밀도 향상의 이점을 충분히 반영하지 못했기 때문으로 해석된다. 즉, SAM2는 검출된 객체에 대해서는 더 정확한 분할을 제공하지만, 보수적인 마스크 특성으로 인해 일부 객체가 IoU 기준 매칭에서 제외되면서 매칭률이 낮아진 것으로 판단된다.
Grounding DINO+SAM의 심각한 검출 실패는 2단계 파이프라인의 구조적 한계와 함께 객체 검출 수준의 문제를 드러낸다. Grounding DINO는 “mushroom”이라는 텍스트 프롬프트를 받아 이미지 내 버섯 영역을 검출하지만, 개별 버섯 갓을 구분하지 못하고 전체 군집을 하나의 객체로 인식하는 경향을 보였다. 즉, 하나의 배지에 수십 개의 개별 버섯 인스턴스가 존재함에도 불구하고, 모델은 이를 구분하지 못한 채 단일 마스크만을 생성하였다. 결과적으로 505개의 검출 결과는 이미지 수준의 버섯 영역 검출 개수를 의미하며, 10,129개의 개별 버섯 갓에 대한 인스턴스 단위 분할에는 실패하였다(Fig. 4). 이는 Grounding DINO가 본질적으로 객체 검출 및 시맨틱 세그멘테이션을 목적으로 설계되었으며, 인스턴스 수준의 구분 능력이 부족함을 보여준다(Fig. 4).
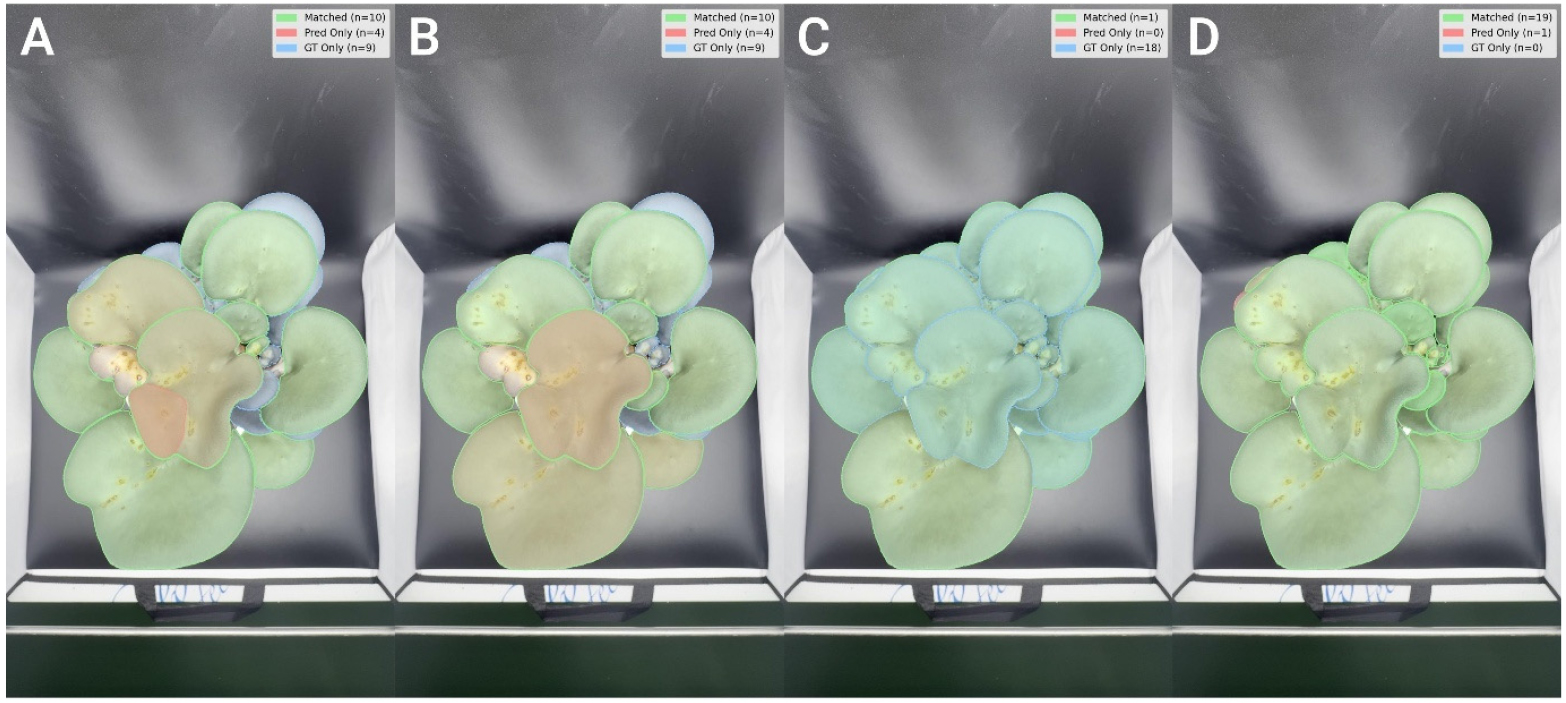
Fig. 4
Representative results of segmentation performance across different models. (A) SAM + CLIP, (B) SAM2 + CLIP, (C) Grounding DINO + SAM, and (D) SAM3. Green masks indicate correctly matched predictions (Matched), red masks represent false positives (Pred Only), and blue outlines show missed ground truth objects (GT Only)
이와 대조적으로 SAM3는 통합 비전-언어 인코더(Unified Vision-Language Encoder)를 통해 이미지와 텍스트 정보를 동시에 처리하고, 분리된 존재 헤드가 객체의 존재 여부를 판단한 후 분할을 수행하는 구조를 가진다. 이러한 통합 아키텍처를 통해 별도의 검출기 없이도 텍스트 프롬프트 기반 객체 분할이 가능하며, 본 연구와 같이 복잡한 느타리버섯 군집 환경에서도 개별 인스턴스를 효과적으로 구분하여 높은 재현율을 달성하였다. 실제로 SAM3는 전체 정답 객체 중 92.9%(9,407개)를 검출하여 비교 대상 모델 중 가장 높은 매칭률을 기록하였다. SAM3에서 검출되지 않은 7.1%(722개)의 객체는 다수의 인스턴스가 층상으로 중첩되어 개별 객체의 경계가 소실된 경우나, 객체 면적이 이미지 전체의 1% 미만으로 작아 IoU 0.5 기준에서 안정적인 매칭이 어려운 사례에 해당하였다.
분할 정밀도는 mAP와 Mean IoU 지표를 사용하여 평가하였다(Table 3). SAM3는 mAP 0.790을 기록하여 가장 높은 정밀도를 나타냈으며, AP@0.50은 0.838, AP@0.75는 0.813으로 IoU 임계값이 증가하여도 안정적인 성능을 유지하였다. SAM2+CLIP은 mAP 0.652, SAM+CLIP은 0.614를 기록하였다. Grounding DINO+SAM은 검출 실패로 인해 모든 AP 지표가 0으로 측정되었다. Mean IoU 측면에서는 SAM2+CLIP이 0.929로 가장 높은 값을 보였으며, SAM3는 0.885, SAM+CLIP은 0.877을 기록하였다. 그러나 SAM2+CLIP의 높은 IoU는 전체 객체의 51.6%만을 검출한 상태에서 측정된 값이라는 점을 고려해야 한다. 즉, 검출된 객체에 대해서는 매우 정밀한 마스크를 생성하나 절반에 가까운 객체를 누락하는 특성을 보였다. 실제 어노테이션 작업에서는 미검출 객체를 모두 수동으로 추가해야 하므로, 높은 IoU 값이 실용적 의미를 갖지 못한다.
Table 3.
Comparison of segmentation precision metrics (IoU and mAP) across different models
SAM3는 92.9%의 높은 검출률을 유지하면서 Mean IoU 0.885를 달성하여 검출 성능과 분할 품질 간 균형이 가장 우수하였다. IoU 표준편차는 SAM3가 0.241, SAM2+CLIP이 0.151, SAM+CLIP이 0.263을 나타내어, SAM2+CLIP이 가장 일관된 분할 품질을 보였으나 이는 전술한 바와 같이 낮은 검출률의 맥락에서 해석되어야 한다. Grounding DINO+SAM은 검출된 505개 객체에서조차 Mean IoU 0.225로 낮은 분할 품질을 보였다. mAP와 매칭률을 함께 고려한 분석에서 SAM3는 높은 mAP와 높은 매칭률을 동시에 달성한 유일한 모델이었다. 이는 SAM3가 다수의 객체를 검출하면서도 높은 정밀도를 유지하는 이상적인 특성을 갖추었음을 의미한다.
처리 속도 측면에서는 이미지당 평균 처리 시간을 비교하였다(Table 4). Grounding DINO+SAM이 1.28초로 가장 빠른 속도를 보였으나, 95%의 객체를 검출하지 못하였음을 고려해야 한다. 실질적으로 사용 가능한 모델 중에서는 SAM3가 11.30초로 가장 빠른 처리 속도를 나타냈으며, SAM2+CLIP은 21.29초, SAM+CLIP은 67.43초를 기록하였다. 마스크 생성 단계만을 고려하면 SAM3는 0.42초, SAM2+CLIP은 9.51초, SAM+CLIP은 53.58초가 소요되어 그 차이가 더욱 명확하였다. SAM+CLIP의 경우 SAM 추론과 CLIP 전처리 및 추론을 순차적으로 수행하여 총 처리 시간이 증가하였으며, SAM2+CLIP은 개선된 효율성으로 SAM+CLIP 대비 3.2배 빠른 속도를 보였으나 SAM3 대비로는 1.9배 느렸다.
Table 4.
Comparison of average inference time and total processing speed per image across different models
| Model | Mask Generation (s) | Evaluation (s) | Total (s) | 600 Images (h) |
| SAM + CLIP | 53.58 | 13.85 | 67.43 | 11.2 |
| SAM2 + CLIP | 9.51 | 11.78 | 21.29 | 3.5 |
| Grounding DINO+SAM | 0.49 | 0.79 | 1.28 | 0.2 |
| SAM3 | 0.42 | 10.88 | 11.30 | 1.9 |
600장의 전체 이미지를 처리하는 데 소요되는 시간은 SAM3가 약 1.9시간, SAM2+CLIP이 약 3.5시간, SAM+CLIP이 약 11.2시간으로 산출되었다. 대량의 농업 이미지를 어노테이션해야 하는 실제 적용 시나리오에서 이러한 속도 차이는 작업 효율성에 결정적 영향을 미친다. SAM3의 빠른 처리 속도는 통합 아키텍처에서 기인하며, 별도의 전처리나 검출 단계 없이 텍스트와 이미지를 동시에 처리하여 마스크를 직접 생성한다. 또한 분리된 존재 헤드가 객체 부재를 조기에 판단하여 불필요한 연산을 줄임으로써 효율성을 높인다. 성능과 속도를 함께 고려한 분석에서 SAM3는 가장 높은 mAP를 유지하면서도 가장 빠른 처리 속도를 달성하여, 성능과 속도 간의 일반적인 상충관계를 동시에 극복한 모델임을 보여준다(Fig. 5).
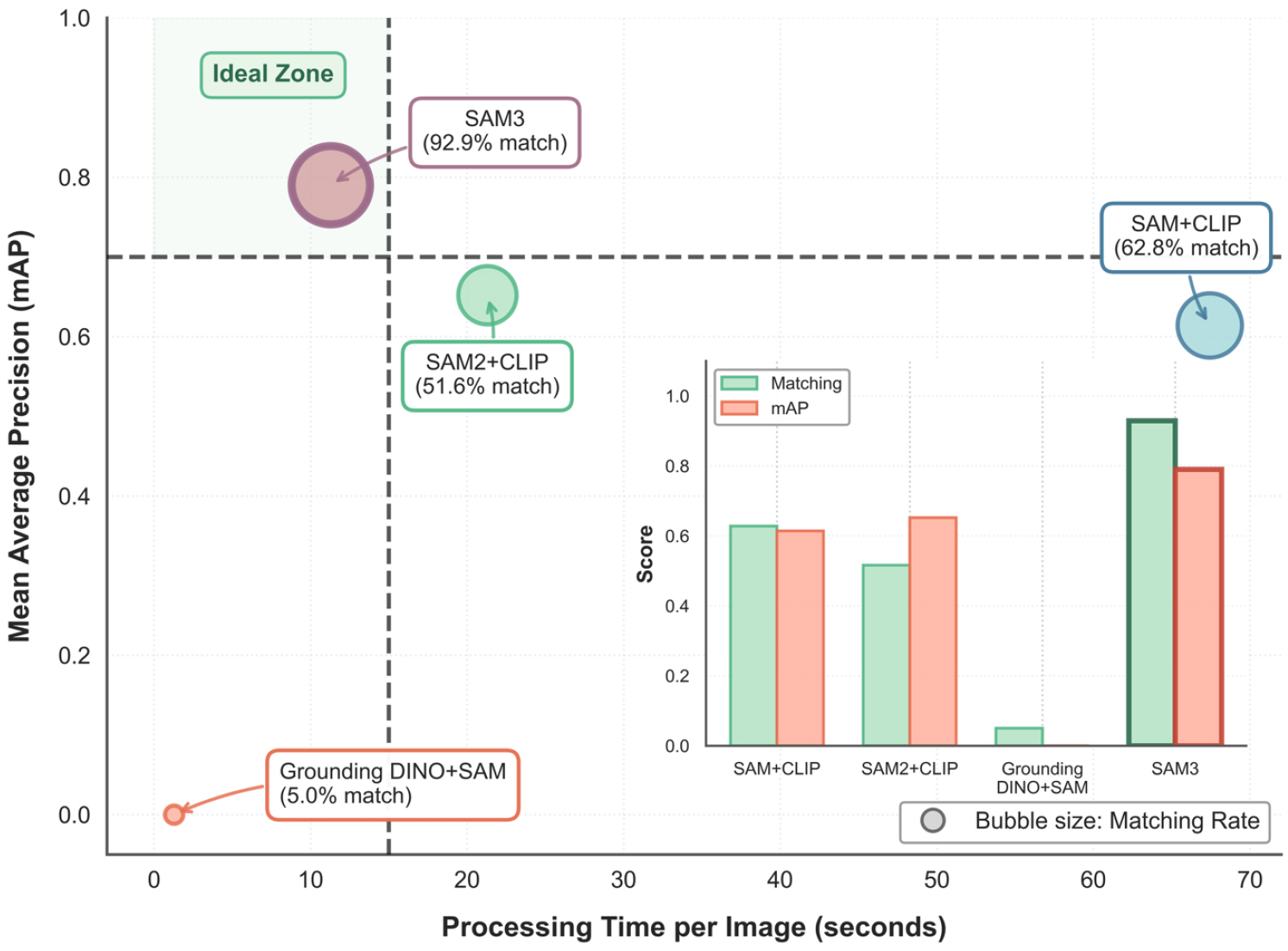
Fig. 5
Performance-efficiency trade-off analysis of different segmentation models. The scatter plot illustrates the relationship between mean Average Precision (mAP) and processing time per image. The bubble size represents the Matching Rate (%). SAM3 is positioned nearest to the “Ideal Zone,” demonstrating high accuracy and recall with efficient processing speed
결과적으로 SAM3는 높은 재현율(92.9%), 높은 수준의 정밀도(Mean mAP 0.790), 그리고 실시간 처리에 근접한 속도(11.30초/이미지)를 모두 충족하는 유일한 모델로 확인되었다. 이러한 근거를 바탕으로 본 연구에서는 SAM3를 GUI 기반 반자동 어노테이션 시스템의 핵심 엔진으로 최종 선택하였다.
2. SAM3 기반 반자동 어노테이션 시스템 개발 및 적용
SAM3의 텍스트 프롬프트는 “mushroom”과 같은 자연어 입력만으로 이미지 전체에서 해당 객체를 자동 분할할 수 있어, 대량의 유사 객체를 일괄 처리하는 데 효율적이다(Fig. 6). 그러나 실제 적용 결과 텍스트 프롬프트만으로는 약 7.1%의 객체가 정확하게 분할되지 않는 것으로 나타났으며, 이러한 실패 케이스에 대해서는 작업자의 수정이 필요하다. 이에 본 연구에서는 텍스트 프롬프트를 통한 초기 자동 분할과 이를 보완하는 인터랙티브 보정 방식을 결합한 텍스트 유도형 반자동 어노테이션 방법을 제안한다.
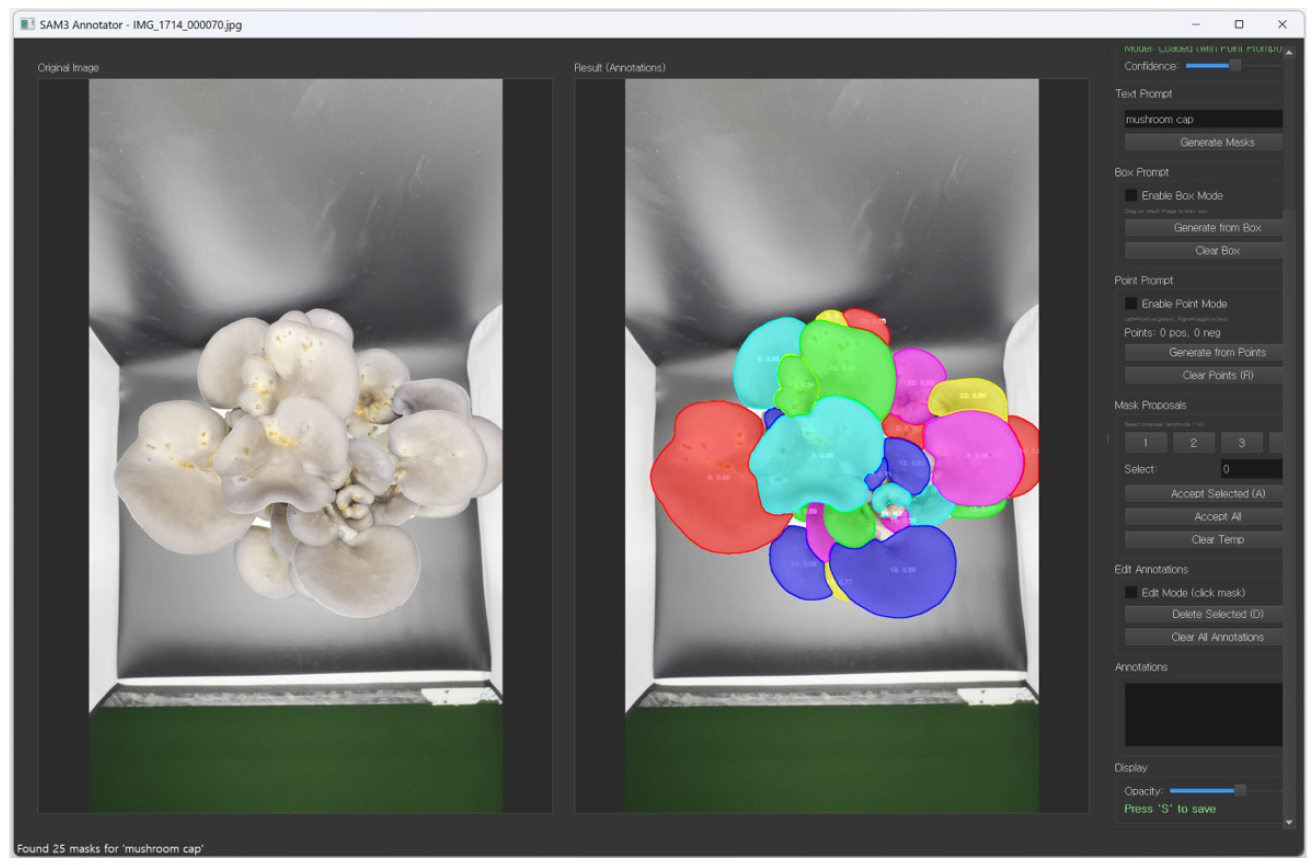
제안된 방법은 세 가지 프롬프트 유형을 순차적으로 활용하여 어노테이션 효율과 정확도를 동시 확보를 목표로 하였다. 텍스트 프롬프트를 통해 대부분의 객체를 일괄 분할하여 초기 어노테이션을 생성한 후, 누락되거나 특정 영역만을 대상으로 해야 하는 경우 박스 프롬프트를 적용한다. 작업자가 결과 캔버스에서 마우스를 드래그하여 박스를 그리면 해당 영역 내에서만 객체를 검출하고 분할하며, 박스 외부의 마스크는 자동 필터링되어 작업자가 의도한 영역에만 집중할 수 있다. 마스크 경계의 미세 조정이 필요한 경우 포인트 프롬프트를 사용한다. 좌클릭은 포지티브 포인트로 해당 영역을 마스크에 포함시키고, 우클릭은 네거티브 포인트로 해당 영역을 제외시키는 방식으로, SAM3의 통합 인터랙티브 예측기를 활용하여 복잡한 형태의 객체도 정밀하게 분할할 수 있다. 여러 포인트를 동시에 입력하여 복잡한 형태의 마스크를 생성할 수 있다는 점에서, 이 방식은 경계가 모호한 객체의 정밀한 분할에 효과적이다.
SAM3는 단일 프롬프트에 대해 예측 확신도가 다른 여러 마스크 후보를 생성한다. 본 시스템은 이를 최대 4개까지 제시하며, 각 후보는 고유 색상, 번호, 예측 확신도와 함께 표시된다. 특히 포인트 프롬프트 사용 시 multimask_output 옵션을 활성화하여 다양한 해석을 제공하는데, 이는 경계가 모호한 객체에서 작업자의 판단을 지원한다. 기본적으로 최고 확신도의 마스크가 선택되나, 작업자는 시각적 검토를 통해 다른 후보를 선택할 수 있다. 마우스 클릭 또는 숫자 키(1-4)를 통해 원하는 후보를 신속하게 선택할 수 있으며, 이러한 제안 메커니즘은 작업자가 마스크 품질을 직관적으로 평가하고 결정할 수 있도록 한다.
시스템은 듀얼 캔버스 구조를 통해 원본 이미지와 마스크 결과를 동시에 표시하며, 단축키 기반 인터페이스로 반복 작업의 효율성을 높인다. 생성된 마스크는 어노테이션 리스트에 라벨 및 예측 확신도와 함께 표시되며, 라벨 수정 시 드롭다운 메뉴를 통해 카테고리 일관성을 유지한다(Fig. 7). PyQt5 기반으로 구현된 시스템은 이미지 전처리, SAM3 추론, 프롬프트 처리, 어노테이션 관리의 네 개 모듈로 구성되며, inference state 공유를 통해 프롬프트 변경 시에도 이미지 재인코딩 없이 즉각 응답한다. 출력은 COCO JSON 형식으로 저장되며, OpenCV의 findContours 함수로 변환된 폴리곤 좌표와 메타데이터를 포함한다. 최종적으로 개발된 SAM3 기반 텍스트 유도형 어노테이션 시스템은 오픈 소스 라이선스 하에 배포되었으며, 상세한 설치 방법과 소스 코드는 GitHub 저장소(https://github.com/EthanSeok/SAM3_annotator)에서 확인할 수 있다.

고 찰
본 연구는 SAM3 기반 반자동 어노테이션 시스템을 개발하고 이를 느타리버섯 데이터셋 구축에 적용하여 그 실효성을 검증하였다. 모델 비교 평가 결과, SAM3는 92.9%의 매칭률로 가장 높은 재현율을 기록하여 어노테이션 도구의 핵심 엔진으로서 최적의 성능을 보였다. 재현율은 자동 어노테이션 결과 중 실제 학습에 활용 가능한 객체의 비율을 의미하므로, 실무적 관점에서 가장 중요한 지표라 할 수 있다.
반면 SAM+CLIP과 SAM2+CLIP의 상대적으로 낮은 매칭률(62.8%, 51.6%)은 CLIP 모델의 구조적 한계에서 기인한다. Rao et al.(2022)은 CLIP이 이미지의 전역적 의미 파악에는 강점을 가지지만, 밀집된 객체 환경에서 요구되는 미세한 공간 해상도 표현에는 한계가 있음을 지적하였다. 본 연구 결과 역시 이러한 한계가 느타리버섯과 같이 고밀도·중첩 구조를 갖는 농업 환경에서 성능 저하로 직결됨을 재확인하였다.
Grounding DINO+SAM의 극히 낮은 성능(5.0% 매칭률)은 2단계(Two-stage) 파이프라인의 구조적 취약성을 단적으로 보여준다. Grounding DINO는 텍스트 프롬프트에 대응하는 영역을 검출하는 데에는 효과적이었으나, 개별 버섯 갓을 구분하지 못하고 군집 전체를 단일 객체로 인식하는 경향을 보였다(Fig. 4). 이는 Wosner et al.(2021)이 보고한 바와 같이, 농업 환경 특유의 고밀도와 중첩(Occlusion) 조건이 일반 객체 검출기의 성능 저하를 유발하고, 그 오류가 후행 분할 단계로 전이되는 오류 전파(Error propagation) 현상으로 이어짐을 보여준다. 이에 반해 SAM3는 통합 지각 인코더를 통해 텍스트와 이미지를 동시에 처리하고, 분리된 존재 헤드를 활용해 객체 존재 여부를 사전에 판단함으로써 이러한 문제를 효과적으로 회피하였다.
시간 효율성 측면에서도 SAM3 기반 시스템은 기존 방식 대비 압도적인 개선을 보였다. 전통적인 수동 어노테이션은 객체당 30-60초가 소요되어 10,129개 객체에 대해 약 85-170시간이 필요하지만, 본 시스템은 전체 작업을 3-3.5시간 내에 완료하여 약 96-98%의 시간 절감을 달성하였다(Fig. 5). 다만, 이러한 시간 효율성에도 불구하고 자동 분할 결과에서는 전체 객체 중 7.1%에 해당하는 실패 사례가 관찰되었으며, 이에 대한 분석이 필요하다.
Fig. 8의 사례 분석 결과, SAM3에서 발생한 7.1%의 미검출 및 오류는 단일 원인이 아닌 복합적인 시각적 난이도에서 비롯된 것으로 확인되었으며, 이는 네 가지 유형으로 분류할 수 있다. 첫째, 다수의 버섯 갓이 층상으로 겹쳐 개별 경계가 소실된 극심한 중첩(Occlusion-dominant cluster) 유형이다(Fig. 8A). 이 경우 모델은 군집 전체를 하나의 객체로 인식하거나 후면 개체를 누락하는 경향을 보였다. 둘째, 이미지 전체 면적의 약 1% 미만을 차지하는 초기 생육 단계의 극소형 객체(Micro-instance) 유형으로, 시각적 단서 부족으로 인해 모델뿐 아니라 사람의 육안 판별 또한 어려운 경우였다(Fig. 8A). 셋째, 인접 객체와의 색상·질감 유사성으로 인해 갓의 일부만 분할되는 부분 분할(Incomplete segmentation) 유형이다(Fig. 8B). 넷째, 하나의 객체에 대해 중복 마스크가 생성되거나 배경 구조물이 객체로 오인되는 이중 마스킹 또는 위양성(False positive / double masking) 유형이다(Fig. 8C). 한편 Fig. 8D에서는 SAM3가 수동 어노테이션에서 누락된 객체를 검출한 사례도 확인되어, 사람의 어노테이션 결과 역시 오류 가능성을 내포함을 시사한다.
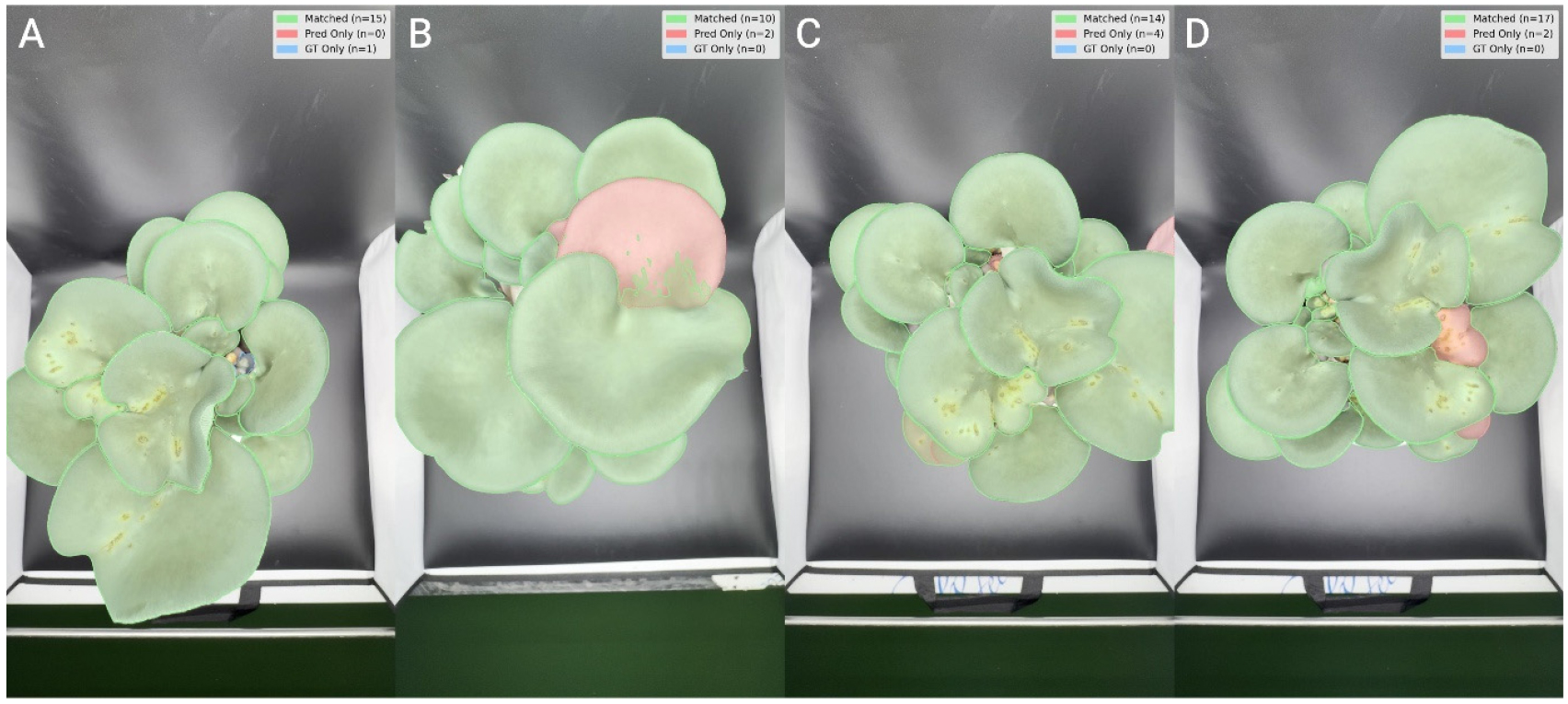
Fig. 8
Representative failure cases of SAM3 accounting for the 7.1% miss rate, and analysis of discrepancy sources. (A) False negatives where extremely small or heavily occluded objects were not detected by SAM3, (B) incomplete segmentation cases in which the generated mask fails to cover the entire pileus region, (C) false positives caused by background misclassification or double masking of a single instance, and (D) valid detections by SAM3 of instances that were missed during manual annotation, indicating potential human labeling errors. Green masks indicate correctly matched predictions (Matched), red masks represent prediction-only regions (False Positive), and blue outlines denote ground truth-only objects (False Negative)
이러한 실패 유형 분석은 완전 자동화보다는 반자동 어노테이션 전략이 현 단계에서 가장 현실적인 접근임을 뒷받침한다. 특히 실패 유형별로 인간 작업자의 개입 지점을 명확히 정의할 수 있다. 극심한 중첩 영역에서는 박스 프롬프트로 관심 영역을 제한한 후 포인트 프롬프트로 개별 경계를 보정하는 방식이 효과적이며, 극소형 객체의 경우 고배율 확대를 통한 누락 여부 검증과 인간 작업자의 수동 작업이 필요하다. 부분 분할 사례에서는 포지티브·네거티브 포인트를 활용한 인터랙티브 보정이 효율적이었고, 이중 마스킹이나 위양성은 어노테이션 리스트 기반의 삭제·병합 기능을 통해 최소한의 조작으로 품질을 확보할 수 있었다.
결과적으로 본 연구에서 제안한 SAM3 기반 반자동 어노테이션 시스템은 전체 객체의 약 93%를 자동으로 분할할 수 있었으며, 나머지 약 7%에 대해서만 제한적이고 선택적인 인간 개입이 요구되었다. 이는 전면적인 수동 어노테이션 대비 작업 부담을 현저히 감소시킬 수 있음을 보여준다. 한편, 본 연구에서도 다수의 객체가 완전히 중첩된 경우나 극소형 객체가 포함된 장면에서는 자동 분할의 실패 사례가 관찰되었으며, 이러한 조건에서는 추가적인 보정이 필요하였다. 이는 복잡한 배경이나 극단적인 중첩 환경에서 완전 자동화된 객체 분할이 여전히 도전적인 문제임을 시사하며(Ji et al., 2024), 자동 분할 결과에 대한 검증 및 보정 단계의 중요성을 부각시킨다.
이러한 결과를 종합하면, 현 단계에서는 자동 분할을 1차적으로 활용하고 인간 작업자가 예외적인 사례를 중심으로 개입하는 반자동 어노테이션 전략이 데이터 품질을 유지하면서도 구축 효율을 향상시킬 수 있는 실질적인 접근임을 확인할 수 있다.
