

서 론
재료 및 방법
1. 공시작물 및 재배환경측정
2. 마늘의 생육 및 생리 특성 조사
3. 통계 분석 및 기계학습 모델
결과 및 고찰
1. 재배환경에 따른 마늘의 생육 분석
2. 기계학습을 활용한 마늘 생체중 모델 비교
서 론
마늘(Allium sativum L.)은 주요 양념 채소로써 대한민국에서 소비가 많은 작물 중 하나로 국내 마늘 재배면적은 2021년부터 가격이 상승함에 따라 증가하고 있는 추세이며 2023년 재배면적은 24,710ha로 전년 대비 10.5% 증가하였다(KOSTAT, 2023). 월동 작물인 마늘은 지역마다 편차가 있으나 대체적으로 9월 혹은 10월에 파종하여 이듬해 5월에서 6월에 수확하는 만큼 전체 과정이 최대 9-10개월에 거쳐 재배하는 동안 지속적인 마늘의 생육 모니터링이 필수적이다. 하지만 최근 농촌의 인구가 2023년 기준 전년 대비 1.1% 감소하는 추세를 보이고 있으며 65세 이상 농가인구 비율로 46.8%로 나타나 노동력 감소와 그에 따른 농가인구 1인당 경지면적은 0.1% 증가한 70.0a로 전망하고있어 농가의 부담이 가중되고 있다(KREI, 2023). 이러한 이유로 주기적인 마늘 필지의 생육을 모니터링함에 있어서 어려움을 겪고 있으며 이에 대한 대책으로 농민의 노동력 부담을 완화하기 위해 신속하고 간단한 측정 방식을 통한 마늘 생육 예측 모델의 개발이 필요한 실정이다.
생육 예측 연구의 예로 무인기에 탑재한 RGB 카메라를 활용하여 배추의 피복 면적을 산출하고 기상 데이터인 생육 도일을 통해 배추의 생체중을 추정하는 모델을 개발하였으며 검증 데이터의 결정계수가 0.91이고 평균 제곱근오차도 134.2(g)으로 높은 성능을 나타내었다(Kang 등, 2023). 그리고 무인기에 탑재한 다중 분광 영상의 시계열 취득 영상 데이터를 활용하여 시기별 콩의 생체중, 건물중 그리고 엽면적 지수를 예측하는 연구가 있었으며 특히 단순비 식생지수인 GRVI()는 다른 식생지수보다 모든 지표들의 결정계수가 0.82 이상의 높은 성능을 나타내었다(Jang 등, 2019). 이렇듯 비파괴적인 관측 방식을 통하여 다양한 생육 예측 연구들이 진행되고있다. 그러나 다양한 카메라를 탑재한 무인기를 활용한 연구도 합리적인 접근 방법이나 일반 농가들이 결과를 분석하고 해석하기에는 어려움이 있으며 무인기나 영상 장치의 비용은 여전히 부담이 존재한다. 따라서 실제로 현장에서 측정이 가능한 표현 형질들과 기상 데이터를 활용한 마늘의 생체중을 예측하는 방법이 무인기와 카메라를 활용한 모니터링에 비하여 실제 농민 관점에서 작물의 생육 상태를 예측함에 있어서 경제적이며 효율적일 것으로 판단된다.
표현 형질을 활용한 연구 사례로는 토마토의 엽장, 엽폭 그리고 엽신장 데이터를 이용하여 엽면적을 추정하는 연구로 최종 모델 식의 결과가 결정계수 0.867, 평균제곱근오차는 88.67로 엽면적을 예측하는 최적의 모델로 선정이 가능하였다(Lee 등, 2022). 엽면적이 수량과 높은 상관관계를 가지는 경향이 있으나 간접적으로 수량을 예측이 가능한 하여 직접적인 수량 예측에는 도달하지 못했다는 부분에서 한계가 있다고 판단된다. 털머위의 엽장과 엽폭을 이용하여 엽면적과 개화 수 추정 모델 식이 가장 신뢰도가 높았으며 엽면적은 결정계수가 0.90, 평균제곱근 오차는 28.61 그리고 개화 수에서 결정계수는 0.82, 평균제곱근 오차는 1.52로 나타났다. 그러나 수식의 계산이 복잡하여 해석상 어려움이 있을 것으로 판단된다(Jung 등, 2023). 다른 예시에서는 엽장, 엽폭 등의 표현 형질로 다양한 품종의 딸기의 엽면적을 추정 비선형 회귀 모델을 개발하였으며 높은 결정계수를 보였다(Jo 등, 2022). 이처럼 표현 형질을 활용하여 다양한 작물의 생육 모델링 연구가 활발히 이루어지고 있으나 기계학습을 활용한 생육 예측 연구들은 아직 미비한 상태이다. 따라서 최근 생육 모델링 분야에서도 회귀식을 활용한 연구 뿐만이 아니라 기계학습을 활용한 연구의 필요성이 대두되고 있다(Zhang 등, 2022). 이러한 예시로, 기계학습 중 비지도 학습법인 군집분석을 통하여 전라남도 지역 배추의 수량을 기상 데이터, 토양 데이터 그리고 생육 데이터를 활용하여 상관성을 파악하고 지역별로 군집을 형성할 수 있었고 생육도일과 점토 함량이 수량과 연관성이 있을 것으로 판단하였다(Wi 등, 2020). 또한 스마트팜 온실 내 딸기 수확량 예측을 꽃 수와 과실 수 데이터를 활용하여 기계학습 알고리즘 중 Lasso 회귀 분석을 활용하였고 MAPE 검증 결과 꽃 예측은 0.511 그리고 과실 예측은 0.488의 결과를 나타내었다(Kim 등, 2022). 따라서 본 연구는 마늘의 표현 형질인 엽장 그리고 엽 수와 기상 데이터인 생육도일(Growing degree day, GDD)을 기반으로 다양한 기계학습들을 활용하여 생체중을 예측하고 각 모델들을 비교 및 검증하는 과정을 거쳐 최적의 마늘 생체중 예측 모델을 선정하고자 하였다.
재료 및 방법
1. 공시작물 및 재배환경측정
본 연구는 고흥군 농업기술센터(34.5669°N, 127.2588°E) 내 시험 포장을 활용하였고 처리 구역 별로 약 1 m × 1 m 의 크기로 나누어 사진을 기준으로 위에서 아래 순서로 투명 피복, 무(無) 피복 그리고 검정 피복으로 다르게 나누어 조성하였다(Fig. 1). 실험에 사용된 마늘 품종은 총 3 가지(대서, 남도 그리고 홍산)로 약 1 달 간격으로 3 회에 걸쳐 나누어 파종하였다(1차 파종: 2022년 8월 29일, 2차 파종: 2022년 9월 30일, 3차 파종: 2022년 10월 31일). 시비 처리 수준 또한 무(無), 관행 그리고 2배 시비로 나누어 마늘을 관리하였다. 이처럼 다양한 환경 조건의 마늘의 생육 데이터를 취득하였으며 재배 기간의 기온 데이터는 온습도센서(Watchdog 1650, Spectrum, UK)를 활용하여 1시간 간격으로 측정하였다.

2. 마늘의 생육 및 생리 특성 조사
마늘은 생식생장기와 인편비대기인 3월 3일, 4월 4일 그리고 4월 26일에 처리구 별로 3개씩 채취하여 총 729개의 생육 데이터를 취득하였다. 전체적인 생육 조사 방법은 농촌진흥청 채소연구표준법매뉴얼을 기반으로 조사하였으며 이를 토대로 생체중, 건물중, 인경 생체중 그리고 인경 건물중은 전자 저울(CUX620HX, CAS, USA)로 무게를 측정하였다. 초장은 인편을 제외한 길이를 측정하였고 엽장은 여러 개 잎 중 가장 긴 잎의 길이를 신장하여 측정하였으며 인경 경과 인경 폭은 버니어캘리퍼스(Mitutoyo, Japan)를 활용하여 측정하였다. 그리고 엽면적은 Li-3100(Li-COR, USA)로 SPAD는 SPAD-502(Konika minolta, Japan)로 측정하였다. 재배환경에 관한 기온의 영향을 분석하기 위하여 생육도일을 주요 변수로 사용하였다(McMaster와 Wilhelm, 1997). GDD는 일 최고온도, 일 최저온도 및 기저온도(5°C)를 조합하여 산출하였으며 계산식은 다음과 같다.
위 식에서 Tmax(maximum temperature), Tmin(minimum temperature), Tb(base temperature)는 각각 일 최고온도, 일 최저온도, 기저온도를 나타내며 마늘의 재배기간 특성상 기온이 영하권으로 하락한 경우는 0로 대체하여 계산하여 생육데이터와 연동하여 모델 개발에 활용되었다.
3. 통계 분석 및 기계학습 모델
마늘의 생육 데이터의 통계분석을 위하여 Sigmaplot(v.12, Systat Software, USA)을 활용하였고 일원분산분석(one-way analysis of variance; one-way ANOVA)을 Duncan 검정(Duncan test, p < 0.05)으로 실시하여 시기별 생육 데이터의 평균치 간의 차이에 대한 유의성을 검정하였다. 또한 상관 분석과 기계학습 모델 분석은 Colab(Google, USA)을 이용하여 처리하였다. 기계 학습을 위하여 마늘 생육 데이터를 훈련, 검증, 그리고 평가용으로 각각 60%, 20% 그리고 20%의 비율로 구분하였다. 또한 기계 학습 모델간 성능을 비교하기 위하여 결정계수(R-squared; R2), 평균 제곱근 오차(Root mean square error; RMSE) 그리고 평균 절대 오차(Mean absolute error; MAE)를 활용하였다. 결정계수는 높을수록, 평균 제곱근 오차와 평균 절대 오차는 낮을수록 모델의 성능이 우수하다 평가할 수 있다.
( : 실제 데이터, : 예측 데이터, : 실제 데이터의 평균)
최적의 기계 학습 모델을 선정하기 위하여 통계적 기법의 모델인 Ridge와 Lasso를 사용하였고 트리(Tree) 기반의 모델인 Random Forest 그리고 그래디언트 부스팅(Gradient boosting) 기반의 LightGBM, Xgboost 그리고 Catboost 모델을 활용하였다. 마지막으로 단일 모델이 아닌 여러 모델을 혼용하여 사용하는 Stacking 모델과 여러 모델들의 가중치를 다르게 적용한 Weighted Ensemble 기법을 통해 생체중을 예측하고 각 모델의 성능을 비교하였다. 특히, Stacking과 Weighted ensemble 모델의 경우, 6가지의 단일 모델 중 성능이 우수하였던 모델의 조합을 통하여 분석을 실시하였으며 각 모델의 하이퍼파라미터들을 다음 표와 같이 정리하였다(Table 1).
Table 1.
Hyperparameters in each machine learning methods.
Ridge 회귀 모델은 일반 선형 회귀의 평균제곱오차를 최소화하는 계산식에 제곱식 형태의 패널티를 부과하고 예측 정확성이 낮은 변수들의 가중치를 감소시킬 수 있으며(Hoerl와 Kennard, 1970) Lasso 회귀 모델의 경우 절대값 형태의 패널티를 부과하여 변수들을 제거할 수 있다는 차이점이 있으며(Tibshirani, 1996) Eq. (4)와 Eq. (5)로 표현이 가능하다.
Random Forest 모델은 여러 개의 트리 모델을 독립적으로 결과를 예측하여 그 결과값들의 평균값을 최종 결과로 도출하는 배깅(Bagging) 방식을 채택하여 모델을 학습한다(Breiman, 2001). Xgboost 모델은 모델의 결과를 예측하고 모델의 오류에 대한 가중치를 부여하여 보완하는 방식의 부스팅(Boosting) 기법을 거쳐 결과를 도출해낸다(Chen and Guestrin, 2016). 또한 GBM(Gradient Boosting Model) 특성상 병렬 계산을 통한 빠른 처리가 가능하다. LightGBM과 Catboost 또한 부스팅 기법을 활용한 모델이며 Xgboost 모델이 가지고 있는 한계점을 보완하여 개선된 모델들이다. LightGBM은 학습 방법에서 트리 생성시 level-wise 방법으로 생성하지 않고 leaf-wise로 한다는 점이 가장 큰 차이이며 층에 제약 없이 잎에서 가지를 치지는 방식의 의사결정나무(Decision tree)를 만들며 이 과정에서 적은 메모리 사용을 가능하게 한다(Ke 등, 2017). Catboost 모델은 XGboost와 LightGBM 모델과 달리 대칭 트리 구조를 사용하여 과적합을 방지한다는 장점이 있으나 느린 처리 속도의 문제가 있다(Prokhorenkova 등, 2018). Staking 모델은 여러 다른 모델을 조합하여 최종 예측을 개선하는 앙상블 학습 기법 중 하나로 우선 개별 모델들로 학습을 한 후 각 개별 모델은 새로운 데이터를 예측하여 결과를 만들게 되며 예측 결과를 모아 메타 모델에 입력으로 넣어 해당 정보를 바탕으로 최종 예측을 수행하는 방식으로 개별 모델이 가진 약점을 보완하여 다양한 관점을 결합해 더 높은 성능을 기대할 수 있게 한다(Wolpert, 1992). Weighted ensemble 모델은 앙상블 학습에서 개별 모델의 중요도에 따라 각 모델의 예측에 가중치를 부여해 최종 예측을 만드는 방법으로 성능이 좋은 모델에 더 많은 가중치를 주어 결합하는 방식을 따르며 모델의 성능 차이를 반영해 더 정확한 예측을 할 수 있도록 설계되어있다(Zhou, 2014).
결과 및 고찰
1. 재배환경에 따른 마늘의 생육 분석
표현 형질과 생체중 사이의 상관분석 결과. 생육 데이터인 초장과 엽장은 생체중과 0.88로 높은 상관성을 보였으며 생체중과 엽 수는 상관성이 0.52로 뚜렷하게 나타나지 않았으며 기상 데이터인 생육도일은 생체중과 0.66으로 낮은 상관관계를 보였다. 변수 간의 상관성을 비교하여 보았을 때, 초장과 엽장은 0.95로 높은 상관관계를 가졌으며 엽 수와 생육도일은 다른 변수들과 큰 상관성을 보이지 않았다(Fig. 2). 따라서 이러한 정보를 바탕으로 초장과 엽장간 높은 상관성이 나타남에 따라 때 발생하는 다중공선성(multicollinearity) 문제를 해결하기 위하여 본 연구에서는 초장을 변수에서 제거하고 엽장, 엽 수 그리고 생육도일을 변수로 선정하여 생체중을 예측하고자 하였다(Lee 등, 2015). 게다가 초장의 경우도 엽장과 다르게 마늘을 뽑는 등의 파괴 조사를 통하여 인경의 뿌리부터 잎의 가장 긴 부분을 측정하는 과정이 있기 때문에 현장에서 측정하고자하는 목적과 거리가 멀다고 판단하였기 때문에 초장 대신 엽장을 변수로 선택하였다. 또한 다른 변수들의 경우에는 지하부에 존재하고 있는 등 파괴 조사를 실시하는 경우가 많았기 때문에 파괴하지 않고 조사할 수 있는 표현 형질 변수들을 선정하였다.

일원분산분석을 통한 파종 시기에 따른 마늘 생육 조사 결과, 생체중은 모든 시기에 있어서 유의한 차이를 보였으며 엽장의 경우에는 3월 3일과 4월 4일에 1차와 2차 파종시기 간 유의한 차이가 나타나지 않았으며 4월 26일에서 3차 파종 시기 데이터가 1차와 2차 시기보다 생육이 역전되는 것을 확인할 수 있었다. 이런 현상은 1차와 2차 파종 시기보다 늦게 파종된 3차 파종 시기 데이터의 생육이 최고점에 다다른 반면 1차와 2차 파종 시기의 데이터는 수확기에 접어들어 시듦 및 황화 현상이 있는 등 생육이 감소한 결과로 해석이 가능할 것으로 판단된다(Lee 등, 2013). 또한 엽 수에서는 3월 3일과 4월 4일에서는 모든 파종 시기 간 유의한 차이를 나타내었으나 수확기에 접어들기 시작하는 4월 말부터는 1차와 2차 파종 시기의 처리구간에는 유의한 차이가 나지 않는 반면 3차 파종 시기와는 처리구에서 유의한 차이를 나타나는 등 1차와 2차 파종 시기 간 생육 상태가 유사한 것을 확인할 수 있었다(Table 2).
Table 2.
Morphological parameters of garlic based on seedling date.
기간별 환경조건을 분석한 결과 같은 재배 기간일 때 일찍 파종한 1차 시기의 경우 생육도일은 1103.80, 1296.05, 1476.20이었으며 관행적으로 파종하는 2차 시기는 561.15, 753.40, 933.55이며 늦게 파종한 처리구인 3차 시기는 232.65, 424.90, 605.05로 일찍 파종한 처리구의 생육도일이 크게 나타났다(Table 3). 시기에 따른 마늘의 생육 도일이 선행 연구와 유사 범위에서 생육도일이 형성되었음을 알 수 있었다(El-Zohiri와 Farag, 2014).
Table 3.
Growing degree days in each seedling date.
2. 기계학습을 활용한 마늘 생체중 모델 비교
훈련 데이터를 이용하여 모델을 학습하고 과적합(overfitting) 오류를 방지하고 평가 데이터 결과의 신뢰도를 높이기 위해 검증을 진행하였다. Table 4에서 나타내는 것과 같이 검증 데이터의 경우 Random Forest 모델이 결정계수가 0.924, 평균 제곱근오차(g)가 13.583로 가장 우수하였으며 뒤이어 LightGBM과 Catboost 모델이 좋은 성능을 보여주었다. 평가 데이터에서는 Catboost 모델이 결정계수가 0.928, 평균 제곱근오차(g)가 13.486 그리고 평균 절대오차가 9.181으로 가장 우수하였으며 뒤이어 Random Forest와 LightGBM 모델이 뒤를 이었다. 전체적으로 생체중이 125g 이하의 데이터는 모든 모델들이 예측에 어려움이 없었으나 통계적인 기법을 활용하는 Ridge와 Lasso 모델은 후반부의 예측력이 감소하는 것을 확인할 수 있었다(Fig. 3). 이는 트리 혹은 그래디언트 부스트 기반의 모델은 모델 내에서 여러 번 학습을 반복하고 개선하는 알고리즘을 가지고 있는 반면 통계 기반 모델은 그렇지 않은 점에서 예측의 한계가 있었다고 판단된다.
Table 4.
Comparison with machine learning models in validation and test set.
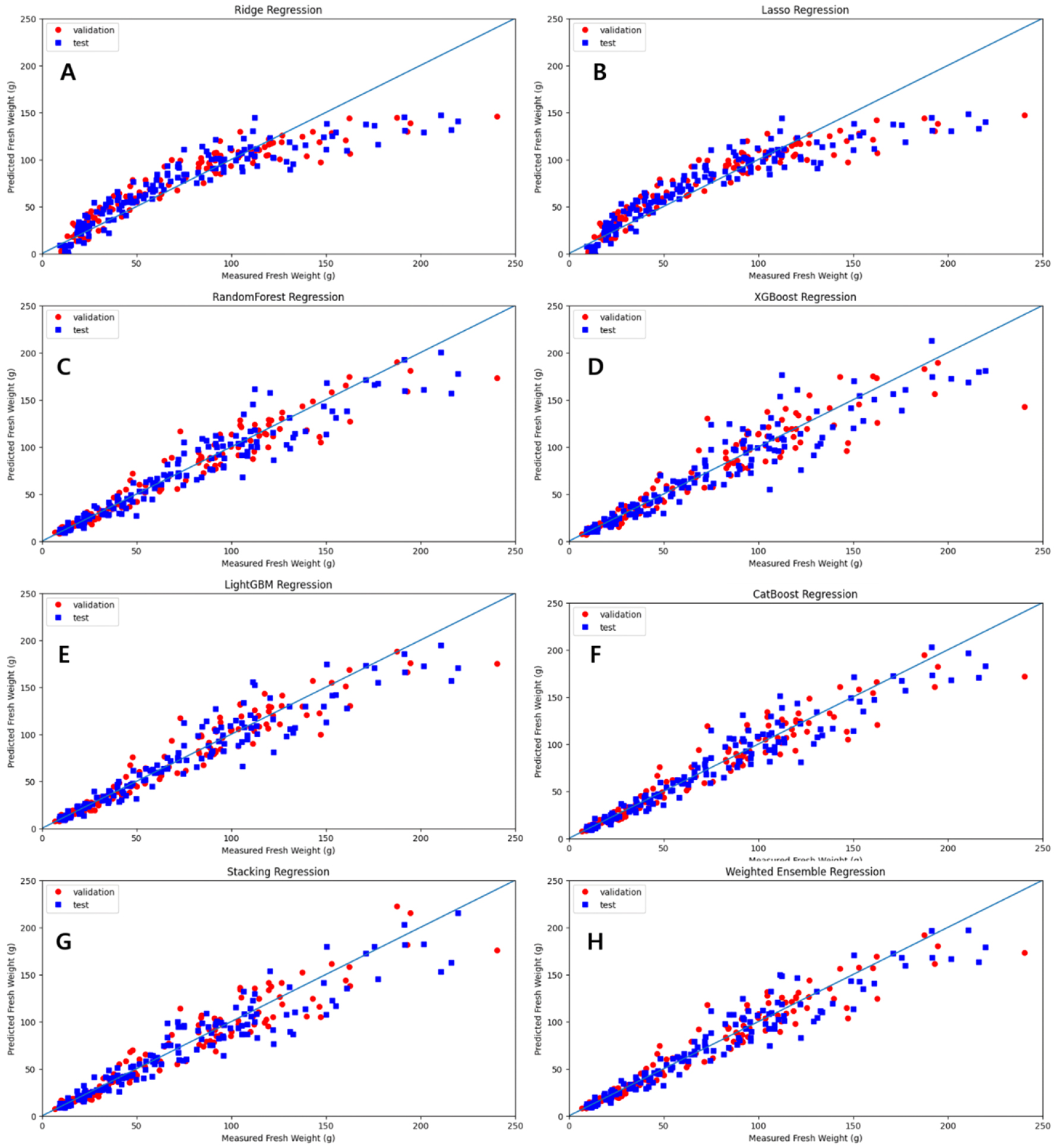
단일 모델로서 검증 데이터와 평가 데이터에서 공통적으로 좋은 성능을 보여준 Catboost, Random forest 그리고 LightGBM 모델들을 참고문헌을 토대로 중요도를 나누어 종합하여 각각 0.5, 0.3, 0.2의 가중치를 두어 Weighted ensemble 모델을 학습하였을 때 가장 우수한 성능을 나타내었다. 특히, 검증 데이터에서는 결정계수가 0.922이고 평균 제곱근오차(g)는 13.752로 검증 모델에서 성능이 가장 좋았던 Random Forest 모델에 근접하였고 특히 평균 절대오차는 8.877로 1% 가량 성능이 개선되었음을 확인할 수 있었다. 그리고 평가 데이터에서는 결정계수가 0.923으로 Catboost 모델의 성능과 비슷한 수준으로 나타났다. 그 결과, Weighted ensemble 모델이 다른 모델들과 비교했을 때 가장 성능이 좋은 모델이라고 할 수는 없으나 검증 데이터에서나 평가 데이터에서 모두 두 번째로 우수한 성능을 나타내었으며 검증 데이터와 평가 데이터 결과를 참고하였을 때 예측 정확도에 있어 편차가 크지 않은 것으로 보아 다른 모델들에 비해 모델의 안정성이 뛰어나다고 판단된다. 이러한 종합적인 결과들을 바탕으로 Weighted ensemble 모델이 마늘 생체중 예측에 있어서 최적의 모델이라고 판단된다. 또한 선행적으로 수행되었던 온도 구배 하우스를 활용한 생육도일 기반 연구(Wi 등, 2017)에서 개발된 마늘 구중 예측 모델인 로지스틱분포 함수의 결정계수가 0.8-0.958인 것과 비교하였을 때, Weighted ensemble 모델의 결정계수는 0.923로 선행 연구에 뒤쳐지지 않는 우수한 성능을 보였으며 특히 본 연구에서는 선행 연구와 달리 ‘남도’ 마늘 뿐만 아니라 ‘대서’와 ‘홍산’ 품종을 포함하며 다양한 노지 재배 조건을 활용하여 분석한 생체중 예측 모델이라는 점에서 성능이 개선된 부분이 있다고 판단된다.
따라서 이와 같이 다양한 기계학습 모델들의 성능을 비교한 결과, Weighted ensemble 모델이 가장 우수하다고 판단하였으며 이를 바탕으로 일반 농가들이 표현 형질인 엽장, 엽 수와 기상 데이터인 생육도일을 활용하여 생체중을 예측할 수 있을 것으로 기대되며 추가적인 다양한 기상환경 조건에 따른 마늘 생육 정보를 취득을 통한 성능 개선과 최적화 과정을 통해 모델을 반영하여 다년도의 추가적인 검증이 필요하다고 판단된다.
