

서 론
기후 변화와 인구 증가와 같은 요인으로 인해 글로벌 식량 안보에 대한 우려가 점점 커지고 있다. 전통적인 육종은 작물 수량 증대에 핵심적인 역할을 해왔으나, 현재의 도전과제를 해결하기 위해서는 첨단 기술의 도입이 필수적이다. 디지털 육종(Digital Breeding)은 유전자형–표현형 선택에 기반한 방법으로, 차세대 염기서열 분석(NGS)을 활용해 유전체 서열을 밝히고 다양한 표현형을 가진 개체에서 변이를 식별한다. 이러한 접근법은 특정 형질을 가진 개체를 유전자형 기반으로 선발하며, 작물의 생장, 수량, 내성, 품질 등 유전적 특성을 향상시키는 데 초점을 둔다.
기존의 전통적·분자육종 방법과 비교했을 때 디지털 육종은 가속화된 게놈 선택을 통해 작물 형질을 더 빠르고 정확하게 예측할 수 있다는 장점이 있으며, 이로써 육종 기간을 단축할 수 있다. 또한 디지털 육종은 교배 설계, 시험구 배치, 생육 모니터링, 선발 등 육종 과정 전반을 자동화하고, 환경 요인까지 고려한다. 유전자형 및 표현형 데이터를 수집·분석하여 최소한의 인적 개입으로도 작물 형질을 향상시키는 것을 목표로 한다(Jeon et al., 2023).
유전자형 데이터는 세포, 개체 또는 조직에서 발현되는 유전적 특성을 포함하며, 서열 분석이나 단일염기다형성(SNP)을 포함한다. 반면 표현형 데이터는 형태, 생장, 수량, 병 저항성, 내한성 등 관찰 가능한 특성을 포함한다. 전반적으로 디지털 육종은 전통적 육종에 비해 여러 가지 이점을 제공하며, 최근 연구자들은 머신러닝 기법을 적극적으로 탐구하여 다양한 분야에 적용하고 있다. 머신러닝과 딥러닝 기술이 발전함에 따라 작물 육종 연구는 점점 더 유전적 특성과 형질 간의 연관성을 이해하고 형질 예측 모델의 정확성을 향상시키는 데 주력하고 있다(Bayer et al., 2021; Danilevicz et al., 2022; Eggink et al., 2012; Fang et al., 2017).
AI 기반 접근법은 기존의 전장유전체연관분석(GWAS)이나 단순 표현형 예측 기법에 비해 작물 특성을 더 효율적이고 정확하게 예측할 수 있다. 앞으로 육종 과정은 기후와 지형에 적합한 집단을 선발하는 방향으로 나아가, 환경에 더 잘 적응하는 작물을 개발할 수 있을 것으로 기대된다. 이는 품종 개발의 정밀화, 작물 생산성 증대, 자원 활용 최적화, 유전적 다양성 보존 등 농업 전반에 걸쳐 중요한 이점을 제공한다. 그러나 선택된 SNP를 이용해 고정 효과를 반영하고 표현형 예측 정확도를 높이는 연구는 아직 제한적이며, 실제 육종 환경에서 이를 검증하는 시도 역시 부족하다(Jeon et al., 2023).
최근에는 무어의 법칙을 뛰어넘는 수준으로 발전한 시퀀싱 기술 덕분에 유전체 서열 데이터 접근성이 크게 확대되었다. 그럼에도 불구하고, 대규모 데이터셋이 요구되는 현대 AI 기반 분석을 위해 충분한 유전체 데이터를 수집하는 것은 여전히 비용이 크고 실용적이지 않다. 여러 연구에서 딥러닝 기법이 유전체 데이터 내 상호작용을 포착하는 데 뛰어나며, 유전자형–표현형 관계를 예측하는 데 기존 생물정보학적 접근보다 우수하다는 점이 확인되었다(Kim et al., 2022; Khan et al., 2022; Yoosefzadeh-Najafabadi et al., 2022). 이러한 한계를 극복하기 위해서는 데이터의 양과 다양성을 동시에 확대하는 데이터 증강 기법의 활용이 필수적이다(Yang et al., 2010). 딥러닝 기반 데이터 증강은 컴퓨터 비전 분야에서 활발히 연구되어 성공적으로 적용된 바 있으며(National Human Genome Research Institute, 2024), 특히 적대적 생성 신경망(GAN) 기법은 데이터 생성 품질을 크게 개선해왔다(Eggink et al., 2012; Goodfellow et al., 2014; Khan et al., 2022; Marouf et al., 2020).
그러나 게놈 데이터는 이미지 데이터와 달리 표본 수가 적고 희소하며 차원이 높다는 특성이 있어, GAN과 그 변형 모델이 실제로 효과적인지 여부는 여전히 불확실하다. 따라서 게놈 데이터에 적합한 새로운 평가 지표 개발과 증강된 데이터가 기존 모델의 정확도를 개선할 수 있는지 검증하는 과정이 필요하다.
이에 본 연구에서는 제한된 데이터 환경에서의 표현형 예측 성능을 향상시키기 위해 유전자형 데이터 증강 기법을 제안하고, 이를 반지도학습(semi-supervised learning) 기반 표현형 예측 모델과 결합하였다. 또한 토양 수분, 온도, 습도 등 주요 환경 요인을 센서를 통해 실시간으로 수집·분석함으로써, 환경 변수가 유전자형–표현형 관계에 미치는 영향을 통합적으로 고려하였다. 기존의 생성자-판별자 구조에 의존하는 전통적 GAN 방식 대신, 본 연구에서는 CNN과 LSTM 계층을 적층한 아키텍처를 설계하여 SNP 위치 데이터를 입력으로 받아 인접 유전체 영역 간 상관관계를 효과적으로 학습할 수 있도록 하였다. 더불어 증강 데이터의 품질을 정량적으로 평가하기 위해, 비전 분야에서 흔히 사용되는 Turing Test나 Fréchet Inception Distance(FID)와 같은 지표 대신, SNP 발생 확률과 인접 영역의 발생 가능성을 반영한 새로운 평가 지표를 도입하였다. 나아가 Cropformer, MHA, Mamba, MTL, MI 기반 MHA 등 다양한 아키텍처를 적용한 비교 실험을 수행함으로써 제안 기법의 범용성과 한계를 함께 분석하였다.
딥러닝 기반의 표현형 예측 모델
1. 환경 데이터 수집
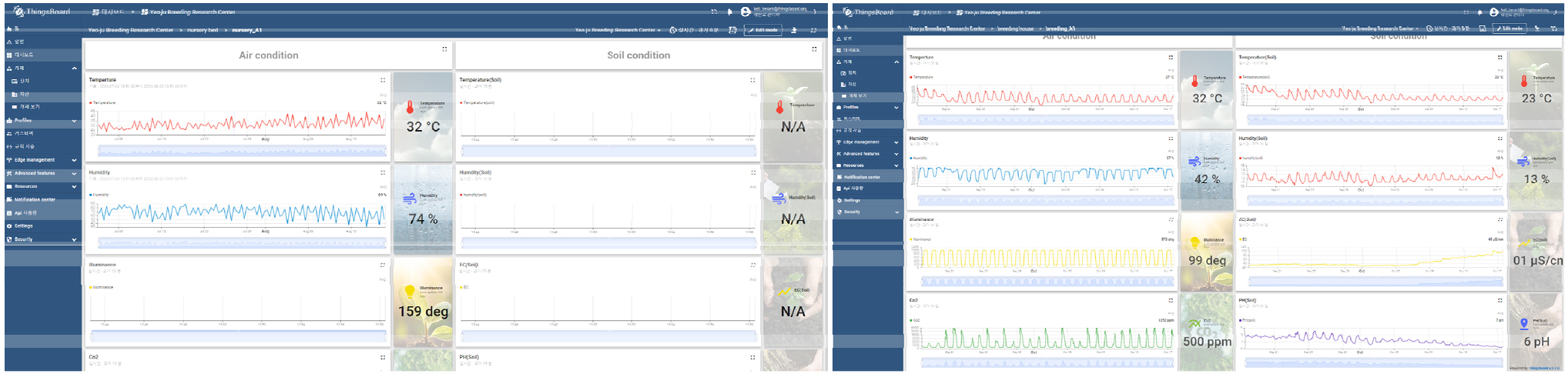
본 연구에서는 유전체 및 표현형 데이터와의 연계를 위해 테스트베드 기반 환경 데이터 수집 체계를 구축하였다. WiFi 기능이 내장된 아두이노 R4 보드를 활용하여 센서 기반 환경 데이터 수집 모듈을 개발하였다. 해당 모듈은 육묘장과 정식 온실에 설치되었으며, 이를 통해 다양한 대기 및 토양 환경 인자를 실시간으로 측정하였다. 육묘장에서는 온도와 습도를 측정하였고, 정식 온실에서는 대기 환경(온도, 습도, 조도, CO2)과 토양 환경(pH, EC, 온도, 습도)을 동시에 수집하였다. 환경데이터 수집 모듈과 온실에 설치된 모습은 Fig. 1과 같다.

수집된 데이터는 IoT 플랫폼 Thingsboard를 통해 실시간으로 전송·시각화되었으며, 각 센서는 UUID를 부여받아 데이터 구분 및 추적 관리가 가능하도록 설계하였다. 또한 데이터는 PostgresDB에 저장되어 장기적인 분석과 모니터링이 가능하도록 하였으며, 농우바이오에서 시험 중인 토마토 종자를 대상으로 환경 데이터 수집을 한 작기 동안 진행하였다. 구축된 웹 기반 대시보드를 통해 수집 데이터의 실시간 모니터링이 가능함을 확인하였다. 환경데이터의 실시간 수집 모습은 Fig. 2와 같다.
수집된 시계열 환경 데이터는 표현형 예측에 활용하기 위해 전처리 과정을 거쳐 유전형·표현형 데이터와 통합하였다. 우선 센서별 데이터를 시간 단위로 집계하고 결측값은 선형 보간으로 보완하였다. 이후 생육 기간 전반에 대해 대표 통계값(평균, 표준편차, 최대값, 최소값)을 추출하여 각 데이터의 환경 특성을 요약하였다. 센서별 데이터는 Z-score 표준화를 통해 정규화하여 스케일 차이를 제거하였다. 이렇게 생성된 대표 통계값은 유전형 및 표현형 데이터와 개체 단위로 결합되어 최종 예측 모델의 입력 변수로 사용되었다. 이를 통해 생육 환경이 표현형에 미치는 영향을 정량적으로 반영할 수 있도록 하였다.
2. 유전형-표현형 데이터 세트
토마토(Solanum lycopersicum L.)는 영양학적 가치로 인해 전 세계적으로 수요가 높은 작물이다. 2023년 전 세계 토마토 생산량은 약 1억 9천만 톤에 달했으며, 이는 토마토를 세계적으로 가장 많이 소비되는 채소 중 하나로 자리매김하게 하였다. 또한 토마토는 과실의 형태, 크기, 무게 등에서 상당한 유전적 다양성을 보인다. 이러한 경제적 중요성 때문에 토마토 육종에 관한 연구는 활발히 진행되어 왔다.
본 연구에서는 한국 세종대학교 바이오자원공학과에서 제공한 유전자형 및 표현형 정보를 포함한 두 가지 토마토 데이터셋을 활용하였다(Khan et al., 2022; Kim et al., 2021). 학습 집단은 현대 육종계통, 전통 품종, 야생종을 아우르는 총 192종의 토마토 핵심 품종으로 구성되었다. 분석된 형질은 과실 무게, 높이, 너비, 경도, 당도(브릭스) 등 5가지였다. 유전자형 분석에는 Genotype-by- Sequencing(GBS) 기법이 사용되었으며, 192 품종에서 총 140,072개의 단일염기다형성이 확인되었다. 이후 전장유전체연관분석을 수행하였고, 결측치 비율 20% 미만 및 최소 대립유전자 빈도 5% 이상이라는 기준을 적용하여 최종적으로 8,550개의 SNP를 선별하였다(Kim et al., 2021).
유전자형(genotype) 데이터는 아데닌(adenine), 시토신(cytosine), 티민(thymine), 구아닌(guanine)을 나타내는 네 가지 DNA 염기(A, C, T, G)로 구성된다. 이 데이터를 머신러닝 모델에 활용하기 위해서는 전처리 과정에서 정수로 변환해야 한다. 예를 들어, 같은 염색체 상에 있는 두 개의 이형접합 대립유전자 좌위를 가진 이배체 생물의 경우, A 또는 T 대립유전자가 존재하는 좌위에서는 세 가지 가능한 유전자형(AA, AT, TT)이 나타나며, G 또는 C 대립유전자가 존재하는 좌위에서는 GG, GC, CC의 유전자형이 형성된다. 각 유전자형 조합은 정수값으로 할당되는데, 예를 들어 AA=0, AC=1, AG=2와 같이 부여된다. 유전형과 표현형 데이터의 예시는 Table 1과 같다.
Table 1.
Example of Crop Genotype and Phenotype Data
표현형 데이터는 연속적인 실수 값으로 구성되며, 그 특성상 복잡하고 이상치가 존재할 수 있어 예측 정확도에 영향을 미칠 수 있다. 이를 해결하기 위해 본 연구에서는 데이터를 단순화하여 특정 구간으로 구분하였다. 다섯 가지 표현형 형질(과실 무게, 높이, 너비, 경도, 당도)에 대해서는 데이터 분포를 세 가지 범주로 나누어 분석을 수행하였다.
3. 유전형-표현형 데이터 생성
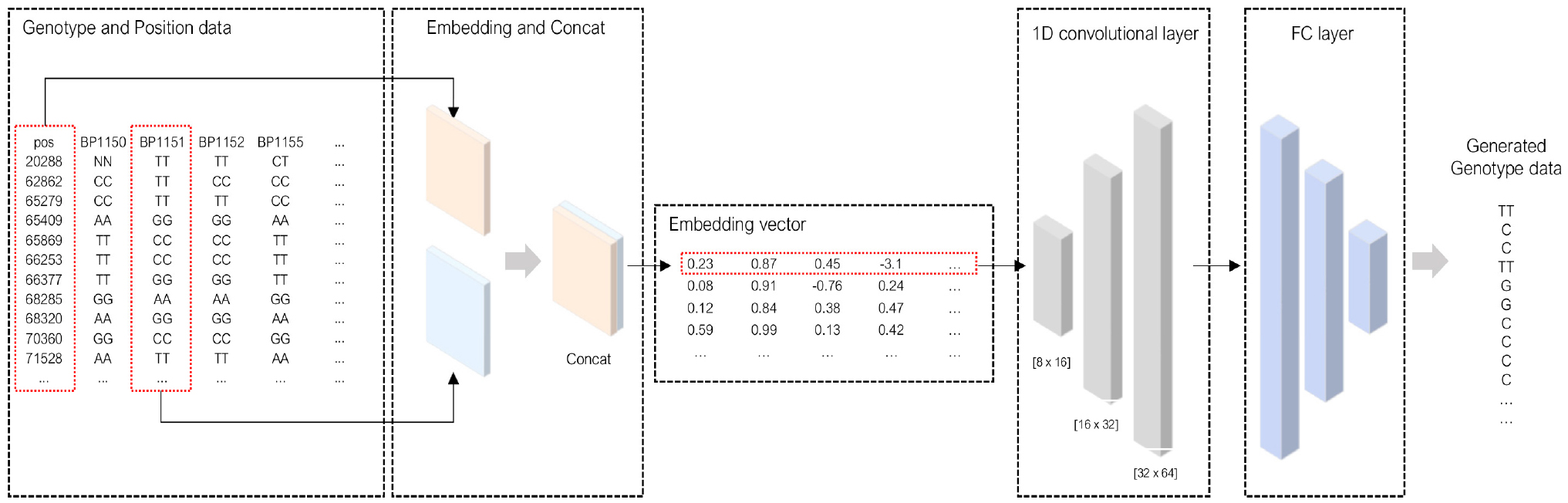
유전자형 유전자형 본 연구에서는 표현형 예측 성능 향상을 위해 1차원 합성곱 신경망(1D Convolutional Neural Network, CNN) 기반 유전자형 데이터 생성 모델을 제안한다. 본 모델은 작물의 유전체 정보를 활용하여 유전자형 데이터를 효율적으로 생성하고, 정확한 표현형 예측에 필수적인 주요 특징을 추출한다. 제안된 모델은 유전자형 서열 정보와 유전자 위치 정보 두 가지를 입력으로 받아, 임베딩 계층과 합성곱 계층을 통해 이러한 입력을 처리함으로써 유전자형 데이터 내의 복잡한 패턴과 상관관계를 학습한다.
먼저, 유전자형 서열 정보와 위치 정보가 임베딩 계층에 입력되어 고차원 표현으로 변환된다. 이 과정에서 임베딩 계층은 각 유전자 위치의 유전자형 정보를 고차원 벡터로 변환하여 데이터의 복잡한 구조를 효과적으로 포착한다. 변환된 데이터는 이후 1차원 합성곱 계층과 완전연결 계층을 거치며 점진적으로 의미 있는 특징을 추출한다. 1차원 합성곱 계층은 입력 데이터의 지역적 특징을 포착하는 데 특화되어 있으며, 완전연결 계층은 전역적 특징을 학습하여 전체적인 특징 표현을 강화한다. 제안하는 유전형 데이터 생성 모델은 Fig. 3과 같다.
여러 개의 합성곱 계층을 활용함으로써 모델은 복잡한 패턴을 효과적으로 학습하고, 유전자형 데이터 내 중요한 지역 구조를 포착할 수 있다. 추출된 고차원 특징은 글로벌 평균 풀링을 통해 저차원 특징으로 압축된다. 이 단계는 모델의 복잡성을 줄이고 과적합을 방지하며, 데이터 전반의 패턴 학습을 용이하게 한다. 특히 글로벌 평균 풀링은 고차원 벡터를 일반화된 특징으로 압축함으로써, 데이터 샘플 수가 제한적인 상황에서도 안정적인 성능을 유지하도록 돕는다. 제안된 모델은 유전자형 서열 정보와 유전자 위치 정보를 동시에 입력으로 받아, 임베딩 계층과 합성곱 계층을 통해 복잡한 패턴을 학습함으로써 실제 데이터의 통계적 특성을 유지하면서도 다양한 패턴을 반영한 새로운 유전자형 샘플을 확보할 수 있다. 모델의 전체 구조는 Fig. 2와 같다. 증강된 데이터는 원본 데이터와 동일한 형식으로 정규화 및 전처리 과정을 거치며, 유전형 데이터 단위로 데이터 분할이 이루어져 단순한 중복이 아닌, 예측 성능 개선에 기여하는 학습 신호로 작용하도록 설계하였다.
생성된 유전자형 데이터의 타당성을 검증하기 위해 두 가지 기준을 설정하였다. 첫번째로, 기존 데이터에서 각 위치별 염기쌍(base pair)의 발생 확률을 계산하였다. 두번째로, 이를 바탕으로 생성된 유전자형 데이터의 각 위치별 평균 발생 확률을 산출하여 기존 데이터와 비교하였다. 이에 대한 결과는 Table 2에 제시되어 있으며, 제안 모델을 포함한 다양한 모델들의 타당성 성능을 비교하였다.
Table 2.
The validity performance across different models
| Model | Performance |
| Vanilla GAN | 0.008 |
| Conditional GAN | 0.007 |
| RNN | 0.001 |
| LSTM | 0.003 |
| PG-cGAN (Junjie et al., 2020) | 0.011 |
| Proposed | 0.78 |
실험 결과, 대부분의 모델은 데이터셋에 존재하는 특성과 패턴을 정확히 반영하는 데이터 생성을 수행하는 데 어려움을 보였다. 이로 인해 특정 위치에서 실제 데이터에는 존재하지 않는 SNP가 생성되는 문제가 발생하였다. GAN 기반 모델의 경우 최종 위치까지 다양한 SNP를 생성하였으나, 위치별 SNP 분석 결과 데이터 고유의 특성을 반영하지 못하는 한계가 확인되었다. 또한 RNN 계열 모델은 학습이 수렴하지 않고 손실 함수가 발산하거나 긴 서열을 생성하는 과정에서 동일한 SNP 패턴을 반복적으로 산출하는 경향을 보였다. 이는 장기 의존성을 포착하고 재현하는 데 있어 RNN 모델의 한계를 보여준다.
반면, 본 연구에서 제안한 모델은 입력 단계에서 유전자 좌위 정보를 효과적으로 반영함으로써, 각 위치별 SNP를 보다 정확하게 재현하는 결과를 도출하였다. 이는 제안 모델이 기존 기법들에 비해 실제 유전적 구조와 패턴을 충실히 반영할 수 있음을 시사한다.
4. 표현형 예측 모델
본 절에서는 생성된 유전자형 데이터의 효과성을 검증하기 위해 수행한 표현형 예측 실험 방법을 제시한다. 이를 통해 제안된 유전자형 데이터 생성 모델이 표현형 예측 향상에 기여하는 중요성을 검증한다. 일반적으로 유전자형 및 표현형 데이터는 재배 과정을 통해 수집되므로, 연구에 충분한 크기와 복잡성을 갖춘 데이터셋을 확보하는 데 어려움이 따른다. 본 연구에서는 1D CNN 기반 데이터 증강 기법을 적용하여 유전자형 데이터를 보완하였으나, 전체 샘플 수는 여전히 제한적이다. 이러한 데이터 부족 상황에서 모델의 복잡도가 지나치게 높을 경우 과적합 위험이 커질 수 있다. 이에 따라 본 연구에서는 심층 신경망 기반 접근법 대신, 상대적으로 단순하고 안정적인 머신러닝 모델을 활용하여 예측 성능을 평가한다. 회귀 태스크에서는 총 18종의 머신러닝 모델을 적용한다. 트리 기반 모델에는 Decision Tree(DT), Extra Trees(ET), Gradient Boosting(GB), Extreme Gradient Boosting(XG), Light Gradient Boosting Machine(LGBM), CatBoost(CAT), AdaBoost(ADA)가 포함되었다. 선형 모델에는 Linear Regression (LR), Lasso(LASSO), Elastic Net(EN), Lasso Least Angle Regression(LLAR), Least Angle Regression, Bayesian Ridge(BR)를 사용하였다. 이외에도 기타 모델로 Orthogonal Matching Pursuit, Passive-Aggressive Regressor(PAR), Dummy Regressor, Huber Regressor(HUBER), K-Neighbors (KNN)를 활용한다. 이러한 다양한 모델을 적용함으로써, 데이터 특성에 따른 성능 차이를 비교·분석하고 제안된 데이터 증강 기법의 효과성을 다각적으로 검증한다. 본 연구에서 사용한 원본 유전자형 데이터는 총 162개를 대상으로 수집된 SNP 데이터이며, 각각에 대해 5개 주요 표현형(과중, 과고, 과폭, 경도, 당도)을 확보하였다. 데이터 증강은 1D CNN 기반 생성 모델을 통해 수행되었으며, 원본 샘플 대비 약 6배 규모(원본 162건, 증강 1,000건)의 데이터를 추가 생성하였다. 데이터 분할 시에는 유전형 기준으로 학습, 검증, 테스트 세트를 나누어, 동일 샘플이 여러 세트에 포함되지 않도록 하였다. 학습, 검증, 테스트 비율은 6:2:2이며, 랜덤 시드를 고정한 상태에서 표현형 분포를 유지할 수 있도록 stratified split 방식을 적용하였다. 이러한 방식은 일반화 성능을 공정하게 평가하기 위해 적용하였다.
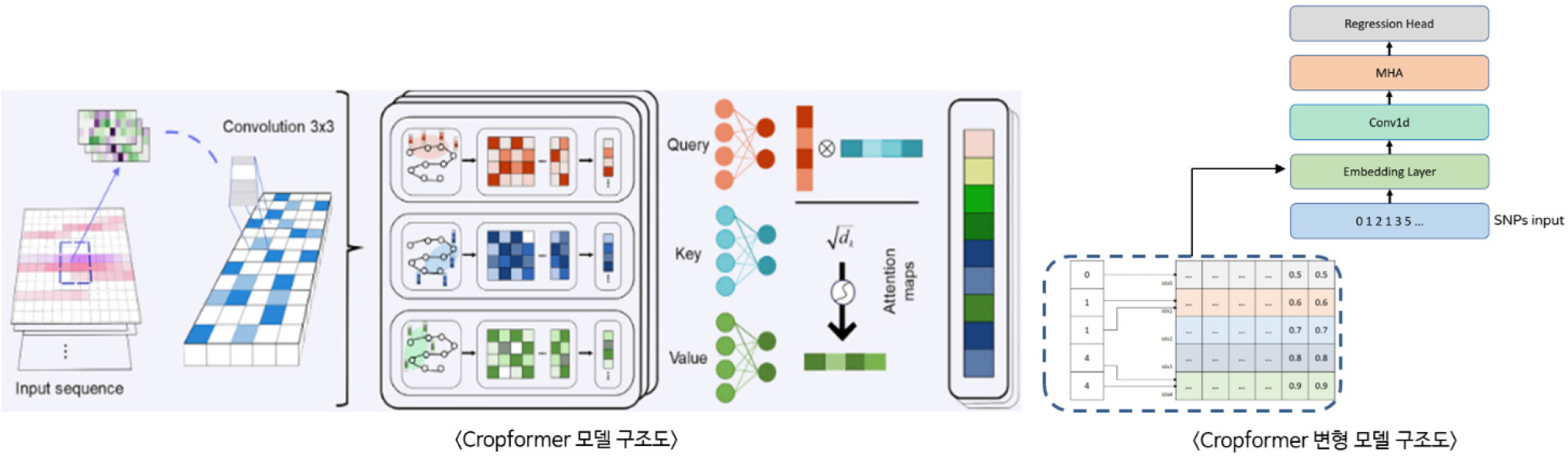
최근 표현형 예측 연구는 다양한 딥러닝 아키텍처를 중심으로 발전해 왔다. DNNGP(Wang et al., 2023)는 다층 CNN 구조와 배치 정규화, 드롭아웃, 조기 종료 기법을 통해 과적합을 방지하고 학습 효율을 높여 기존 GRBLUP, SVR, LightGBM, DeepGS 등보다 우수한 예측 성능을 달성하였으며, 대규모 데이터에서도 계산 효율성이 뛰어난 모델로 평가된다. GPformer(Zhu et al., 2025)는 트랜스포머 기반 구조에 GWAS로부터 도출된 통계적 사전지식을 반영하여 장기 SNP 의존성을 학습함으로써 유전자–표현형 관계 모델링을 강화하였고, Cropformer(Wang et al., 2025)는 CNN과 다중 셀프어텐션을 결합하여 옥수수, 쌀, 밀, 토마토 등 다양한 작물에서 예측 정확도를 향상시키는 동시에 SNP 중요도 시각화와 해석 가능성을 제공하였다. MtCro(Chao et al., 2025)는 멀티태스크 러닝을 통해 표현형 간 상관관계를 동시에 학습하여 단일 학습 대비 2-3% 향상된 정확도와 자원 효율성을 달성하였으며, 추가적으로 Conv1D와 Multi-Head Attention(MHA) (Cordonnier et al., 2020)를 결합한 변형 모델은 지역적 특징과 전역적 관계를 순차적으로 학습하여 성능 향상에 기여하였다. 이외에도 본 연구에서는 간단한 MHA 기반 모델을 적용하여 표현형 예측 과정에서 어떤 SNP가 중요한지 해석할 수 있는 가능성을 검토하고, Mamba(Gu and Dao, 2023) 아키텍처를 활용해 긴 시퀀스 데이터 처리 효율성을 높이며 MHA와 결합한 하이브리드 구조의 성능을 탐색한다.
본 연구에서는 데이터 증강을 통해 생성된 유전형 데이터의 활용 효과와 더불어, 최신 딥러닝 모델의 구조적 변화를 통한 성능 향상 효과도 함께 검증하였다. 이를 위해 기본적인 CNN 기반 모델을 기준선으로 설정하고, Attention mechanism, CNN-LSTM 복합 구조, Mamba 기반의 sequence 처리 구조 등을 적용하여 예측 성능의 변화를 분석하였다. 또한 사전지식(Mutual Information, MI) 점수를 사전지식으로 활용하는 모델을 실험에 포함시켜, 데이터가 제한된 환경에서 일반화 성능을 향상시킬 수 있는 가능성을 평가하고자 한다. 본 논문에서 제안하는 Cropformer의 변형 구조는 다음 Fig. 4와 같다.
5. 실험 결과
본 연구에서는 육종 계통, 전통 품종, 야생종을 포함한 162종의 토마토 핵심 집단을 대상으로 학습용 및 검증용 집단을 구성하였다. DNA 서열 변이를 확인하기 위해 유전자형 데이터를 수집하였으며, 과실 형태, 색상, 과피 두께, 높이, 너비 등의 형질에 대한 표현형 데이터도 함께 확보하였다. 유전자형 데이터의 다양성을 보완하기 위해 학습 및 검증 단계에서 1차원 합성곱 신경망을 적용한 데이터 증강을 수행하였다. 제안된 데이터 증강 기법의 효과성은 머신러닝 모델을 활용한 표현형 예측 실험을 통해 검증하였으며, 증강 전후의 예측 성능을 비교·분석하였다.
본 실험에서는 과실 무게, 너비, 높이, 경도, 당도(brix) 등 다섯 가지 표현형 형질을 대상으로, 원본 유전자형 데이터와 증강된 유전체 데이터를 활용하여 총 18종의 회귀 모델을 적용한 예측 성능을 평가하였다. 각 형질별로 증강 기법의 효과를 검증하기 위해 R2 점수(R2 score), 평균 절대 오차(mean absolute error, MAE), 평균 제곱근 오차(root mean squared error, RMSE)의 세 가지 지표를 사용하여 성능을 비교·분석하였다.
Table 3에 보이는 것과 같이, 데이터 증강은 전반적으로 모델 성능 향상에 기여하였다. 특히 EN, ADA, CAT 모델은 여러 형질에서 R2 점수 상승과 MAE 및 RMSE 감소라는 뚜렷한 경향을 보였다. 과중(Weight) 및 과폭(Width) 형질에서는 BR과 LR 모델이 증강 데이터의 적용으로 예측 성능이 크게 개선되었으며, 과고(Height) 형질의 경우 LR, Ridge, BR 모델이 유사한 성능 향상을 나타냈다. 당도(Brix) 형질에서는 ADA와 CAT 모델이 증강 데이터 적용을 통해 높은 R² 점수와 낮은 오차(MAE 및 RMSE)를 기록하며 두드러진 성능 개선을 달성하였다. 반면, 경도(Firmness) 형질에서는 성능 향상이 상대적으로 제한적이었으나 일부 모델에서는 여전히 개선 효과가 관찰되었다. 이러한 결과는 유전자형 데이터 증강이 다양한 형질에서 예측 성능을 향상시키는 효과적인 접근법임을 보여주며, 특히 특정 모델에서 그 효과가 두드러지게 나타남을 시사한다.
Table 3.
The validity performance across different models
또한, 본 연구에서는 다양한 모델을 적용하여 SNP 기반 표현형 예측 성능을 비교·분석하였다. 실험 결과는 Table 4에 보여준다. 먼저, Cropformer 모델은 SNP 입력에 Conv1D 연산을 적용하여 지역적 특징을 추출하고, 이를 MHA 계층에 전달하여 전역적 관계를 학습하는 구조를 사용하였다. 해당 모델은 평균 성능 0.873을 기록하였으며, 입력 계층에서 SNP를 고차원 벡터로 투영한 후 MHA 계층에 전달하는 변형 구조에서는 평균 성능이 0.8752로 소폭 향상되었다. 이는 지역적 특징과 전역적 관계를 순차적으로 결합하는 전략이 효과적임을 보여준다. 한편, MHA 단독 모델은 임베딩 계층 위에 단순히 MHA 계층만을 적용하였음에도 불구하고 평균 성능 0.875를 기록하였다. 이는 Cropformer보다는 낮은 성능을 보였으나, 비교적 단순한 구조만으로도 높은 예측 성능을 달성할 수 있음을 보여주었다. Mamba 아키텍처는 긴 시퀀스 데이터 처리 효율성을 개선한 모델로, 기본 구조는 평균 성능 0.8476을, Mamba4Rec 구조는 0.7998를 기록하였다. CNN 기반 모델(0.886)에는 미치지 못했으나, Mamba와 MHA를 결합한 하이브리드 모델은 평균 성능 0.8526를 달성하여 Mamba의 효율성과 MHA의 SNP 중요도 학습 능력이 상호 보완적으로 작용함을 확인하였다. 또한, 멀티태스크 러닝(MTL) 기반 모델은 여러 표현형을 동시에 예측하기 위해 1D Conv 계층을 거친 후, 각 표현형별로 독립적인 MHA 계층을 적용하는 구조를 채택하였다. 그러나 평균 성능은 0.8446으로, 딥러닝 모델 중에서는 상대적으로 낮게 나타났다. 이는 여러 작업을 동시에 학습하는 과정에서 특정 표현형 예측 성능이 저하되는 현상을 보여준다. 마지막으로, MI 기반 MHA 모델은 각 SNP의 MI 점수에 학습 가능한 가중치를 적용하여 입력에 통합하였다. 이 모델은 평균 성능 0.8722을 기록하였으며, 데이터가 제한된 환경에서 일반화 성능을 높일 가능성을 확인하였다. 다만, 성능 향상 폭은 제한적이었는데, 이는 어텐션 기반 모델 자체가 이미 데이터로부터 SNP의 중요도를 효과적으로 학습하고 있음을 시사한다.
Table 4.
The validity performance across different models
| Model | Weight | Width | Height | Firmness | Brix | Average |
| CNN based | 0.922 | 0.805 | 0.92 | 0.917 | 0.869 | 0.8866 |
| Mamba (Gu and Dao, 2023) | 0.915 | 0.62 | 0.926 | 0.899 | 0.878 | 0.8476 |
| Mamba4Rec | 0.85 | 0.611 | 0.866 | 0.829 | 0.843 | 0.7998 |
| Mamba + MHA | 0.911 | 0.723 | 0.862 | 0.907 | 0.86 | 0.8526 |
| Parallel Model | 0.901 | 0.701 | 0.901 | 0.894 | 0.85 | 0.8494 |
| MTL (Chao et al., 2025) | 0.842 | 0.764 | 0.884 | 0.898 | 0.835 | 0.8446 |
| MHA (Cordonnier et al., 2020) | 0.923 | 0.745 | 0.928 | 0.92 | 0.861 | 0.8754 |
| CNN + MHA | 0.92 | 0.744 | 0.91 | 0.931 | 0.86 | 0.873 |
| EMB+CNN+MHA (Wang et al., 2025) | 0.914 | 0.752 | 0.911 | 0.933 | 0.866 | 0.8752 |
| Mutual Information | 0.92 | 0.757 | 0.917 | 0.912 | 0.855 | 0.8722 |
결과 및 고찰
본 연구에서는 새로운 유전자형 데이터 증강 기법과 반지도학습 기반 표현형 예측 모델을 제안하였다. 기존의 전통적 GAN 구조 대신 합성곱 계층과 LSTM 계층을 적층한 프레임워크를 설계하여, 인접 유전체 영역 간의 상관관계를 보다 정밀하게 포착할 수 있도록 하였다. 또한, 생성된 유전자형 데이터의 품질을 평가하기 위해 SNP 발생 확률에 기반한 새로운 지표를 도입하였다. 제안된 모델은 192종의 토마토 핵심 집단을 활용한 실제 육종 시나리오에서 검증되었으며, 농업 분야에서의 실질적 적용 가능성을 확인하였다. 실험 결과, 제안된 유전자형 데이터 생성 모델은 기존 GAN 기반 모델 대비 데이터의 고유 특성을 더욱 효과적으로 반영하였고, 표현형 예측 실험에서도 데이터 증강을 통해 다양한 형질에서 예측 성능이 유의미하게 향상됨을 확인하였다.
더 나아가, Cropformer, MHA, Mamba, MTL 및 MI 기반 MHA 모델 등 다양한 아키텍처를 적용한 실험을 통해 제안 기법의 효과성을 다각도로 검증하였다. Cropformer는 Conv1D와 MHA의 순차적 결합을 통해 지역적·전역적 특징을 동시에 학습하여 평균 성능 0.8701-0.8716을 달성하였고, 단순 MHA 모델 또한 평균 성능 0.8642로 높은 예측력을 보이며 SNP 해석 가능성이라는 장점을 제시하였다. Mamba 아키텍처는 긴 시퀀스 처리 효율성을 보여주었으며, MHA와 결합한 하이브리드 모델은 성능을 보완적으로 향상시켰다. 반면 MTL 모델은 다중 형질을 동시에 학습하는 과정에서 성능 저하가 발생하였고, Mutual Information 기반 MHA 모델은 데이터 부족 환경에서 일반화 가능성을 보였으나 향상 폭은 제한적이었다. 또한, 경도 형질의 예측 성능 향상 폭이 다른 표현형에 비해 상대적으로 낮게 나타났는데, 경도가 측정 과정의 변동성, 유전력의 상대적 낮음, 그리고 환경 요인의 민감한 영향을 받는 형질이기 때문으로 해석된다. 경도는 과실의 부위, 수확 시기, 측정 압력 등에 따라 값이 달라질 수 있으며, 동일한 개체더라도 생육 환경의 미세한 차이에 의해 변동성이 커질 수 있다. 이러한 점은 향후 환경 요인을 보다 정밀하게 반영하거나 비유전적 요인을 고려하는 다중 입력 모델의 필요성을 시사한다.
데이터가 제한된 상황에서는 딥러닝 모델 구조 자체의 신규성에는 본질적인 한계가 존재한다. 이러한 특성은 곧 모델의 구조적 참신성보다는 데이터의 특성, 전처리 및 통합 방식 등 데이터 중심 전략이 예측 성능에 더 결정적인 영향을 미친다는 점을 시사한다. 따라서 본 연구에서는 모델 구조의 절대적 우위를 주장하기보다 기존의 대표적인 모델을 포함한 다양한 아키텍처를 동일한 조건에서 비교 및 분석하는 접근을 택하였다. 향후 연구에서는 이러한 모델 구조의 차이에 따른 성능 기여도를 보다 명확히 규명하기 위해 모델 구조에 대한 Ablation 실험 및 다양한 데이터 처리에 대한 연구를 수행할 예정이다. 이를 통해 모델의 구조적 특성과 데이터 특성 간 상호작용을 정량적으로 분석하고, 실제 육종 환경에서의 적용 가능성을 보다 구체적으로 검증하고자 한다.
