

서 론
재료 및 방법
1. 온실 시스템 구성
2. 모델 개발
3. 기계학습모델 개발방법
4. 실험 및 시뮬레이션 결과 비교ㆍ분석 방법
결과 및 고찰
1. 실험 데이터
2. 개발 모델 사례분석 결과
3. 실험 및 시뮬레이션 결과 비교
서 론
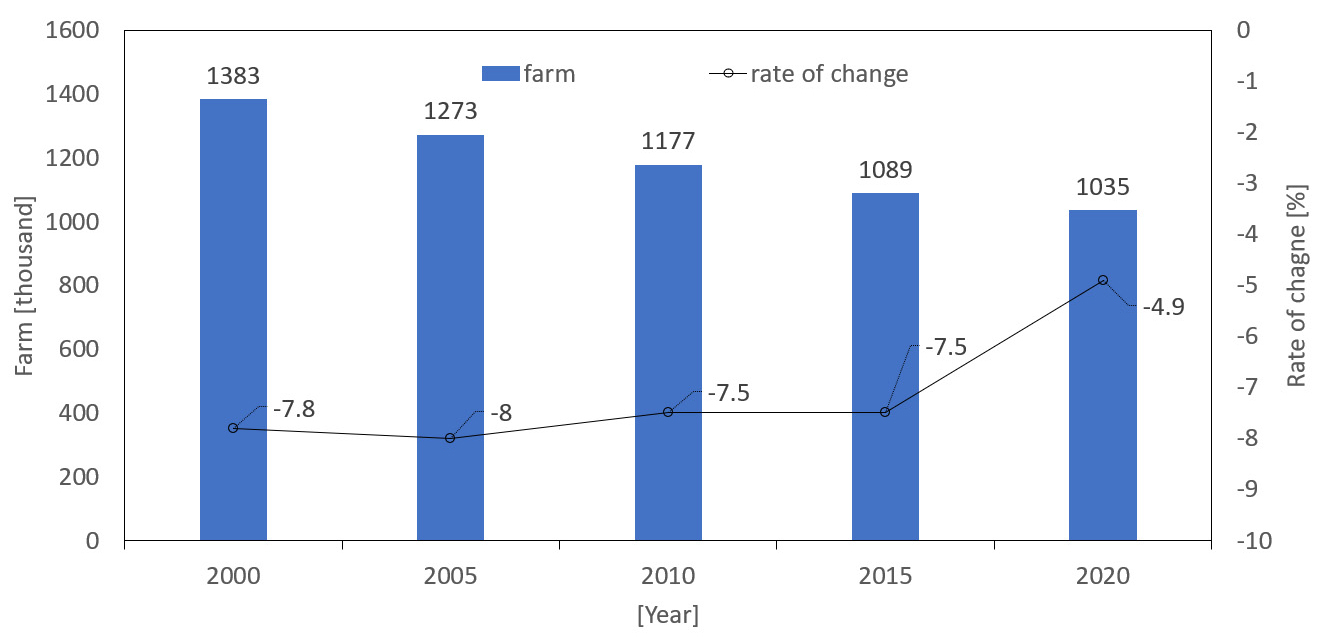
우리나라의 작물 재배 농가는 2000년부터 5년 단위로 약 8%가 지속해서 감소되어 왔다(Fig. 1). 이 중 대부분을 차지하고 있는 노지 작물(논벼, 콩, 감자, 고구마, 고추, 배추 등) 재배 농가는 2015년 94만 9천 가구에서 2020년 87만 7천 가구로 7만 2천 가구(7.6%)가 감소되었지만, 시설 작물(고추, 수박, 딸기, 토마토, 포도 등) 재배 농가는 2015년 12만 5천 가구에서 2020년 12만 6천 가구로 약 1천 가구(1%)가 증가하였다. 이러한 시설 작물 재배 농가의 증가로 인하여 2015년에서 2020년 전체 작물 재배 농가 수는 증감률은 약 –5% 로 약화되었다.
시설농업은 통제된 시설 안에서 빛, 온도, 습도 등의 재배 환경을 인위적으로 조성하여 연중 내내 농산물을 생산하는 농업으로 자동화를 통하여 보다 효율적으로 농산물을 생산할 수 있으며 이에 대한 연구는 지속적으로 증대되고 있다(2020 농림어업총조사, 통계청). 또한 국내 농가의 고령 인구 비중이 2015년 38.3%에서 2020년 42.3%로 늘어나 노동집약적 작업에서 자동화 통한 농작물 생산방안이 요구되고 있다.
이러한 시설농업의 자동화를 위하여 다양한 연구가 수행되어왔다. 실시간 생육환경제어를 위한 농가 온실 내부 자동 온도 조절 환경 시스템을 구축하여 농산물 생산효율을 향상시켰으며(Ahn 등, 2016), 온실 환경의 변화에 따라 즉시 제어가 가능한 웹 기반 시스템을 구축하여 온실 환경에 대한 실시간 확인 및 데이터수집 시스템을 구현하였다(Choi 등, 2012). 또한 이러한 농업 자동화 연구를 효과적으로 활용하기 위해서는 온실 내부 환경변화에 대한 정확하고 정밀한 예측기법이 요구된다. 따라서 기존의 전산유체역학(computational fluid dynamics, CFD) 시뮬레이션 기법을 활용한 내부 환경 예측 연구들이 진행되어 왔다(Cho 등, 2015; Fatnassi 등, 2015; Hong와 Lee, 2014; Kim, 2001; Lee와 Short 1999; Lee 등 2006a, 2006b; Tadj 등, 2010; Yu 등, 2014).
하지만 온실 시스템은 가외 변인(extraneous variable)인 태양광, 외기 온·습도를 포함하고 있어 기존의 시뮬레이션 분석의 한계점이 존재한다. 최근 이러한 문제를 극복하기 위하여 빅데이터를 기반으로 한 인공지능(artificial intelligence, AI)기술이 활용하고자 한다. 인공지능은 4차 산업혁명의 핵심기술로 음성인식, 이미지 분류, 회귀 분석, 데이터 시각화, 추천 시스템, 강화학습 등 다양한 분야에서 활용되고 있으며(Hwang 등, 2021; Park 등, 2018; Na 등, 2017), 이중 인공신경망을 통한 시계열 자료 처리 및 예측 관련 연구 또한 활발히 이루어지고 있다(Kwon 등, 2021). 특히 최근의 인공지능 기술 발달로 인하여 비선형이며 다차원의 복잡한 시스템에 대한 실시간 분석이 가능해졌으며, 산업 분야에서 스마트공장의 공정 최적화를 위하여 활용되는 등 다양한 연구가 선행되었다(Oh 등, 2020). 이러한 빅데이터를 활용한 인공지능 기법을 적용하기 위해서는 대상 시스템의 환경 데이터가 필수적으로 요구된다.
국내 시설농업 농가 중 자동화 시설이 설치된 농가는 유형별로 비닐하우스 56.6 %, 유리온실 24.8 %로 가장 많이 차지(2020 농림어업총조사, 통계청)하고 있으며 여기서 얻어지는 다양한 데이터를 활용한 기계학습모델 적용이 유리하다. 이러한 특성을 바탕으로 인공지능 기술을 활용한 온실 내부 환경 예측을 위한 다양한 연구가 수행되었는데 다원적 회기 인공신경망 모델을 개발하여 온실 내부온도 및 습도 변화 예측에 활용될 수 있음을 검증하였으며(Song 등, 2019), LSTM (long short term memory) 알고리즘과 데이터 특성 분석을 통하여 온실 내부 CO2 농도 분포 예측이 이루어졌다(Lee 등, 2020). 또한 ANN(artificial neural network), RNN(recurrent neural network), MRM(multi regression model) 알고리즘을 통하여 개발된 기계학습모델 예측결과를 활용하여 온실 환기를 효과적으로 제어함으로서 에너지를 효율적으로 관리할 수 있음을 검증하였다(Kim과 Jung, 2017; Choi 등, 2019; Kim 등, 2001). 이처럼 다양한 방법으로 인공지능 모델을 활용한 연구가 수행되고 있지만 모델 구성에 필수적인 매개변수 및 데이터 적용 방법에 대한 명확한 방법이 제시되어 있지 않다.
최종적으로 본 연구에서는 기계학습모델 개발을 위한 데이터 수집 및 분석, 모델 구성을 위한 파라미터 선정과 사례연구(case study)을 통하여 최적 모델 개발 및 평가를 수행하였다. 초매개변수에 변화에 따른 인공지능 기계학습모델의 특성 분석이 진행되었으며, 비선형이며 다차원의 복잡한 시설농업 시스템 비닐하우스의 내부온도 예측을 위한 모델 개발 연구가 이루어졌다.
재료 및 방법
1. 온실 시스템 구성
본 연구는 강원대학교 설치된 유리온실(300m2, 강원대학교 춘천시 효자동 192-1)의 환경제어 시스템에 대하여 분석이 이루어졌다. 대상 유리온실은 자연환기 시스템이며 내부에서 발생되는 추가적인 가외변인을 최대한 제거하기 위하여 아무런 식물을 배치하지 않은 조건에서 실험이 수행되었다. 또한 예측하고자 하는 내부온도와 가장 유의미한 관계가 있는 외부 기상데이터(외부온도, 외부습도, 태양광, 풍향, 풍속, 감우데이터)가 기상관측장치(JNGW100, Jinong, Anyang-si, Korea)를 통하여 수집되었으며 온실 내부온도는 지상 1m 위치에서 열전대(Thermocouple, GTPK-02-17, GILTRON, Seoul, Korea)를 통하여 수집되었다. 최종적으로 데이터로거(GL840, GRAPHTEC Co., Kanagawa, Japan)를 통하여 분당 1개의 데이터가 수록되었다(Fig. 2).

2. 모델 개발
2.1 데이터 전처리
기계학습모델 개발에 첫 단계는 대규모의 데이터베이스 안에서 일정한 규칙을 찾아내어 분석하는 데이터 마이닝(data mining)으로 시작된다. 각기 다른 단위로 수집된 데이터는 정규화를 통하여 기계학습에 적용 가능한 데이터로 전환한다. 또한, 측정 오차 및 신뢰도를 확보하기 위하여 데이터 전처리가 필요하며, 대상 시스템의 정상범위 밖으로 측정된 값은 필요에 따라 제거한다(Charu, 2018). 또한 기계학습모델의 성능은 데이터의 양과 질에 의존적이다. 따라서 모델 적용을 위한 데이터는 정확하며, 적정한 개수로 구성되어 있어야 한다. 이러한 데이터 변환 과정을 차원축소(dimensionality reduction)라고 하며 기계학습의 가장 핵심적인 전처리 과정 중 하나이다. 차원축소는 단순히 데이터의 압축이나 잡음(noise)을 제거하는 것이 아니라 수집된 데이터를 가장 잘 나타낼 수 있는 잠재공간(latent space)을 도출하는 것(Gabriel 등, 1971; Huh, 2017)으로 결과예측에 영향이 미미한 데이터는 전체 특징 집합에서 제거할 수 있으며, 변수 삭제를 통하여 데이터의 차원을 축소 시킬 수 있다. 데이터 전처리는 기존 입력값을 기반으로 새로운 데이터를 생성하기 때문에 모델 학습 전에 수행되어야 하며, 입력 데이터 간의 절댓값 차이가 크면 모델 학습에 많은 영향을 미칠 수 있으므로 각 데이터는 전처리 후 분석이 이루어진다. 본 연구에서는 특징 정규화(feature normalization)의 방법을 통하여 데이터 전처리가 수행되었다(Charu, 2018)(식 1).
:i번째 데이터의 j번째 차원의 값
:j번째 특징의 최솟값
:j번째 특징의 최솟값
:정규화된 x값
2.2 학습모델 선정
전처리를 통하여 정규화된 데이터를 활용하기 위하여 대상 시스템의 특성에 알맞은 모델선정이 필요하다. 시간의 흐름에 따라 실시간으로 주변 환경이 달라지고 이에 따라 데이터 특성이 변화되기 때문에 이전 데이터와 인공신경망을 활용한 학습을 통하여 모델이 개발되며 온실 내부온도 예측이 이루어진다. 따라서 대상 온실 시스템의 시계열 데이터는 특정 수준의 정상성(stationarity)을 가진다고 가정하여 분석이 이루어졌으며, 지도학습(supervised learning)의 회귀 분석(regression analysis)방법을 통하여 연구가 수행되었다(Ariga 등, 2018; Hope 등, 2017; Kim와 Jung, 2017; Muller와 Guido, 2017). 이러한 지도 학습을 통한 기계학습모델의 개발은 레이블된 데이터(labeled data)를 이용하여 모델에 입력값에 대한 출력값을 함께 학습하는 과정이 반드시 요구된다.
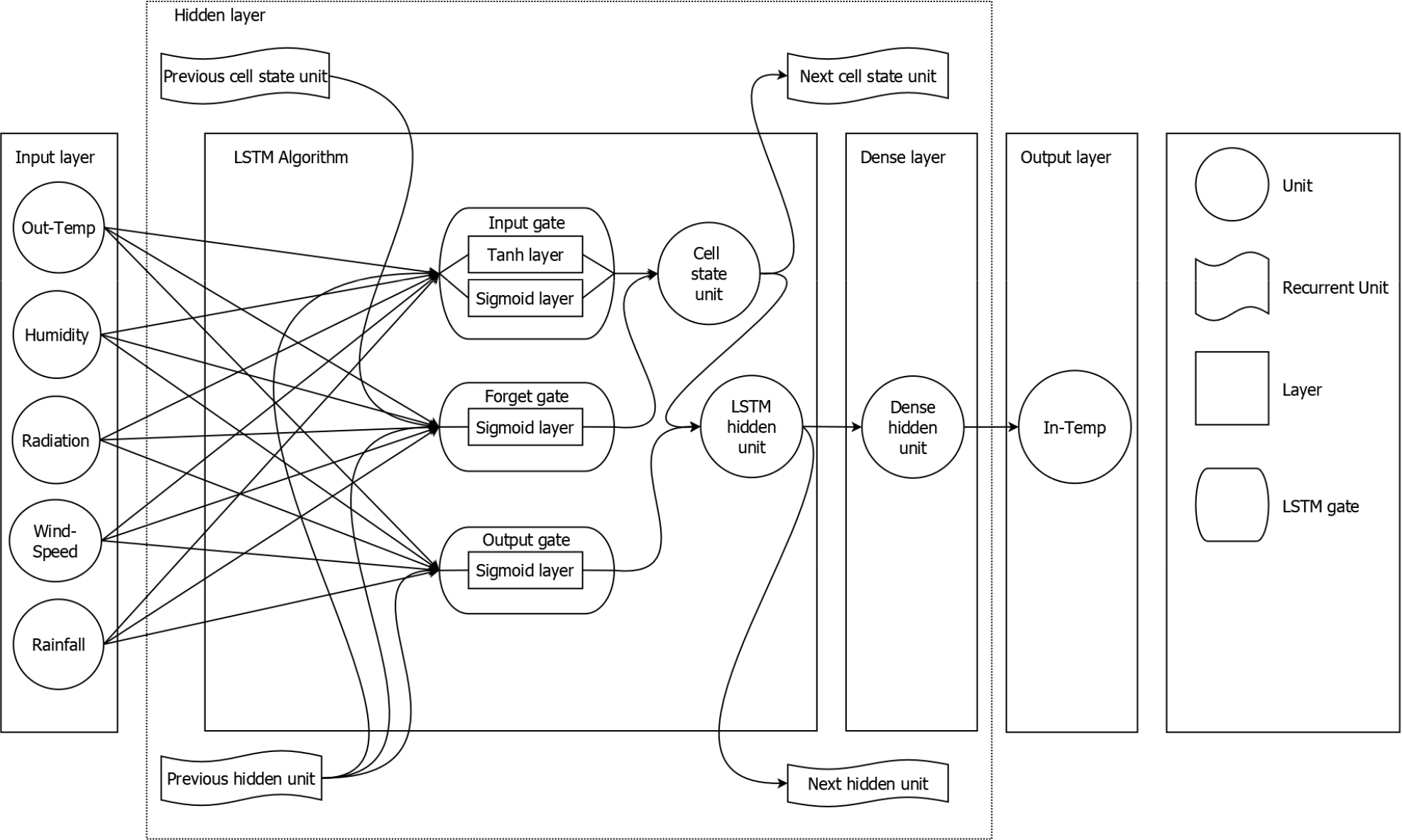
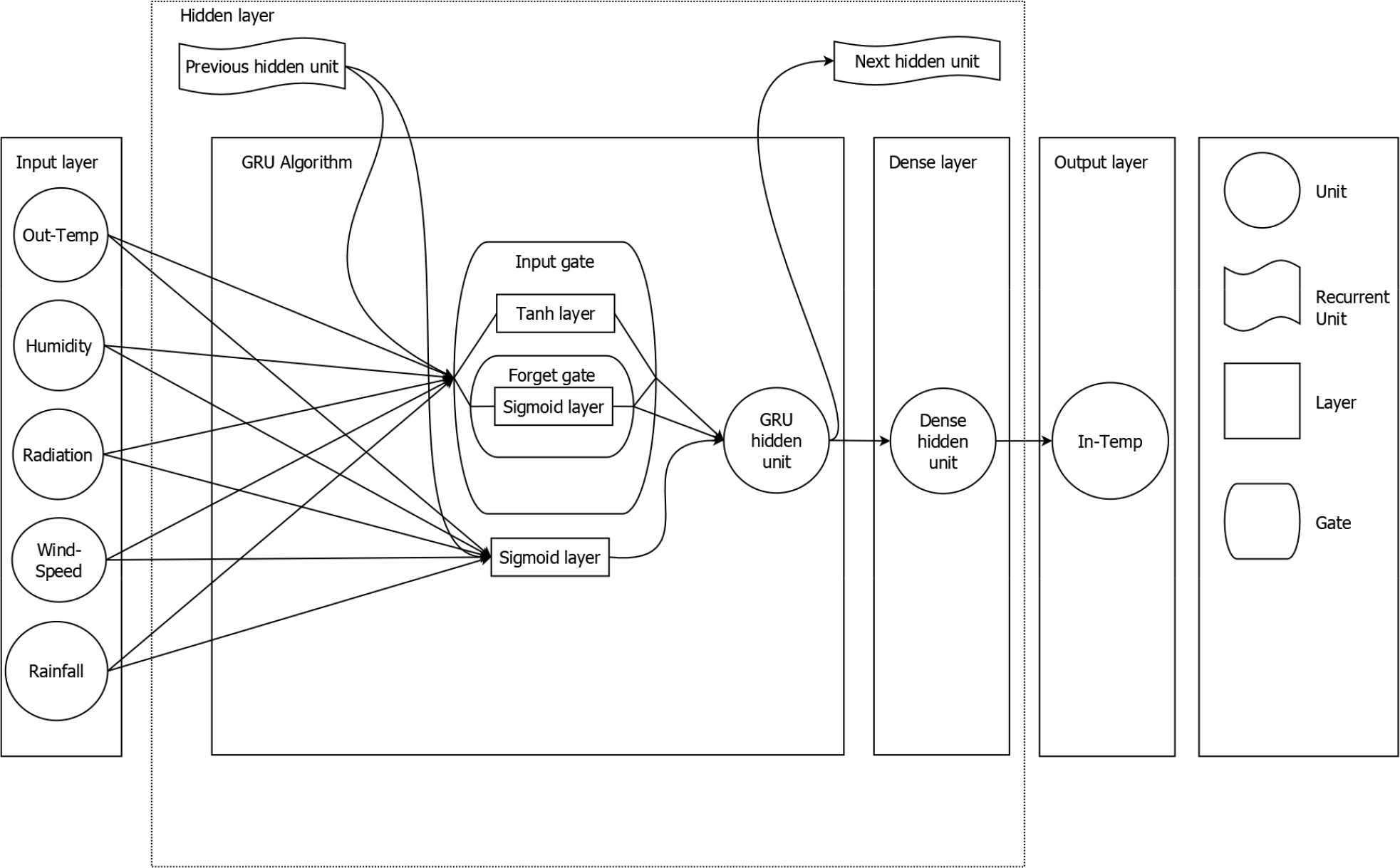
이러한 회기분석의 가장 기본적인 분석방법인 RNN(recurrent neural network) 알고리즘은 데이터의 시퀀스가 길어지면 베니싱 문제(vanishing gradient problem)가 발생하여 모델 정확도가 감소할 수 있다. 이를 해결하기 위하여 LSTM(long short term memory)과 GRU(gated recurrent units) 알고리즘은 제안되었으며 이를 활용한 모델 개발이 이루어졌다. LSTM 알고리즘(Fig. 3)은 hidden layer와 input gate, output gate, forget gate의 세 가지 게이트로 구성된 메모리 블록과 추가적인 cell을 생성하여 베니싱 문제를 개선하였다(Ariga 등, 2018; Chang 등, 2019; François, 2017). 또한 GRU 알고리즘(Fig. 4)은 LSTM 알고리즘에서 게이트를 1개 축소한 reset gate, update gate로 이루어져 있으며 cell의 제거를 통하여 계산 부하를 감소시킨 알고리즘이다(Cho 등, 2014).
3. 기계학습모델 개발방법
기계학습모델은 알고리즘의 확장, 반복학습횟수 및 숨은층(hidden layer)의 증가를 통하여 정밀도 및 정확도 상승시켜 모델 최적화를 달성할 수 있다. 숨은층은 기계학습모델에서 입력레이어와 출력레이어 사이에 위치하는 모든 레이어를 뜻하며, 내부의 숨겨진 층을 1-2로 학습하는 방법의 경우 얕은 학습(shallow learning)이라 부른다. 숨은층의 개수를 3개 이상으로 두껍게 쌓아 분석하는 기법이 딥러닝(deep learning)이며 연속된 층으로 구성하여 점진적으로 가치 있는 값을 학습하는 데 강점이 있다(Charu, 2018). 모델을 개발하는데, 얼마만큼의 층(layer)을 활용하여 학습이 이루어졌는지에 따라 모델의 깊이가 결정되며, 이러한 층들은 매개변수를 통하여 연결되어 있다.
3.1 매개변수
기계학습의 매개변수는 가중치와 같이 모델이 학습되면서 업데이트되는 매개변수(parameter)와 학습 속도나 정칙화에 관여하며 기계학습모델 학습을 위하여 설정 가능한초매개변수(hyper-parameter)로 구분된다. 학습이 진행됨에 따라 매개변수는 제어가 불가능하지만 초매개변수는 입력값에 따른 다양한 결과가 도출된다. 초매개변수 설정에는 다양한 방법이 있다. 가장 기본적으로 grid search가 있으며 다른 대표적인 방법으로 manual search, random search, bayesian search가 있다. Manual Search는 연구자 임의대로 초매개변수를 찾는 방법이며, grid search는 초매개변수의 범위와 간격을 미리 정해 각 경우의 수에 모두 대입하여 최적의 경우의 수를 찾는다. Random search는 정해진 범위에서 난수를 생성해 최적의 초매개변수를 찾으며, bayesian search는 surrogate 모델을 따로 설정하고 이 모델의 매개변수를 업데이트하며 초매개변수를 찾는다(Charu, 2018). 이 중 본 연구는 온실 시스템에 대한 기초적인 분석 결과를 위하여 가장 기본적인 grid search 방법을 통하여 초매개변수 최적화를 수행하였다.
3.2 최적화 함수
최적화 함수는 앞서 설명한 매개변수의 가중치(weight)와 편향(bias)을 최적화하기 위해 사용되는 방법으로 다양한 방법들이 존재한다. 일반적으로 딥러닝은 학습되는 가중치가 많으므로 학습에 계산 부하가 크게 발생한다. 따라서 확률적 경사 하강법을 활용하여 일부 데이터의 샘플만 무작위로 추출해 학습 속도를 개선할 수 있다. 초매개변수 중 하나인 학습률이 너무 크면 학습이 빠르게 진행되지만, 최적화 지점을 지나쳐버릴 수 있고 학습률이 너무 작으면 학습 시간이 증가하며 과소 적합의 문제가 발생한다. 따라서 본 연구에서는, 아담(adam) 최적화 함수를 사용하여 모델을 구성하였으며, 학습률 초깃값을 0.001로 설정하여 모델학습을 수행하였다.
3.3 손실함수
손실함수(loss function)는 모델을 통하여 예측된 결과와 실제값과의 차이를 계산하여 모델 최적화를 수행하는 방법으로, 손실함수의 종류는 MSE(mean squared error), MAE(mean absolute error), binary cross entropy, categorical cross entropy sparse, categorical cross entropy등이 있다. 기계학습에서 신경망 성능을 측정하는 손실함수는 모델이 올바른 방향으로 학습될 수 있는 역할을 수행한다(Charu, 2018). 본 연구에는 대부분의 회기 예제에 활용되는 MSE를 적용하여 분석이 이루어졌으며, 오차가 증가할수록 큰 값이 도출되며 오차가 감소할수록 작은 값이 도출된다.
3.4 모델 개발방법
신경망의 초기화는 모델의 안정성 문제들과 관련이 있으며, 초기 입력값이 변화할 경우 동일한 데이터로 반복 학습을 수행하더라도 다른 결과가 도출될 수 있다. 따라서 항상 일정한 초깃값이 입력되도록 “Seed()” 함수를 통하여 입력시드를 고정하여 모델 개발이 이루어졌다. 이를 통하여 반복 학습에 대한 모델의 재현성을 달성하였으나 반복계산횟수의 증가 및 최적화 함수의 내부 알고리즘에 따라 변화하는 학습률로 인하여 완벽히 동일한 결과를 도출하지 않는다. 또한 이전 수행된 시계열 데이터에 대한 연구결과(Kwon 등, 2021)를 바탕으로 아래 Table 1의 조건으로 모델 개발이 수행되었다.
Table 1.
Model development conditions (Kwon et al., 2021).
| Item | Value |
| Algorithms | RNN/LSTM/GRU |
| Hidden layer | 1-20 |
| Optimizer | Adam |
| Learning rate | 0.001 |
| Loss function | MSE |
| Number of epochs | 200 |
| Batch size | 256 |
기계학습모델은 반복계산(iteration)을 통하여 매개변수의 가중치가 업데이트되어 학습이 이루어지고 모델 성능이 개선된다(Muller와 Guido, 2017; Kim와 Jung, 2017). 모델 개발은 Python 기반의 TensorFlow를 이용하여 수행되었으며 Keras 딥러닝 라이브러리를 사용하였다.
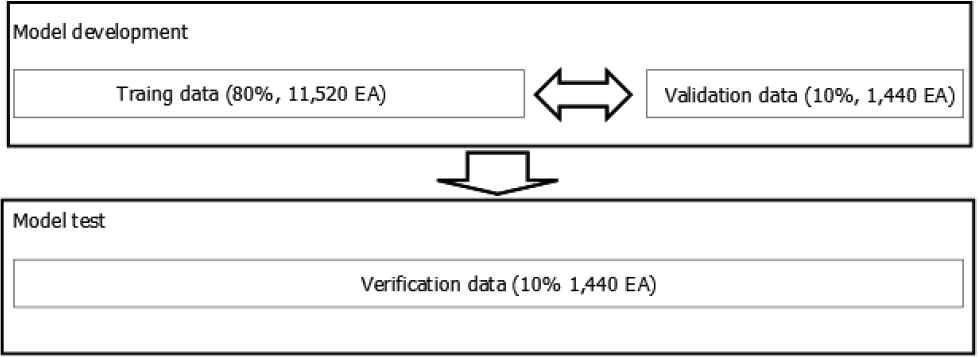
또한 인공지능 지도학습을 통하여 모델 개발 시 훈련데이터와 검증데이터를 명확히 분리하지 않으면 모델의 예측 신뢰성이 낮아지며, 시계열데이터의 경우 미래의 데이터가 과거를 예측하는 데 사용될 수 없다. 따라서 예측 모델 8일간 데이터를 이용하여 학습하고 이후 1일 데이터를 통한 학습의 검증(validation)에 활용하였으며, 이후 훈련에 사용되지 않는 1일 데이터를 활용하여 최종적인 모델 확인(verification)이 이루어졌다(Fig. 5). 대상 유리온실의 2021년 9월 17일에서 9월 27일까지 10일간의 1분 단위의 데이터(14,400개)를 이용하여 이루어졌다.
4. 실험 및 시뮬레이션 결과 비교ㆍ분석 방법
개발 모델은 결정계수(coefficient of determination)(Kim 등, 2007)를 통하여 실험값과 시뮬레이션 값의 정확도(accuracy) 비교분석(식 2)이 이루어졌으며 평균 제곱근 오차(root mean square error, RMSE)를 통하여 모델 정밀도(precision)가 분석되었다(식 3).
di : difference between ith estimated and ith measured values
Yi : ith measured value
Xi : ith estimated value
R2 : coefficient of determination
RMSE : root mean square error
결과 및 고찰
1. 실험 데이터
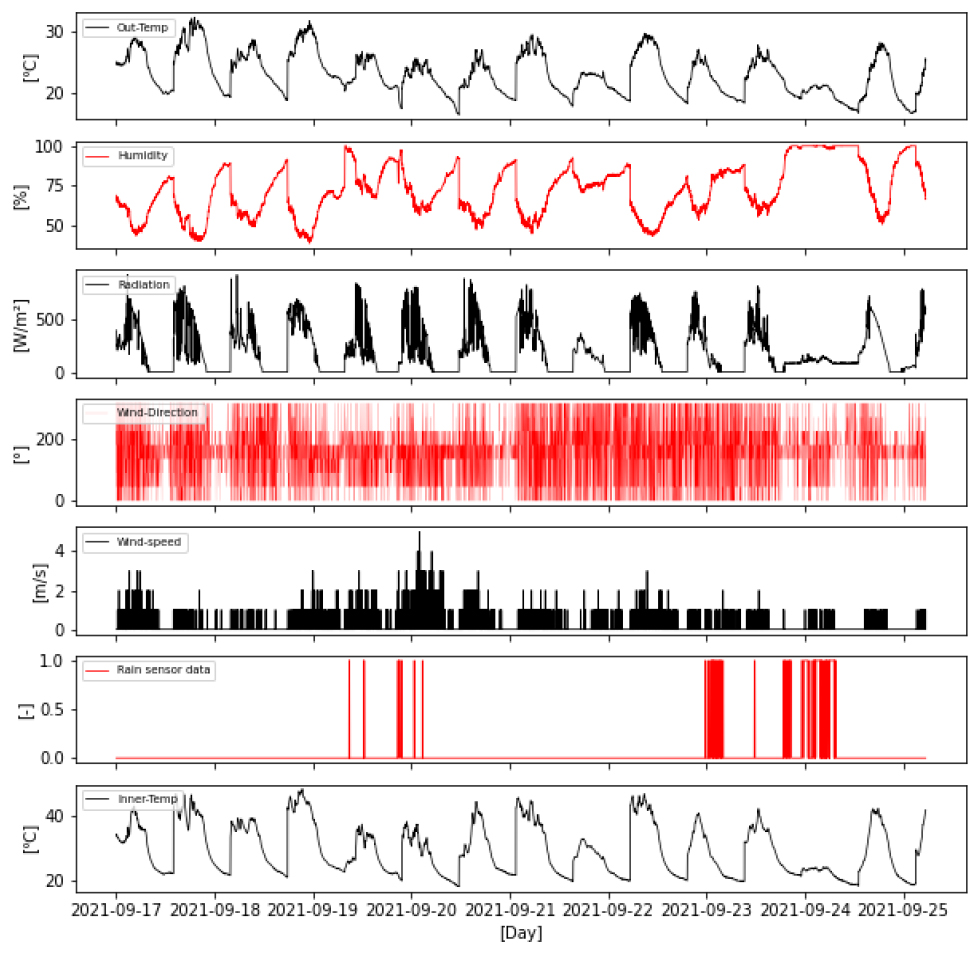
기계학습모델을 개발하기에 앞서 측정 데이터의 분석이 이루어졌다. 대상 온실의 10일간의 외부온도는 최저 20℃에서 최대 30℃까지 나타났으며, 온실 내부온도는 온실의 보온특성으로 인하여 최대 40℃까지 상승하였다. 또한, 감우데이터를 살펴보면 2일간(21일-22일) 비로 인하여 높은 습도 유지 및 비교적 낮은 온도 특성이 나타났다(Fig. 6). 이렇게 다양한 데이터 특성이 기계학습모델에 학습되어 내부온도 예측 모델 개발이 수행되었다.
2. 개발 모델 사례분석 결과
대상 데이터에 대하여 각 세 가지 알고리즘(RNN, LSTM, GRU)과 숨은층(hidden layer)의 변화에 따른 사례분석이 수행되었으며 결과는 Table 2와 Fig. 7로 나타났다. Table 2을 살펴보면 모든 개발 모델은 숨은층 증가에 따라 평균 파라미터의 개수가 증가하였으며 RNN 알고리즘의 파라미터가 평균 184개로 가장 적고 GRU 530개, LSTM 734개 순서로 많게 나타났다. 개발 모델의 평균 기본적이고 단순한 알고리즘인 RNN의 정확도는 훈련모델 0.9458로 분석 알고리즘 중 가장 낮게 도출되었다. 또한, 다른 두 알고리즘의 훈련모델 정확도는 각각 LSTM 0.9673, GRU 0.9669로 비슷하게 나타났는데 알고리즘에 추가된 게이트 특성으로 인한 결과로 판단된다. 각 알고리즘의 테스트모델 평균 정밀도는 RNN 0.9532, LSTM 0.9512, GRU 0.9564로 모두 0.95 이상으로 모두 시계열 데이터 시뮬레이션 모델링에 적절한 알고리즘으로 판단된다.
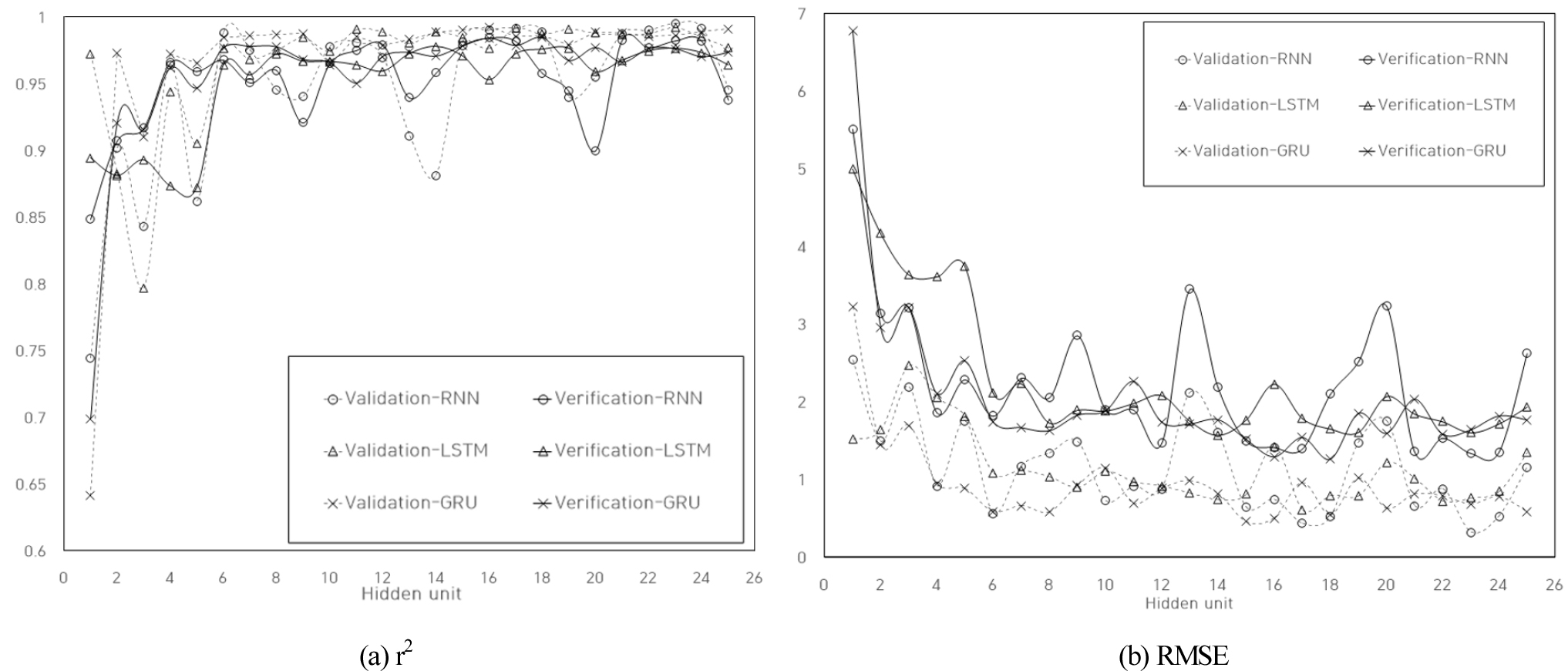
Table 2.
Model parameter change according to the hidden unit and the algorithm.
Fig. 7의 히든 유닛 증가에 따른 모델 특성 분석 결과 두 가지 모델의 척도를 살펴보면 숨은층 6 이상에서 안정적인 결과가 나타났다. 숨은층 증가에 따른 모델 정확도(Fig. 5(a))는 대부분 비슷한 경향을 나타내었으며, 모델 정밀도(Fig. 5(b))는 테스트 결과보다 훈련결과가 높게 나타나는 기계학습 특성이 나타났다. 이렇게 파라미터에 따라 다양한 모델 성능 차이가 발생하기 때문에 최적화를 위한 분석이 이루어져야 한다.
RNN 알고리즘의 경우 6 이하의 숨은층에서 모델 정확도 및 정밀도가 낮게 나타나는데 이는 비교적 적은 매개변수로 인하여 과소 적합(under fitting)이 발생한 것으로 사료된다. 따라서 기계학습모델의 학습 시 숨은층의 개수는 최소한 6개 이상으로 선정하는 것이 적절하다고 판단된다. 또한, RNN 알고리즘의 경우 숨은층이 증가함에도 모델 안정화가 이루어지지 않는 것으로 나타나는데 이는 기울기 폭발 및 소실로 인하여 모델 오차가 증가하는 것으로 판단된다. 또한, LSTM과 GRU 알고리즘은 비슷한 수준의 모델 정확도와 정밀도 결과가 도출되었다. 하지만 LSTM 알고리즘은 GRU 알고리즘 보다 약 30% 이상의 많은 숨은층을 가지고 있으며 모델 개발 시 파라미터 개수가 늘어남에 따라 높은 계산부하량이 요구되기 때문에 모델학습 시간이 증가하는 문제점이 발생한다. 따라서 최적의 정확도와 정밀도를 가진 모델을 도출하기 위하여 GRU 알고리즘이 대상 시스템에 가장 적합한 알고리즘이라 판단된다. 따라서 최종적으로 본 연구의 대상 시스템의 데이터에 대한 최적의 숨은층은 6개, GRU 알고리즘으로 선정되었다.
3. 실험 및 시뮬레이션 결과 비교
숨은층 25개에서 알고리즘에 따른 온실 내부온도 예측 결과는 Fig. 8과 같다. Fig. 8의 (a), (c), (e)의 모델 훈련 결과를 살펴보면 RNN 알고리즘의 경우 너무 많은 학습으로 인하여 과대 적합이 발생하여 약 4℃ 이상의 오차를 나타내고 있으며, GRU와 LSTM 알고리즘의 경우 약 2℃ 이내의 상대적으로 낮은 오차가 나타났다. 또한, Fig. 8의 (b), (d), (f)의 모델테스트 결과 RNN 알고리즘은 오전 8시에서 10시 사이의 온도상승 부분을 잘 예측하지 못하는 한계점이 나타났으며, GRU와 LSTM 알고리즘은 대부분의 시간대에서 모델이 잘 예측하는 결과를 도출하였지만 16시에서 20시 구간에서 서로 다른 예측 특성이 나타났다. 이는 두 모델의 서로 다른 게이트 숫자와 메모리 블록 특성에서 나타난 결과라 판단된다.
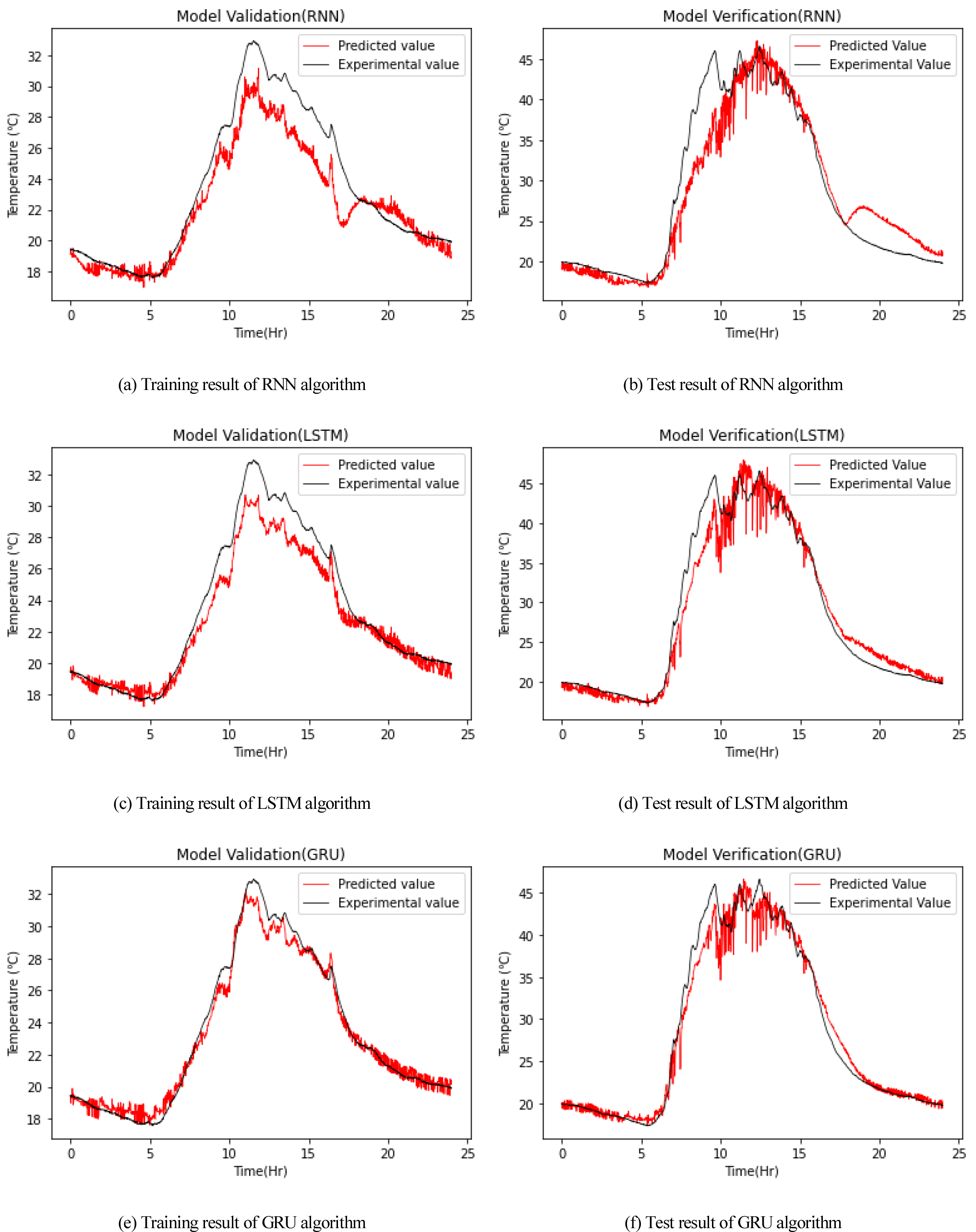
본 연구에서는 기본적인 시계열 알고리즘을 활용하여 온실 내부온도 예측 모델이 개발되었으며, 예측 결과 일정 파라미터 개수 이상의 학습 구간에서 약 2℃ 이내의 오차의 성능을 가지는 모델 정확도를 나타냈다. 더 나아가 본 연구에서 다루지 못한 추가적인 파라미터의 및 학습방법 개선을 통하여 더욱 높은 성능의 모델 개발이 필요할 것으로 판단된다.
