

서 론
재료 및 방법
1. 대상 시설
2. CH4 배출량 영향 인자 선정
3. 데이터 측정 및 구축
4. 데이터 구축 및 보간·전처리
5. Random Forest
6. LightGBM(LightGradient Boosting Machine)
7. HistGB(HistGradientBoosting)
8. 모델 학습방법
결과 및 고찰
1. 데이터 품질 평가
2. 상관관계 분석을 통한 CH4 및 환경인자 분석
3. 모델별 학습데이터 예측결과
4. 모델별 예측결과 해석 및 성능평가
서 론
국내 축산업 생산액은 최근 지속적인 증가 추세를 보이고 있으며, 농림어업 생산액 중 상당한 비중을 차지하고 있다. 특히 돼지 사육두수는 2023년 기준 전년 대비 약 12% 증가하여 (Korea Rural Economic Institute, 2023), 축산업이 국내 농업의 중요한 축으로 자리하고 있음을 보여준다. 그러나 축산업은 환경 문제, 특히 온실가스 배출이라는 중대한 과제를 안고 있다. 국내 농업 분야의 온실가스 배출량은 최근 공식 통계에 따르면 국가 전체 배출량의 약 3% 내외를 차지하며, 이 중 축산 분야는 농업 배출량의 약 48%를 점유한다(Greenhouse Gas Inventory and Research, 2023). 양돈시설의 경우 일반 산업 현장과 달리 CH4(메탄) 농도가 상대적으로 낮아 이를 정확히 측정하기 위해서는 고가의 장비가 요구된다. 이러한 이유로 상업 규모 농장에서 CH4 농도를 정밀하게 모니터링하는 데에는 한계가 존재한다.
현재 양돈 분야의 CH4 배출량 산정은 주로 마리당 배출계수에 기반한 IPCC(Intergovernmental Panel on Climate Change) 산정 방법론(IPCC, 2006)에 의존하고 있어, 시설 내부 환경 변화에 따른 실시간 예측이나 상황별 변동성을 충분히 반영하지 못한다는 한계가 있다. 따라서 축산업에서 발생하는 온실가스 배출량을 효과적으로 관리하기 위해서는 양돈 시설 내 CH4 농도를 측정하고 예측할 수 있는 기술이 필요하다. 그러나 CH4 센서는 설치와 유지 보수 비용이 높아 상시 활용에 어려움이 따르므로, 시설 내부의 다양한 환경 데이터를 활용하여 CH4 농도를 간접적으로 예측하는 접근이 요구된다. 기존 연구들은 주로 배출량 계산 방법론을 적용한 현장 측정(Feng 등, 2022; Ivanova-Peneva 등, 2008; Kim 등, 2008; Zong 등, 2015), 수치 모델링 기반의 시뮬레이션(Aarnink 등, 2016; Mosquera 등, 2011)을 사용해왔다. 최근 양돈시설의 환경인자(온도, 습도, 환기 등)에 기반한 대기오염가스 예측 연구에서 머신러닝 (ML) 모델을 적용하여 예측하고 있다. Xie 등(2017)은 적응형 신경 퍼지 추론 시스템(ANFIS)을 이용하여 비육돈사 내 NH3(암모니아)농도와 배출량을 예측한 결과, 기존의 다중선형회귀(MLRM)와 역전파신경망(BPNN)보다 결정계수(R2 = 0.64 수준) 가 높아 비선형적 환경 요인을 효과적으로 반영함을 보고하였다. Ma 등(2022)는 LSTM(Long Short-Term Memory) 신경망을 적용하여 돈사 온·습도 및 NH3 농도의 시계열 데이터를 1시간 후까지 예측한 결과, 평균제곱근오차(RMSE)가 1.6%로 낮아 시계열 예측 정확도가 우수함을 입증하였다. Peng 등(2022b)은 Random Forest(RF), XGBoost(Extreme Gradient Boosting), BPNN, LSTM, RNN 등 여섯 개의 모델을 적용하여 NH3 농도를 비교한 결과, PSO (Particle Swarm Optimization) 로 튜닝한 LSTM과 RNN 모델이 가장 높은 예측 정확도(R2 = 0.95)를 보였으며, 입력변수 중 CO2(이산화탄소)와 H2O(수증기)의 중요도가 가장 높았다. Basak 등(2024)는 온도, 상대습도, CO2 농도, 사료섭취량 (FI), 체중(MP) 등 5개 변수를 이용하여 SVR(Support Vector Regression), Random Forest Regression(RFR), 다중선형회귀(MLR) 모델을 비교한 결과, SVR이 가장 높은 예측성능(R2 > 0.95, RMSE ≤ 0.10ppm)을 보였다. 이처럼 각 선행연구에서 환경변수 선정 및 모델, 학습구조에 따라 성능적으로 차이를 나타냈으며, 특히 시간적 연속성 반영 여부와 입력변수 조합이 예측 정확도에 중요하게 작용하였다.
이처럼 학습 알고리즘마다 장단점이 뚜렷하기 때문에, 특정상황에서 어떤 모델이 가장 적합한지를 검증하는 과정이 필요하다. 특히 축산 시설 환경에서는 NH3, CO2 등 다양한 가스 농도 및 환경인자를 예측하기 위해 트리 기반 모델이 많이 활용되고 있다(Wang, 2023, Peng 등, 2022a). 트리 기반 알고리즘은 다차원적 환경 변수와 비선형적 상호작용을 효과적으로 반영할 수 있으며, 상대적으로 적은 데이터에서도 안정적인 성능을 보이는 장점이 있다. 그러나 구체적으로 트리 기반 모델 중 양돈시설 내 CH4 예측에 가장 적합한지는 아직 명확하지 않다. 따라서 본 연구에서는 실제 돈사를 운영하여 CH4을 포함한 환경 데이터를 직접 수집하고, 이를 바탕으로 다양한 트리 기반 학습 모델(RandomForest, LightGBM, HistGB)을 동일한 조건에서 학습·검증하였다. 이를 통해 각 모델의 예측 성능을 비교·분석하고, 양돈시설 CH4 예측에 가장 적합한 트리 기반 모델을 찾는 것을 목표로 한다.
재료 및 방법
1. 대상 시설
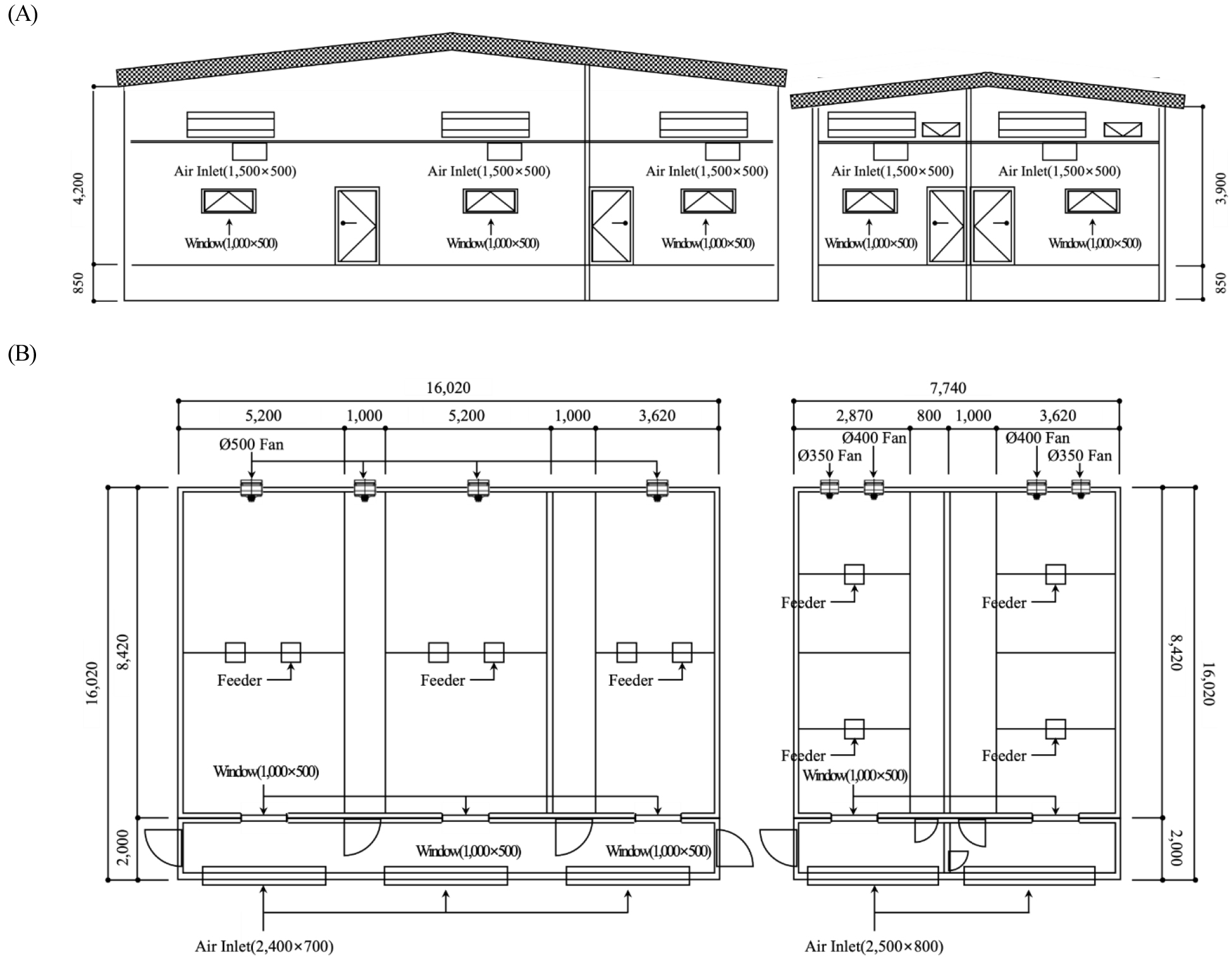
본 연구는 충청남도 예산군 대흥면 갈신리 1(공주대학교 예산캠퍼스, 36.6685°N, 126.8657°E)에 위치한 공학적 연구시설에서 수행되었다(Fig. 1). 해당 시설은 ICT 장비와 센서를 활용하여 돼지의 생육환경을 제어하고, 실험 및 연구의 효율성을 높이기 위한 목적의 테스트베드이다. 주요 시설 구성은 소규모 테스트베드 2동, 관리사 1동, 데이터 서버실 및 창고 1동으로 이루어진다. 실제 양돈 사육 환경을 구현함과 동시에 복합환경 영향인자 배출 특성을 모니터링할 수 있도록 설계되었다. 이를 위해 양돈시설의 입지 조건, 상·하수도, 전기, 통신, 악취 민원 등 다양한 요소를 고려하였으며, 농림축산식품부 (Ministry of Agriculture, Food and Rural Affairs 2021; NH Agribusiness 2021)에서 제시한 양돈시설 표준 설계도를 기준으로 돈방 구조, 비율, 크기 등을 반영함으로써 본 시설에서 연구되는 연구내용들을 일반 양돈시설에 적용가능 하도록 하였다. 또한, 발생하는 복합환경 영향인자를 정밀하게 측정할 수 있도록 하였다.

Fig. 2는 국립공주대학교 공학적 연구시설 내 소규모 테스트베드의 설계도를 나타낸다. 본 테스트베드는 자돈사, 육성돈사, 비육돈사로 구분되며, 각 돈사는 4개의 펜스로 세분화되어 있다. 자돈사는 2,870mm × 8,420mm 크기의 돈방 4개, 육성돈사는 3,620mm × 8,420mm 크기의 돈방 6개, 비육돈사는 5,200mm × 8,420mm 크기1의 돈방 4개로 구성된다(Ahn 등, 2023).
2. CH4 배출량 영향 인자 선정
양돈 시설에서 발생하는 CH4, NH3, 황화수소 (H2S)등 복합 환경오염을 유발하는 유해가스의 배출은 다양한 요인의 영향을 받는다. CH4, NH3의 발생은 사료 섭취 및 분뇨의 생물학적 분해 과정에서 유기물 부하와 미생물 활성에 의해 결정된다. 체중과 급이량은 돼지의 대사활동 및 분뇨 중 유기물 공급량을 결정하는 핵심 요인으로, 체중 증가와 사료 섭취량 증가는 분뇨 내 총 NH3성 질소(TAN) 농도를 높여 NH3 휘산과 CH4 생성 잠재력을 증가시킨다. Arogo 등(2010)와 Aarnink(1997)은 pH와 온도가 NH3 휘산의 주요 제어인자임을 규명하였으며, pH 상승은 암모늄-NH3 평형을 NH3 방향으로 이동시켜 휘산을 가속하고, 온도 상승은 휘산속도와 미생물 활성 모두를 강화시킨다고 보고하였다. Philippe와 Nicks(2015)는 분뇨의 혐기성 분해가 CH4의 주요 생성 원인이며, 고온·고유기물 조건에서 그 생산량이 지수적으로 증가함을 확인하였다. 또한, Blanes-Vidal 등(2008)은 축사 내 CH4과 NH3 배출의 시간적 변동이 주로 환기유량과 동물활동에 의해 결정된다고 보고하였으며, 환기량 증가는 가스의 질량전달계수를 높여 휘산을 촉진시키는 동시에, 내부 미기상(온도·습도)을 변화시켜 가스 발생량에 복합적 영향을 미친다고 설명하였다. 이러한 선행 결과에 따라 본 연구에서는 체중, 급이량, pH, 온도, 상대습도 및 환기유량을 CH4·NH3 농도의 주요 영향 변수로 설정하고, 센서 기반 시계열 데이터를 활용하여 각 인자의 상호작용이 배출농도에 미치는 영향을 정량적으로 분석하였다.
위와 같은 선행연구에서 양돈 시설에서의 CH4 배출은 다차원적 요인에 의해 작용함을 파악하였으며, 본 연구에서는 이러한 주요 영향인자와 측정 변수들을 체계적으로 정리하였다. 그 결과는 Table 1에 제시하였다.
Table 1.
Selection and evidence for factors influencing carbon generation
| Selection criteria | Detailed items | Reference |
| Auto measurement data | External environmental conditions (temperature, humidity, atmospheric pressure, wind speed) | Tabase et al., 2023; Castrillón et al., 2020; Sefeedpari et al., 2024; Verde et al., 2023; Philippe and Nicks, 2015 |
| Internal environmental conditions (temperature, humidity, ventilation volume) | Aarnink, 1997 | |
| CO2 | Stinn et al., 2014 | |
| NH3 | Lee et al., 2006 | |
| Temperature in excreta | Wolter et al., 2002 | |
| pH in excreta | Ogejo et al., 2010 | |
| Weight | Philippe and Nicks, 2015 | |
| The amount of feed | Atakora et al. 2011; Andretta et al., 2021 | |
| Electric energy usage | Kythreotou et al., 2012 | |
|
Manual measurement data | Growth level | Philippe and Nicks, 2015 |
| Feed | Kythreotou et al., 2012 |
3. 데이터 측정 및 구축
테스트베드 내부에서 수집되는 복합환경 영향인자 및 외부 환경인자 등을 수집하기 위하여 각 센서들을 소규모 테스트베드 내부에 구축하였다. 테스트베드 내부에 수집되는 탄소 발생 영향인자 및 측정인자별 모니터링 주기는 복합환경인자 예측 알고리즘 설계를 위한 많은 데이터 양과 구축된 데이터베이스의 저장 용량을 고려하여 선정했다. 온도 및 습도와 같은 환경 인자는 실제 양돈 시설의 환경조건을 고려하고 실제 국내 양돈시설의 일반적인 측정 주기를 따라 5분 간격으로 데이터가 수집되도록 설정했다. 환경 영향인자에 대한 측정은 비육돈사에서 진행되었다. 비육돈사 내부 설치 센서 등은 Table 2에 표기하였다. CH4의 경우, 대부분의 배출이 양돈의 호흡을 통해 배출된다. 하지만, 테스트베드 내부에 비육돈 25두를 사육하고 있어, 센서의 손상 및 양돈의 센서 접촉에 의한 데이터 수집이 불안정하여 양돈의 호흡 위치에서 측정을 진행에 어려움이 있다.
Table 2.
Sensor Location and Usage
이에 본 연구에서는 CH4 센서를 가스 흡입구를 환기팬 내부 정면에 설치하여, 내부에서 배출되는 CH4 발생량을 측정하였다. NH3와 내부 CO2, 온·습도 측정은 각각의 인자를 측정하는 개별 센서를 사용하였으며, 돈방 상단부에 설치하여 측정하였다. 미국 냉동공조학회(ASHRAE)기준에 따른 다점 평균 피토관 방법(ASHRAE Standard 111-2017)을 적용하여 압력센서로 측정하였다. 각 피토관은 1.5m 이상의 길이를 확보하여 설치하였다. 외부와 내부 간의 정압 차이를 차압 변환기(Selectable Range Differential Pressure Transmitter, SENSOCON, USA)를 통해 변환하여 유속으로 환산하였다.
4. 데이터 구축 및 보간·전처리
본 연구에서 사용된 데이터는 2024년 7월 1일부터 31일까지의 한 달간 공주대학교 양돈시설에서 5분 간격으로 수집된 시계열 자료이다. 전체 데이터는 CH4을 포함한 8,923개의 관측치로 구성되며, 시간(Time), 외기 온도(Temperature_Out), 외기 상대습도(RH_Out), 내부 온도(Temperatuere), 내부 상대습도(RH), CO2 농도(Carbon dioxid), NH3 농도 (Ammonia), 분뇨 표면 온도(Temperature_P), 분뇨 산성도 (PH_P), 분뇨 전기전도도(EC_P), CH4 농도(Methane), 사료 섭취량(Feed_ Weight) 등 총 12개의 변수로 구성되어 있다. 이 중 CH4 농도를 주요 분석 대상으로 설정하였으며, 나머지 환경 변수들은 예측 모형의 입력 변수로 활용하였다.
비육돈사에서 측정한 센서 데이터의 품질을 확보하기 위해 이상치 제거 후 결측 구간 복원 절차를 단계적으로 수행하였다. 우선 측정 데이터 중 이상치를 탐지하기 위하여 기준을 정하고 이를 통해 수행하였다. 이상치 검출은 센서 데이터의 물리적 한계와 통계적 특성을 함께 고려하여 수행하였다. 먼저, 측정값이 0 이하인 경우는 농도 단위(ppm)상 물리적으로 불가능하므로 제거하였다. 이후 시계열 내의 비정상 급변값을 검출하기 위해 Hampel 필터를 적용하였다. Hampel 필터는 중앙값과 중앙값절대편차(MAD)에 기반한 강건(robust)통계 기법이며, 통상적으로 ±3-3.5배 MAD 범위를 초과하는 값을 이상치로 정의한다(Wicklin, 2021). 따라서 본 연구에서는 연속된 12개 관측값(데이터 측정 간격 5분 기준, 약 60분 구간)을 하나의 분석 단위로 설정하고, 해당 구간 내 중앙값과 중앙절대편차(MAD)를 계산하였다. 이때, 중앙값으로부터 3.5배 이상의 편차를 보이는 데이터를 이상치로 판정하였다. 또한, 센서 응답지연이나 환기제어 구간에서 발생하는 급격한 변동을 탐지하기 위해 절대변화량과 표준편차 기반 임계값을 함께 적용하였다. 선행연구에 따르면, 양돈시설 내 CH4 및 CH4 농도의 정상 변동폭은 일반적으로 ±30ppm 이내로 보고되며(Feng 등, 2022; Ma 등, 2022), 이 범위를 초과하는 급변은 센서 노이즈 또는 순간 환기 효과에 기인한 비물리적 패턴일 가능성이 높다. 따라서 본 연구에서는 절대변화량이 50ppm을 초과하거나 직전 구간 표준편차의 0.6 배 이상 변화한 구간을 이상치로 규정하였다. 전처리과정을 통해 전체 8,923개의 관측치 중 전체 이상치는 55개로 약 0.62%이며 그중 CH4 농도는 총 206개의 이상치가 검출되었다. CH4 농도는 총 206개의 이상치가 검출되었다. 이는 주로 센서 오류로 인한 0값 또는 음수값에 해당하였다. 다른 환경 데이터들에 대한 이상치는 아래 Table 3에 표기하였다.
Table 3.
Summary of detected abnormal value by variable
탐지된 데이터의 이상치를 복원하기 위해 단변량 및 다변량 보간·평활 기법을 적용하였다. 단변량 접근에서는 시간축에 따른 선형 보간과 3차 스플라인 보간을 활용하였으며, 선형 보간 결과에는 지수이동평균(EMA)을 추가 적용하여 고주파 잡음을 완화하였다. 또한, Savitzky-Golay필터를 통해 파형 특성을 유지하면서 평활을 수행하였고, 국소 회귀 방식인 LOESS(Locally Weighted Regression)는 비선형적 추세 반영에 사용되었다. 다변량 기법으로는 K-최근접이웃(KNN)보간을 통해 환경 변수 간의 유사도를 기반으로 결측값을 추정하였으며 모든 평활기법은 이상치 제거 이후 보간된 신호의 안정성을 향상시키는 보정 절차로 수행되었다. 보간은 단기 (5분-30분 이하, 최대 6포인트) 결측 구간에 한정하여 수행하였으며, 이보다 긴 구간은 예측모델(GBM 기반)로 대체하여 시계열 왜곡을 최소화하였다.
5. Random Forest
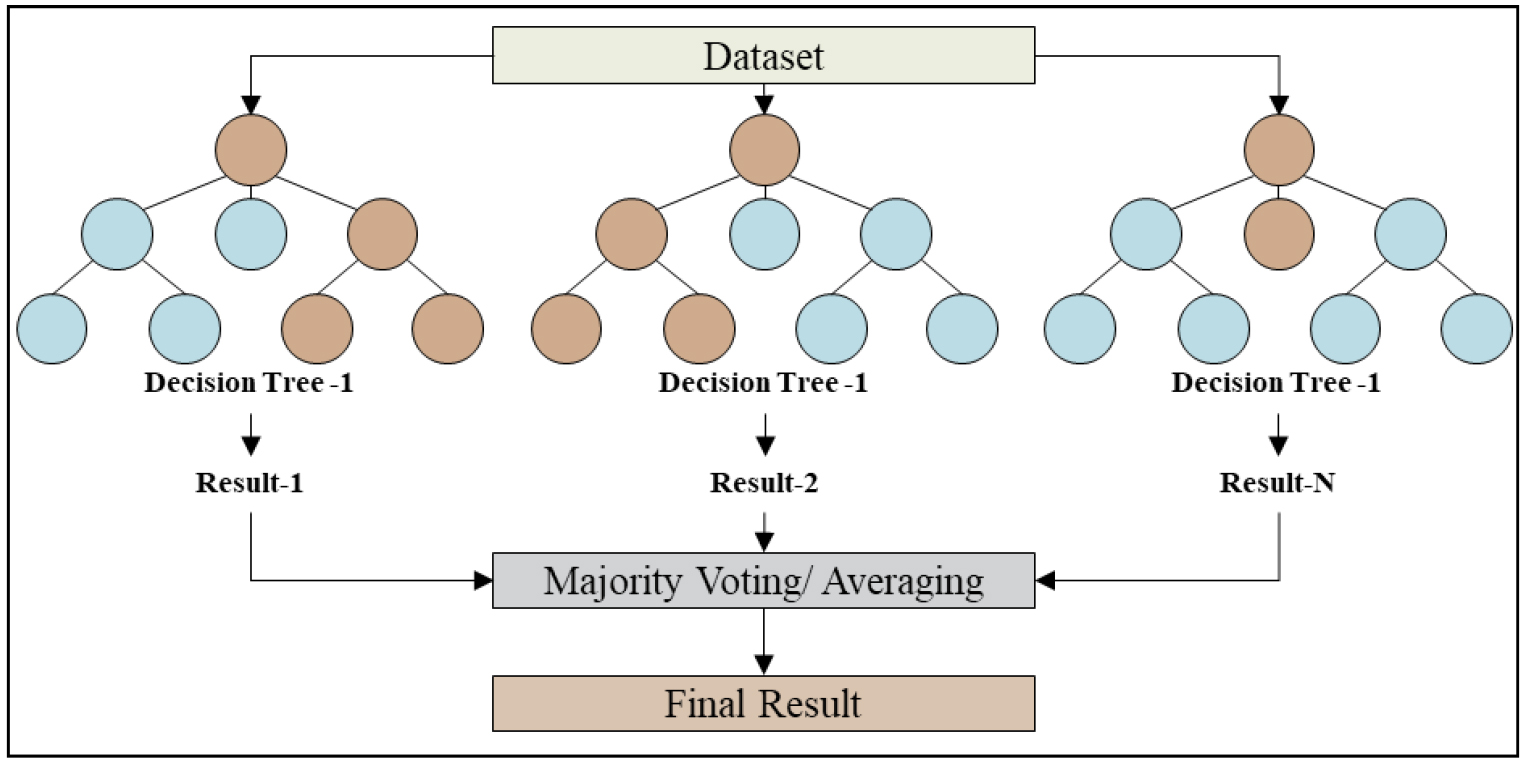
Random Forest는 앙상블 분석 기법 중 하나인 배깅 (Bagging)기법 기반 알고리즘이다. 모 데이터에서 n개의 샘플 데이터를 중복 허용하여 무작위로 추출하고, 여러 개의 의사결정나무 학습기에서 동시에 학습을 진행한다. 원리에 대한 설명은 Fig. 3으로 표현하였다. Random Forest는 전체 특성의 제곱근 수만큼 특성을 무작위로 선택하여 계산한다. 본 연구에서는 Random Forest 알고리즘을 활용하여 복합환경 인자를 예측하였다(Bogireddy 등, 2024; Deng 등, 2024; Maazallahi 등, 2024, Yamparla 등, 2022). 트리 개수 (n_estimators)를 300, 최대 깊이(max_depth)를 10으로 설정하였으며, 입력 변수의 제곱근 개수를 무작위로 선택해 각 트리를 구성하였다.
6. LightGBM(LightGradient Boosting Machine)
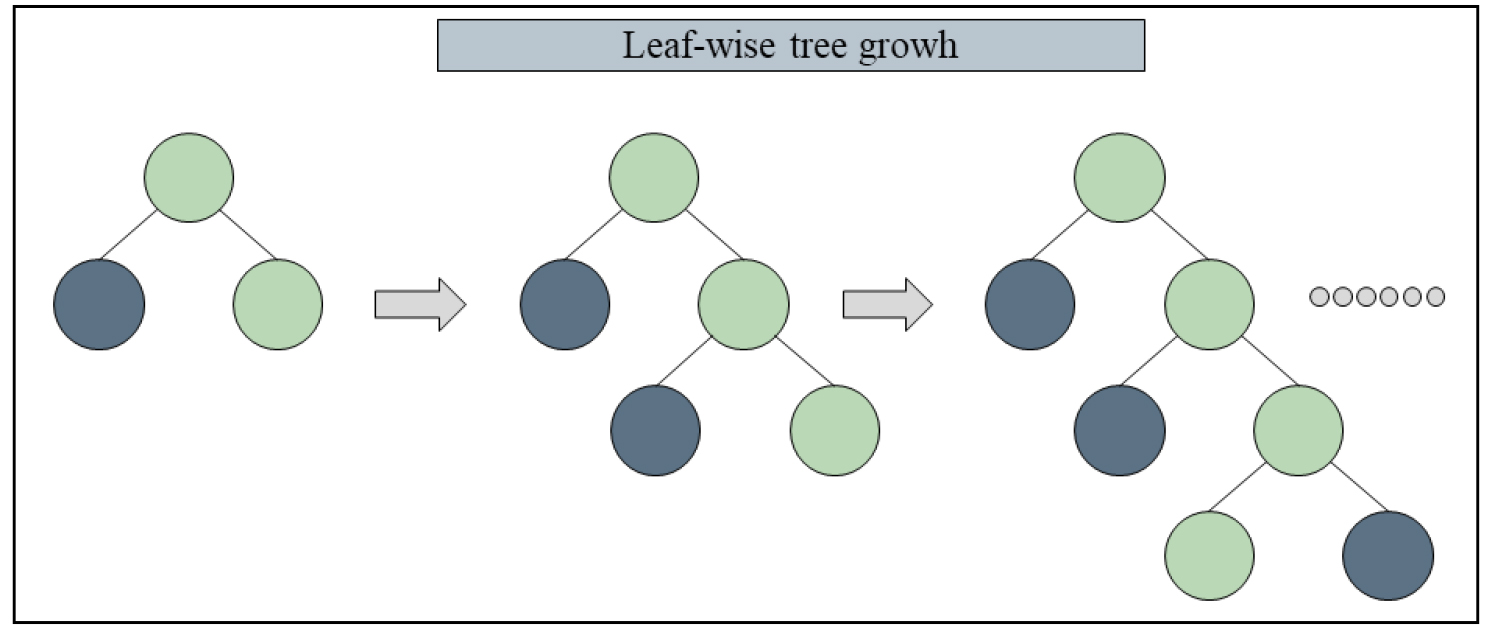
LightGBM은 그래디언트 부스팅 계열의 알고리즘으로, 대규모 데이터와 고차원 특징을 처리하는 데 최적화되어 있다. LightGBM은 leaf-wise 성장 방식을 적용하여 전통적인 level-wise 방식보다 더 깊고 비대칭적인 트리를 생성할 수 있으며, 이를 통해 예측 오차를 효과적으로 줄인다(Bhatt와 Varma, 2023; Peng 등, 2022b; Vyawahare 등, 2025).
또한 히스토그램(histogram)기반 학습 방식을 도입하여 연속형 입력값을 이산 구간으로 변환한다. 원리에 대한 설명은 Fig. 4로 표현하였다. 본 논문에서는 lightGBM에서 학습률(learning_rate) 0.05, 부스팅 반복횟수 500, 조기 종료 50회를 적용하여 과적합을 방지하였다. 시계열 특성을 고려하기 위해 데이터 순서를 유지한 채 5-fold 시계열 교차검증을 수행하였다.
7. HistGB(HistGradientBoosting)
HistGB는 사이킷런에서 구현된 히스토그램 기반의 그래디언트 부스팅(Gradient Boosting) 모델(Pushpalatha et al., 2023; Sefeedpari et al., 2024, Kumar 등, 2024)로 연속형 입력 변수를 일정한 구간(histogram bin)으로 나누어 학습 효율성을 높이는 방식이다(Pedregosa 등, 2011). 히스토그램 기반 분할은 특히 소규모 데이터셋에서도 계산 효율성이 높고, 트리 기반 모델의 비선형 관계 학습 능력을 유지하면서 메모리 사용량을 절감할 수 있다. 본 연구에서는 HistGB를 적용하였으며 bin 개수를 255로 설정하고, 평균제곱오차(MSE)를 손실함수로 사용하였다.
8. 모델 학습방법
본 연구에서는 보정된 양돈시설 환경 데이터를 기반으로 CH4 농도 예측 모델을 구축하였다. CH4 예측은 보정된 양돈시설 환경 데이터 개수인 총 8,923개를 시간 순서대로 분할해 진행하였다. 미래 정보가 학습에 포함되지 않도록 모든 입력 변수에 대해 지연 특성(lag 1, 3, 6, 12)과 과거 평균(rolling mean 6, 12)을 생성하되, 계산 시 항상 한 스텝 뒤로 밀어 (shift=1) 미래 정보가 학습에 스며들지 않도록 하였다. 입력 변수의 구성은 피어슨 및 스피어만 상관관계수를 기반으로 CH4 상관 절대값(|r| ≥ 0.3)을 만족하는 변수만을 1차 선별하였다. 이후 다중공선성 제거를 위해 분산팽창지수(VIF) ≤ 5 기준을 적용하여 독립적인 입력변수 집합을 확정하였다. 학습 단계에서는 상관관계 분석결과를 반영한 모든 환경 변수 (온도, 상대습도, CO2, NH3, pH, EC, 사료 급이량 등)를 포함한 보정 데이터를 활용하였으며, 검증 단계에서는 CH4 농도를 제외한 나머지 환경 변수만을 입력으로 사용하였다.
모델 학습에는 Random Forest, HistGB, LightGBM로 트리 기반 앙상블 알고리즘을 적용하였다. 각 모델은 동일한 입력 변수와 학습·검증 구간에서 훈련되었으며, 5-겹 시계열 교차검증(rolling-origin cross-validation)을 통해 RMSE(Root Mean Square Error) 가 최소화되는 방향으로 하이퍼파라미터를 조정하였다. Random Forest는 트리 개수를 700으로 설정하고 깊이 제한 없이(max_depth=None) 난수 시드 42를 고정하였다. HistGB는 학습률(learning_rate) 0.05, 깊이 제한 없음(max_depth=None), 동일한 난수 시드 42를 적용하였다.
LightGBM은 트리 개수 900, 학습률 0.05로 설정하였으며, 과적합 방지를 위해 부분 표본 비율(subsample=0.85)과 특성 샘플링 비율(colsample_bytree=0.85)을 적용하였다. 각모델별 초기 설정값의 대한 표를 아래에 Table 4로 표시하였다.
Table 4.
Summary of machine learning models and hyperparameter settings used for methane predictionprediction
검증 구간에서 RMSE(Root Mean Square Error), MAE (Mean Absolute Error), sMAPE(Symmetric Mean Absolute Percentage Error), NRMSE(Normalized RMSE), R2(Coefficient of Determination) 지표를 이용하여 정량화하였다. 모델 간 성능 차이의 통계적 유의성은 검증 구간의 절대오차 (|y−ŷ|)를 대상으로 윌콕슨 부호순위 검정(Wilcoxon signed-rank test, α = 0.05)을 수행하였으며, 보조로 Diebold-Mariano 검정 (DM-test)을 통해 예측오차의 평균 차이를 비교하였다.
결과 및 고찰
1. 데이터 품질 평가
원본 데이터에 대한 전처리 및 이상치 제거 과정을 통해 데이터의 품질이 전반적으로 향상되었다. 특히, CO2 농도의 경우 이상치 탐지 및 제거 과정을 통해 최대값이 약 980ppm 감소하여 원본 데이터에서 나타나던 비현실적인 스파이크가 제거되었다. 또한 분뇨 표면 온도와 분뇨 pH에서는 일부 구간에서 값이 불연속적으로 튀는 이상치가 존재하였으나, 인접 값으로 보정됨으로써 평균값이 각각 0.024, 0.014로 소폭 증가하였다. 동시에 표준편차는 0.103, 0.136으로 감소하여 변동성이 완화되었다. 특히 분뇨 EC의 경우 원본 데이터에서 최대 300 이상으로 치솟는 극단값이 관측되었으나, 전처리 이후 해당 값들이 제거되어 표준편차가 19.138만큼 크게 감소하였다. CH4 농도 역시 이상치 제거와 보간 과정을 거쳐 평균이 0.049로 증가하고 표준편차는 0.102로 줄어, 급등·급락 구간이 완화되었음을 확인할 수 있었다.
이상치 제거 후 시간 축을 기준으로 인접 시점의 실제 측정값을 이용한 선형 보간으로 결측 구간을 보완하고, 평활기법을 적용해 센서 신호의 단기적 변동을 완화하였다. 이는 이후 CH4 배출량 예측 모델의 학습 입력값으로서 데이터의 신뢰성과 해석 가능성을 높였다. 원본 데이터와 전처리 및 이상치 제거를 마친 데이터에 대한 비교 그래프를 Fig. 5, Fig. 6으로 표현하였다.
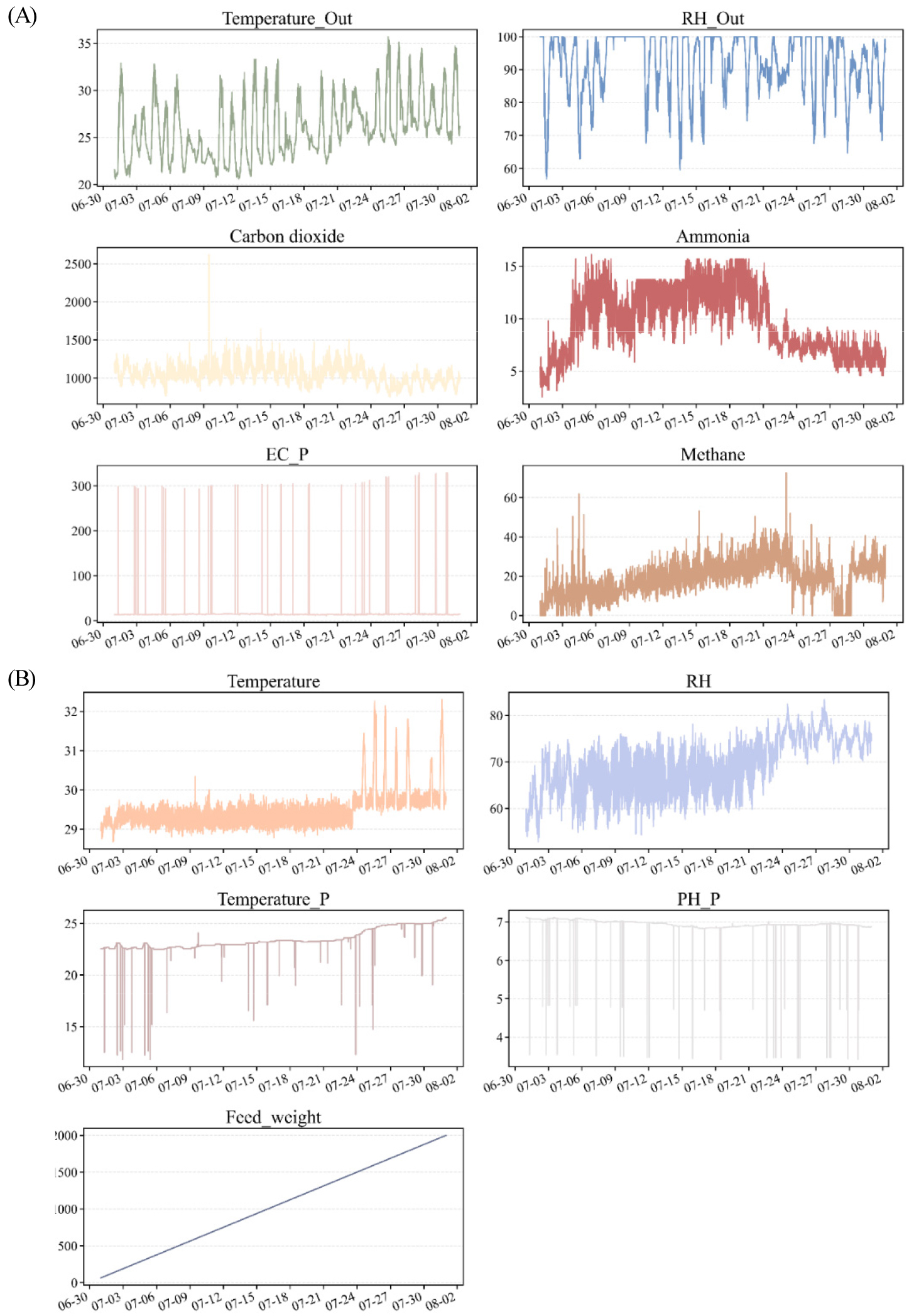
Fig. 5.
Raw time-series data of environmental variables before preprocessing. (A) Temperature and relative humidity data show frequent spikes and short-term fluctuations caused by ventilation and sensor instability. (B) Gas concentration data (CO2 and NH3) include missing segments and abrupt changes beyond the expected physical range, indicating the presence of outliers and measurement noise.
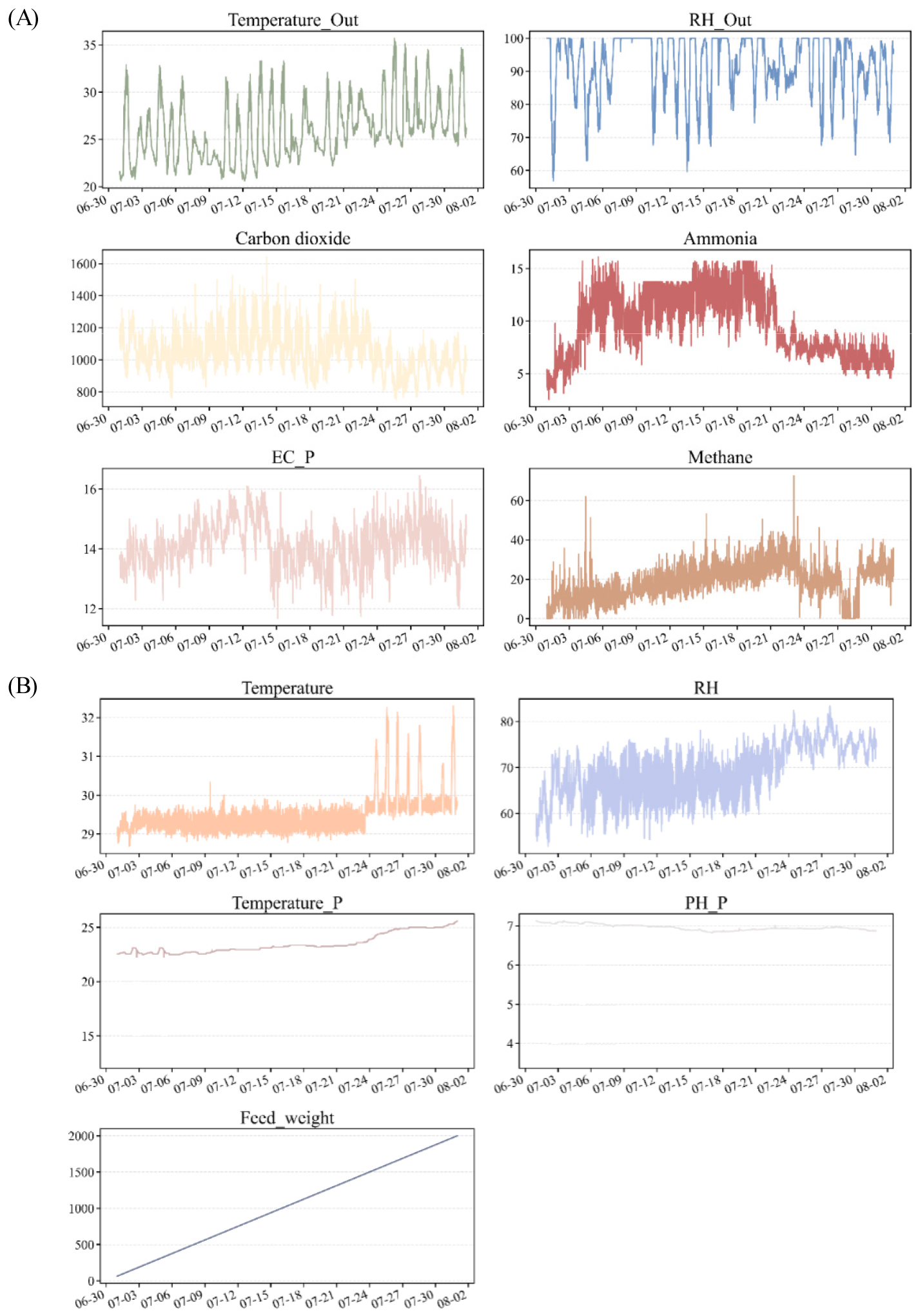
Fig. 6.
Time-series data after preprocessing and interpolation. (A) Temperature and humidity signals after outlier removal and smoothing show reduced spikes and stable daily fluctuations. (B) Gas concentrations (CO2 and NH3) after Hampel-filter-based cleaning and spline/KNN interpolation exhibit continuous and physically consistent patterns without abrupt jumps.
2. 상관관계 분석을 통한 CH4 및 환경인자 분석
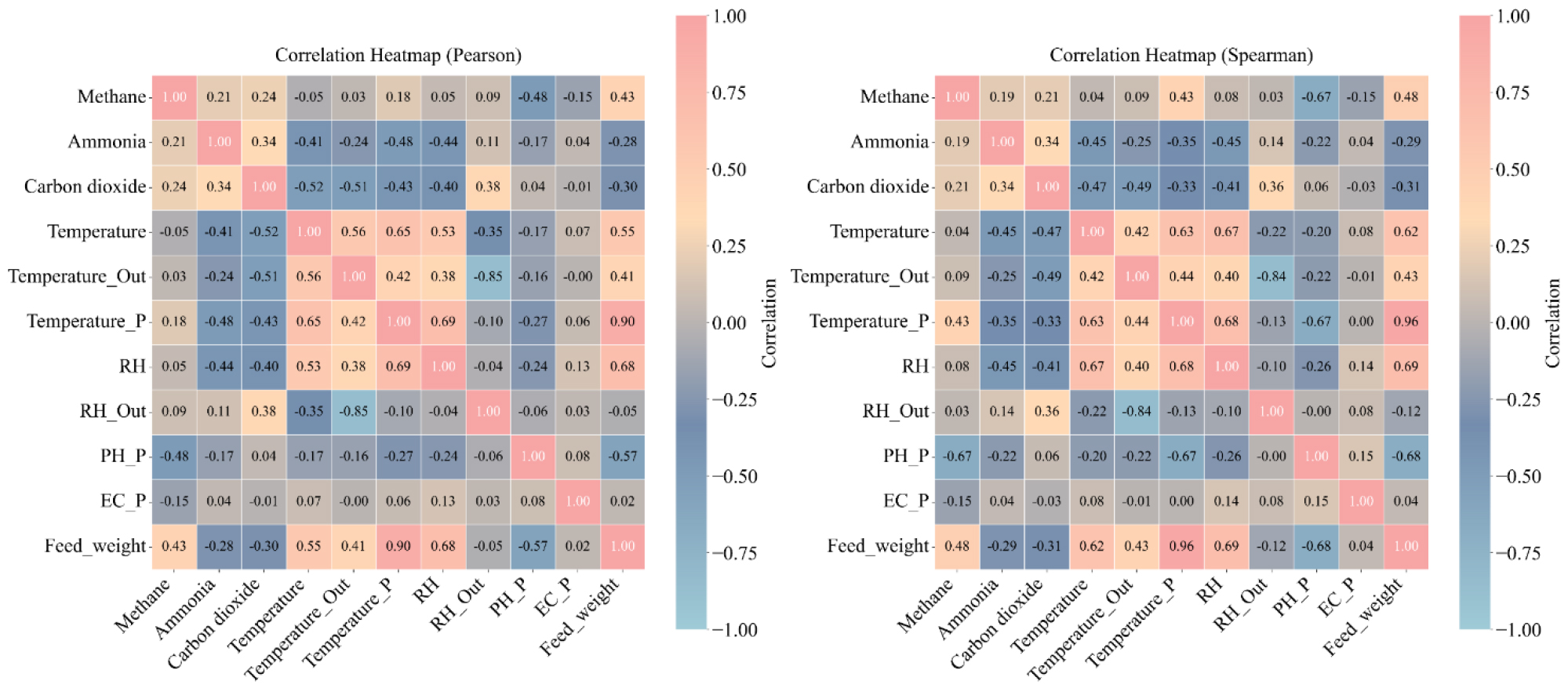
보정된 데이터를 바탕으로 CH4 농도와 환경 요인 간의 상관관계를 피어슨(Pearson) 과 스피어만(Spearman)방법으로 분석하였다. 상관관관계 분석 결과 그래프는 Fig. 7로 표현하였다. 피어슨 계수는 연속형 변수 간의 선형적 상관을 평가하는 데 적합하며, 스피어만 계수는 비선형적 또는 비정규 분포 자료에서 변수 간 단조(monotonic)관계를 보완적으로 확인하기 위해 사용하였다. 분석 결과, 분뇨 산성도는 CH4 농도와 음의 상관(피어슨 r = -0.48, p < 0.05; 스피어만 ρ = -0.43, p < 0.05)을 나타내어, 환기 강화나 외기 조건 변화 시 CH4 발생 억제와 연관성이 있음을 시사하였다. 반면, 사료 섭취량은 CH4 농도와 강한 양의 상관(r = 0.67, ρ = 0.64, p < 0.01)을 나타내어, 분뇨의 유기물 부하 및 미생물 활성 증가가 CH4 배출을 촉진하는 요인으로 작용함을 보여주었다. 가스 지표 간 상관관계에서는 NH3 농도와 CH4 간에 유의한 양의 상관(r = 0.24, p < 0.05)이 관찰되었고, CO2 농도 역시 CH4와 양의 경향(ρ = 0.21, p < 0.1)을 보였다. 외기습도 및 내부 습도는 CH4와의 상관이 낮았으나(-0.10 ≤ r ≤ 0.18), 내부 온도는 중등도 양의 상관(r = 0.43, p < 0.05)을 보여 발효 과정 중 온도 상승이 CH4 배출 증가에 기여함을 시사하였다.
3. 모델별 학습데이터 예측결과
각 모델에 대하여 상관관계 분석 및 데이터 학습 이후 성능 평가를 위해 RMSE, MAE, sMAPE, NRMSE, R2의 평가 방법을 이용하였다. 각 모델별로 학습 구간과 예측 구간을 구분한 그래프를 Fig. 8로 표현하였다.
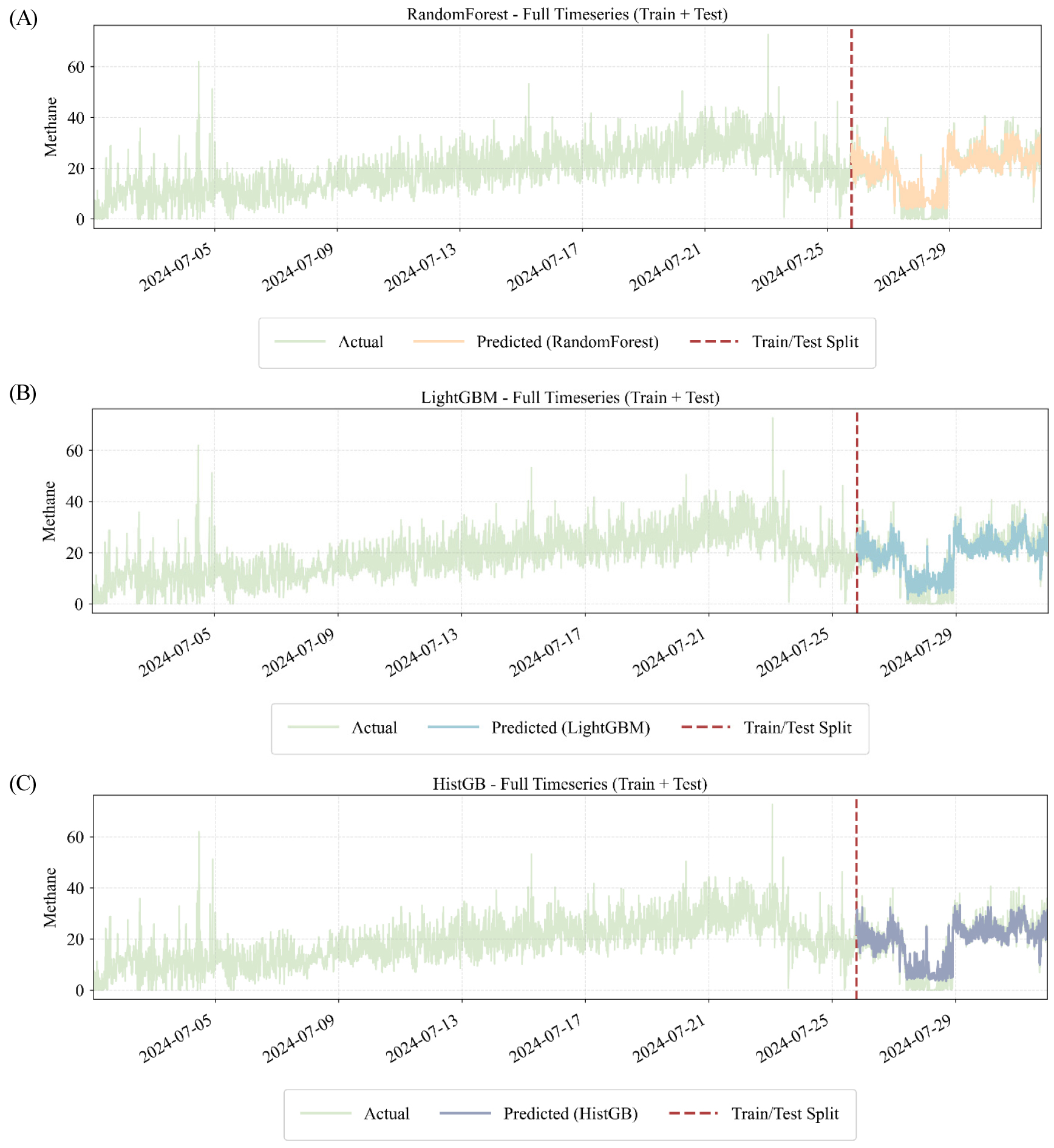
Fig. 8.
Full timeseries prediction of methane concentration (ppm) using RandomForest, LightGBM, and HistGB. The black line represents the actual methane values, while the blue lines show the predicted concentrations during the test period. The red dashed line indicates the split between training (80%) and testing (20%).
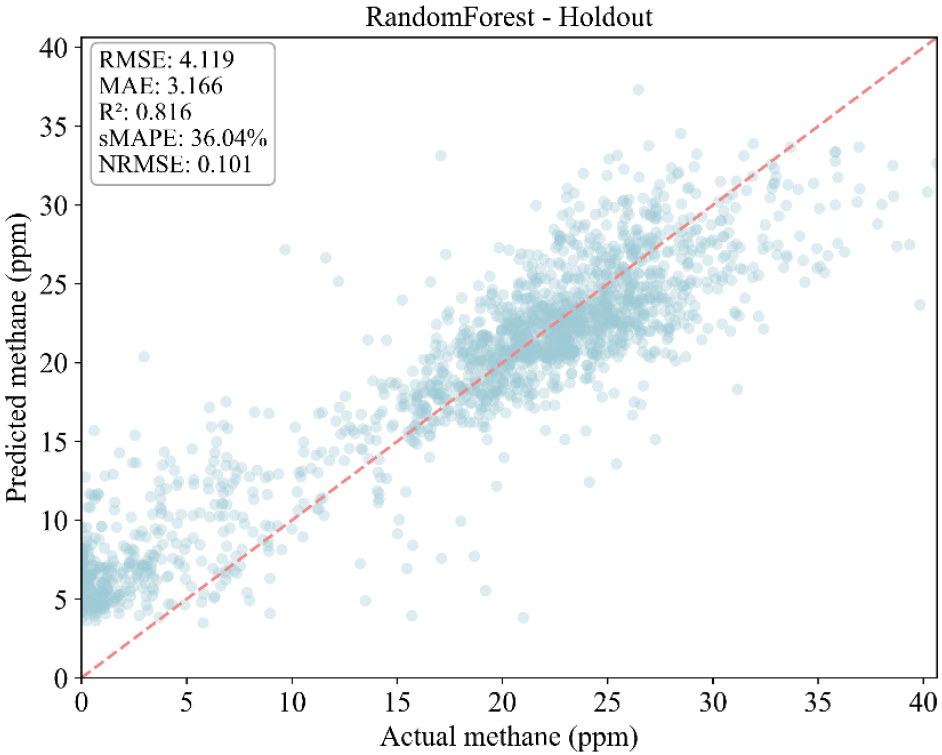
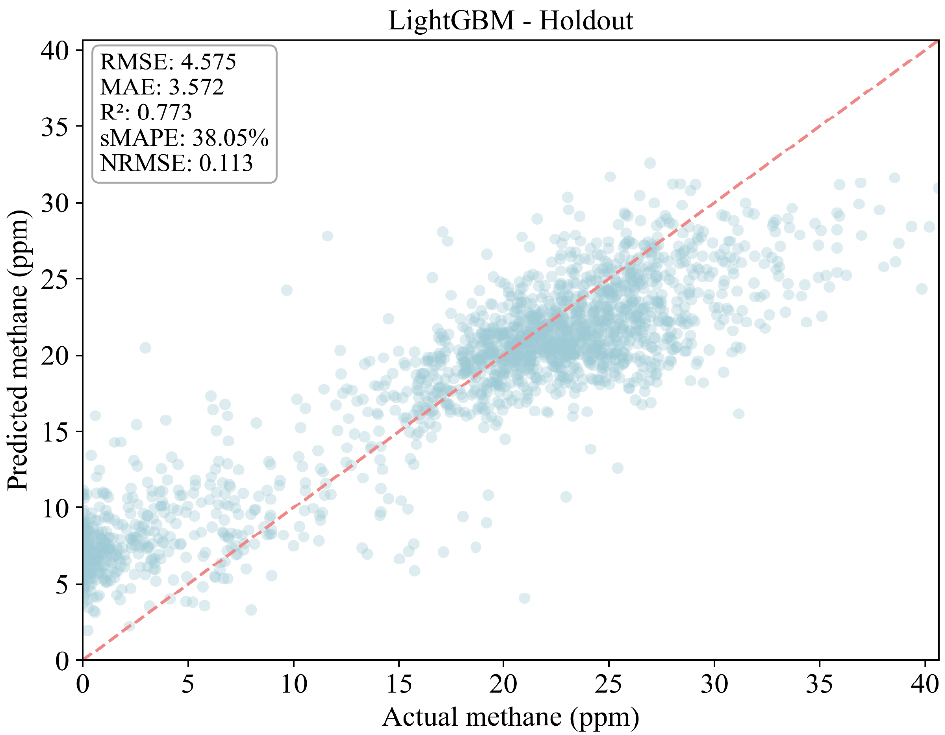
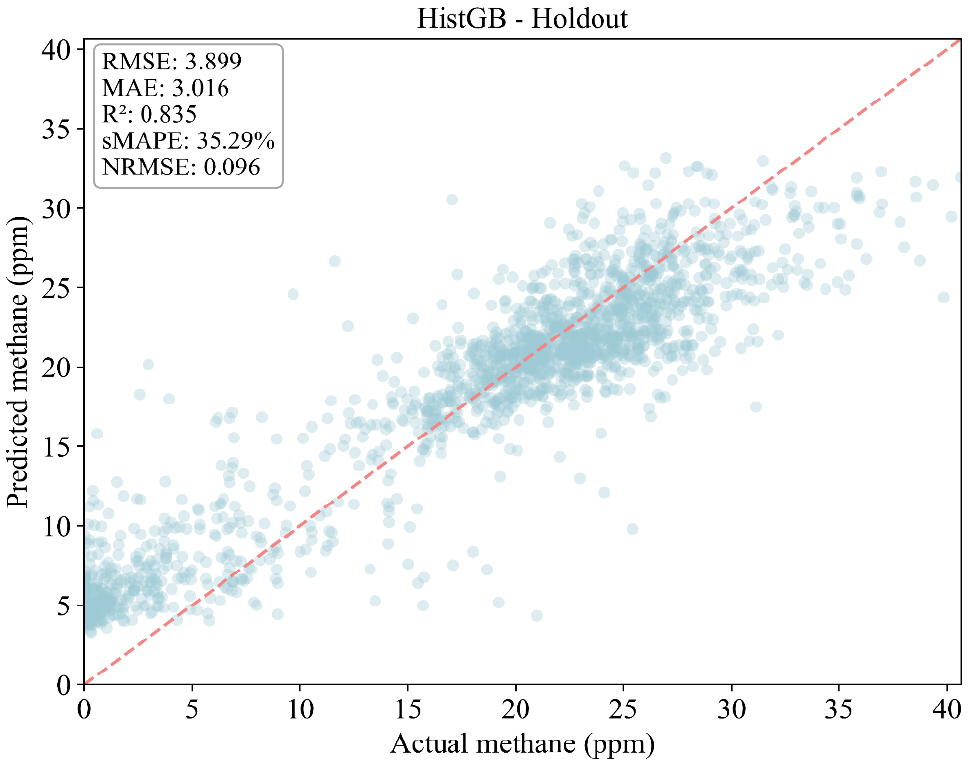
각 모델별 CH4 예측 성능을 비교하였으며, 비교결과와 선점도 그래프는 각 Table 5, Figs. 9, 10, 11에 표시하였다. 예측 결과 세가지 모델 중 HistGB이 가장 우수한 성능을 보였다. HistGB는 RMSE=3.90, MAE=3.02, R2=0.835로, 예측값과 실제값 간의 오차가 가장 적으며 가장 설명력이 높게 나타났다. 특히, 선점도 분석에서 y=x 기준선 주변에 밀집하는 양상을 보였으며, 이는 예측의 일관성과 정확성이 동시에 확보됨을 확인할 수 있었다. Random Forest는 RMSE=4.12, MAE=3.21, R2=0.812로 HistGB와 근접한 성능을 보였으나, 극단값 구간에서는 다소 높은 변동성을 보였다. 반면, Light GBM은 RMSE=5.23, MAE=3.87, R2=0.710으로 상대적으로 낮은 성능을 보였다. 산점도에서도 실제값 대비 예측값이 과소 또는 과대 추정되는 경향이 뚜렷하게 확인되었으며, 저농도 구간과 급격한 농도 상승 구간에서 점들이 기준선에서 크게 벗어나는 양상이 관찰되었다. 또한, 시계열 재현성을 분석한 결과 세 모델 모두 CH4 농도의 장기적인 추세는 안정적으로 포착하였으나, 극단적 저농도 구간이나 농도 급상승 구간에서는 공통적으로 평균 회귀 성향을 보여 예측값이 과소·과대되는 현상이 발생하였다.
Table 5.
Summary of detected anomalies by variable
| Model | RMSE | MAE | sMAPE | NRMSE | R2 |
| Random Forest | 4.119467 | 3.165597 | 36.03906 | 0.101415 | 0.812856 |
| LightGBM | 4.574818 | 3.572425 | 38.05288 | 0.112625 | 0.775986 |
| HistGB | 3.898821 | 3.015956 | 35.28553 | 0.095983 | 0.837632 |
4. 모델별 예측결과 해석 및 성능평가
양돈시설 CH4 발생에 영향을 미치는 주요 환경 요인과 예측 모델의 성능을 종합적으로 분석하였다. 분석 결과, CH4 농도는 분뇨의 산성도, 사료 섭취량, 그리고 CO2 및 NH3 농도와 밀접한 관련성을 보였다. 이러한 결과는 분뇨의 발효·분해 과정이 CH4 발생의 핵심 요인임을 설명한다. 산성도가 낮아질수록 CH4 생성 미생물의 활성이 억제되는 것은 널리 알려진 현상이며, 본 연구의 음의 상관결과와 일치하였다. 반대로 사료섭취량이 많을수록 분뇨 배출이 증가하고, 이에 따라 분뇨 내 유기물 부하가 높아져 발효가 활발해지고 CH4 생성이 촉진되어 양의 상관이 나타난 것으로 해석된다. 또한 CO2와 NH3는 분뇨 발효 및 환기 조건에 따라 동반 배출되는 특성이 있어 CH4과의 동시 변동성을 설명할 수 있다.
모델 성능 비교 결과, HistGB와Random Forest가 상대적으로 우수한 예측력을 보였으며, 이는 두 모델이 트리 기반 비선형 구조를 통해 CH4 발생 패턴의 복잡성을 효과적으로 반영했기 때문으로 판단된다. 특히 HistGB는 입력값을 구간 단위로 근사하는 히스토그램 기반 분할(histogram-based split)과 leaf-wise(잎 단위 성장)구조를 결합하여, 오차가 큰 국소 구간에서 세밀한 분할이 가능하였다. 이러한 구조는 센서 노이즈나 일시적 급변이 존재하는 본 연구의 시계열 데이터 특성과 잘 부합하며, 데이터의 불연속성과 잡음을 완화하면서 계산 효율성과 안정성을 동시에 확보할 수 있었다. 반면 Random Forest는 여러 결정트리의 평균화를 통해 예측의 분산을 낮추지만, 각 트리가 level-wise(수준별 분할) 로 성장하기 때문에 비선형적 급변 구간을 세밀하게 반영하는 데 한계가 있었다. 그 결과, 장기적 추세는 안정적으로 재현하였으나 극단값(급상승·급하강) 구간에서는 다소 큰 변동성을 보였다. LightGBM은 학습률이 낮고 정규화 강도가 높을 경우 상대적으로 작은 데이터셋에서 과소적합(underfitting)이 발생할 수 있으며, 특히 GOSS(Gradient-based One-Side Sampling)방식으로 데이터의 일부 손실을 감수하는 구조적 특성상, 급격한 CH4 변동 구간의 민감도가 다소 떨어지는 경향을 보였다. 이로 인해 LightGBM은 다른 모델 대비 예측이 다소 보수적으로 수렴하며, 저농도 구간에서 실제값을 과소 예측하는 패턴이 관찰되었다. 세 모델 모두 시계열의 장기적 추세는 안정적으로 재현하였으나, 극단적 저농도 구간이나 급격한 농도 상승 구간에서는 평균 회귀(regression-to-the-mean) 경향이 나타났다. CH4농도 변화가 온도·습도·급이량·환기량 등 환경 요인의 단기 상호작용에 비선형적으로 의존하기 때문으로 해석된다. 따라서 향후 연구에서는 이러한 급변 구간을 독립된 하위 패턴으로 분리하여 학습하거나, 시계열 기반 딥러닝 모델(LSTM, Temporal CNN 등) 과의 결합을 통해 환경변수 간 동태적 의존성을 반영함으로써 예측 정밀도를 향상시킬 필요가 있다. 종합적으로, HistGB는 히스토그램 기반 근사화로 센서 오차와 노이즈에 강건한 구조를 보여 제한된 양돈환경 데이터에서도 안정적인 예측력을 확보하였고, Random Forest는 평균화 효과로 장기 추세에 강점을, LightGBM은 효율성과 해석성 측면에서 우수한 특성을 보였다. 이러한 결과는 데이터 특성과 모델 구조 간의 적합성(model-data compatibility)이 CH4 예측 성능의 결정 요인임을 시사한다.
