

서 론
재료 및 방법
1. 데이터 세트 구축
2. 병충해 검출을 위한 CNN 모델설정
3. 병충해 검출을 위한 CNN 모델 학습
4. 병징에 특화된 분할 이미지 데이터 세트 구축
5. CNN을 이용한 병충해 검출 알고리즘
6. 병충해 검출 모델 학습
결과 및 고찰
1. 병충해 검출 재현율 비교
2. 병충해 검출 신뢰도 비교
서 론
딸기는 국내에서 인기 있는 열매채소로서 부드러운 단맛과 면역력 증강, 피로 해소, 시각 기능 개선과 같은 특징을 지니고 있다. 이러한 맛과 특징으로 인해 수출량이 늘어나는 추세이며 KATI에 따르면 수출량이 2015년 33,027($1,000)에서 2020년 53,747($1,000)으로 매우 증가하였다. 현재 국내에서 재배되고 있는 대표적인 딸기 품종인 ‘설향’은 다른 품종보다 탄저병, 시들음병, 응애, 진딧물과 같은 병충해 발생이 잦다(Nam 등, 2015). 따라서 병충해로부터 작물을 보호하는 것은 농산물의 경쟁력과 생산성을 높이는 필수적 요소이다.
그러나 기존의 병충해 검출은 사람의 육안으로 판단한 후, 병해충의 방제 처리를 진행하는 실정이며 농가의 조기 병충해 검출을 가능하기 위해서는 지속적인 작물의 상황을 모니터링하며 많은 시간 및 인력 자원을 소모해야 한다. 많은 시간 및 인력 자원이 병충해 검출에 소모된다면, 작물의 생산단가 상승, 해당 작물의 경쟁력 하락이 일어날 수 있다. 따라서 농가에서는 병충해로부터 작물을 효과적으로 방제하기 위해서는 자동화된 작물 모니터링 및 검출화 식별 기술이 필요하다. 병충해 검출은 작물의 잎과 과실을 포함한 이미지에서 병충해의 존재 여부를 검출하는 기술을 의미한다. 병충해 검출은 실제 농가에서 활용될 수 있는데, 촬영한 작물의 병충해 존재 여부 및 발생한 병충해의 종류를 분류하여 현재 작물의 상태를 농가에서 실시간 모니터링할 수 있다.
딥러닝은 인공지능의 세부 분야로서 연속된 층에서 의미 있는 특징을 데이터에서 추출하는 방식으로 주어진 학습 데이터 세트를 학습하여 각 층의 가중치를 설정하는 기계학습 알고리즘이다(Dumitru 등, 2014). CNN은 1989년 얀 리쿤 교수가 손글씨 문자 인식을 위해 제안한 딥러닝 기술로서, 인간의 시신경 구조가 정보를 처리하는 방식을 모방하여 만들어진 모델이다(Lecun 등, 1998).
현재 병충해 검출 모델은 토마토, 파프리카 작물에서 활발한 연구를 보인다. 2021년 “심층 CNN 기반 구조를 이용한 토마토 작물 병해충 분류 모델”에 따르면 해당 모델은 토마토의 9가지 병해충 및 정상 유무를 분류할 수 있다. 또한 일반적으로 사용되는 Adam 모델 최적화 알고리즘이 아닌 RMSprop 알고리즘이 98.63%의 정확도로 우수한 모습이 보여주었다(Kim과 Ahn, 2021). 하지만 해당 모델에 사용된 토마토 병충해 데이터는 병징을 지닌 잎을 가공 후 촬영하여 구축하였다. 따라서 농가에서 촬영되는 데이터와 차이가 있으며 해당 모델이 농가에서 실증 실험 시 실험 결과와 같은 정확도를 신뢰하기 힘들다. Kim과 Kim(2020)에 따르면 해당 모델은 Multi-Tasking U-net을 이용하여 파프리카의 응애, 흰가루병, 정상 잎을 감지할 수 있다(Kim과 Kim, 2020). 하지만 해당 모델에 사용된 파프리카 병충해 데이터는 촬영 후 가공하여 구축되었으며 해당 데이터 역시 농가에서 촬영한 데이터와 차이가 있다. 이처럼 딥러닝을 이용한 병충해 검출 모델은 농가에서 촬영한 데이터가 아닌 가공을 통해 만들어진 데이터이기 때문에 실증 검증 시 모델의 성능을 신뢰하기 힘들다.
본 연구의 목적은 딸기 병충해 검출 모델이 농가와 같은 현장에서도 성능을 신뢰할 수 있도록 하는 것이다. 따라서 사용되는 데이터는 증강을 제외한 별도의 가공작업을 거치지 않았다. 또한 기존의 병충해 학습 데이터와 다른 병징에 특화된 데이터 세트를 추가로 구축하여 모델의 병충해 검출 성능을 향상하였다. 병충해 검출을 위한 기술은 CNN 기반 YOLO 딥러닝 모델을 제안하였다.
재료 및 방법
1. 데이터 세트 구축
본 연구에서는 AIHub가 제공하는 2020년 ‘인공지능 학습용 데이터 구축사업’으로 구축된 시설작물의 질병 진단을 위한 주요 시설원예작물(10종)을 이용하였다. Fig. 1은 학습에 사용된 병충해가 발생한 딸기의 영상 데이터 중 하나이며, 해당 영상 데이터는 고정된 각도에서 촬영한 영상이 아닌 다양한 각도, 위치에서 촬영한 데이터로 이루어졌다. 병충해가 발생한 위치를 x와 y축을 이용하여 사각형인 바운딩 박스로 표현한다. 따라서 바운딩 박스는 병충해가 발생한 위치의 x최소값, y최소값, x최대값, y최대값을 가진다. 바운딩 박스를 그리는 분류작업은 Fig. 2와 같이 수행하였다.


병충해 영상은 동일한 병충해임에도 영상을 촬영한 각도에 따라 다른 모습을 가진다. 따라서 병충해 검출 모델이 병충해를 검출하는 정확도를 높이기 위해 데이터 증강을 사용하였다. 데이터 증강은 기하적 변환과 태스크 기반 변환 기법을 이용하여 데이터의 양을 증가시키는 기법이다. 기하적 변환은 크기 조절, 반전, 자르기, 회전과 같은 이미지 데이터의 기하적인 특성을 변화시켜 데이터를 확장하는 방법이다. 태스크 기반 변환 기법은 인식할 물체를 자르기, 반전을 이용하여 인식할 물체의 초점을 두어 데이터를 확장하는 방법이다(Shorten과 Khoshgoftaar, 2019). 본 연구에서 사용한 데이터 증강기법은 기하적 변환과 태스크 기반 변환을 혼합 사용하였으며 병충해의 병징에 초점을 두어 데이터를 확장하였다.
2. 병충해 검출을 위한 CNN 모델설정
R-CNN(Region-based CNN)은 CNN 기반 객체 인식 및 검출 알고리즘이다. R-CNN의 객체 추정 방법은 객체가 존재할 수 있는 부분의 이미지 영역을 추정 후 객체 후보군을 생성한 뒤 제안하는 방식이기 때문에 학습에 필요로 하는 프로세스 과정이 길어져 다른 CNN 기반 알고리즘보다 학습 시간이 오래 걸리는 단점이 있다(Ren 등, 2017).
반면, YOLO(You Only Look Once) 알고리즘은 R-CNN 방식에서 객체 후보군을 찾는 복잡한 처리 과정을 생략하여 학습에 필요로 하는 시간과 복잡한 처리 과정으로 인한 최적화의 어려움을 개선하였다(Redmon과 Farhadi, 2017). YOLO는 물체 검출 및 검출 처리 과정을 최적화하였고, 기존의 다른 CNN 모델과는 다르게 이미지 전체를 한 번만 처리하기 때문에 학습 및 실행 속도가 빠르다. 하지만 YOLO는 작은 물체 감지에는 낮은 성능을 보이는데, YOLO의 오차 함수에서 예측한 후보군을 선정할 때 크기가 큰 물체는 다른 물체와 IOU 값이 큰 차이가 나기 때문에 적절한 물체를 선정할 수 있다. 반면에 크기가 작은 물체는 약간의 차이가 IOU 값을 크게 변경시키기 때문에 적절한 물체를 선정하기 어렵다. Fig. 3은 YOLO의 구조도이며 YOLO 방식은 GoogLeNet 모델을 최적화한 계층 구조와 총 24개의 콘볼루션 계층과 2개의 완전 연결 계층들로 구성되어있다. 본 연구에서는 학습 데이터의 병충해 영상을 별도의 데이터로 추출하여 학습하므로 방대한 학습 데이터를 빠르게 학습할 수 있도록 R-CNN 알고리즘보다 학습 및 추론 속도가 최적화된 YOLO 알고리즘을 선택하였다.

3. 병충해 검출을 위한 CNN 모델 학습
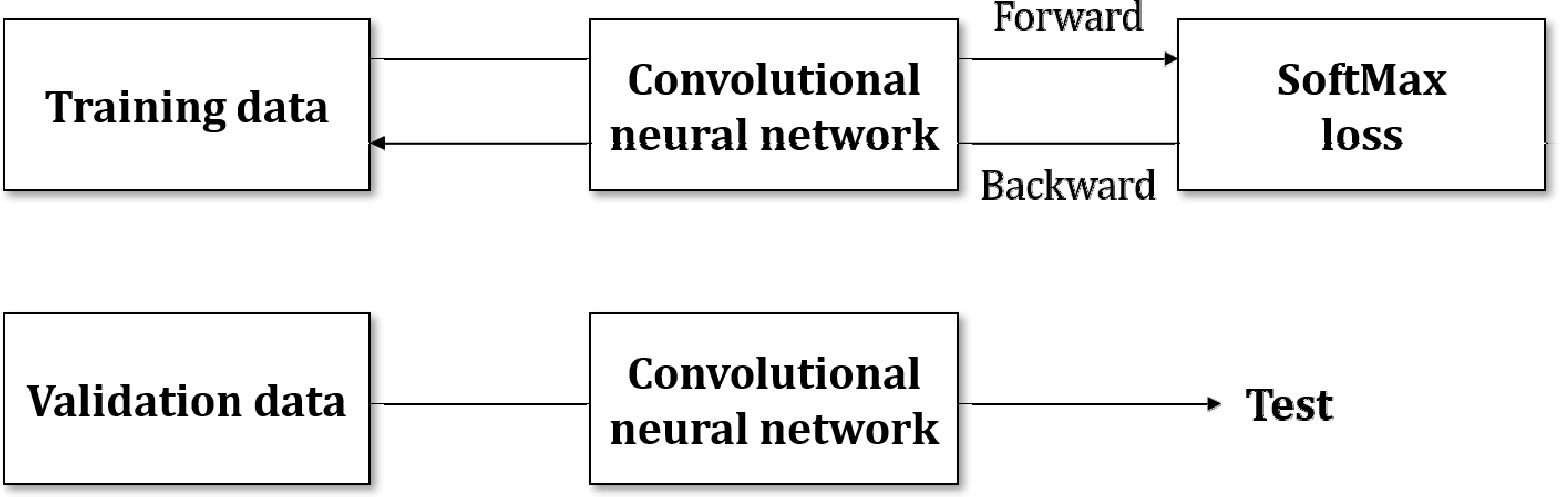
CNN 학습은 Fig. 4와 같이 전 방향과 역방향 전파로 이루어진다. 전 방향 전파는 각 계층의 가중치를 이용하여 병충해 영상을 추론하여 분류하는 단계이고, 역방향 전파는 라벨링된 정답과 학습 영상 데이터와의 추정 오차가 최소화되도록 각 계층의 가중치와 편향을 계산하여 갱신하는 과정이다. 딥러닝은 전 방향 전파 과정을 통해 데이터의 특징을 검출하고, 역방향 전파 과정을 통해 학습 데이터와 추론 오차를 가중치 갱신을 통해 줄여나간다.
활성화 함수는 입력된 학습 데이터의 가중치의 합을 출력신호로 변환하는 함수이다. 소프트맥스 함수는 활성화 함수 중 하나의 기법이며 출력 값이 0-1 사이의 값으로 정규화되며, 모든 출력 값의 합이 1이 되는 특성을 지닌 함수이다. 소프트맥스에 사용되는 수식은 수식1과 같다. 소프트맥스 함수의 y는 출력층을 의미하며, exp(x)는 ex를 의미하는 지수함수이다. n은 출력층의 뉴런 수를 의미하며 yk는 뉴런의 집합중 k번째 뉴런의 출력임을 의미한다. 식 1과 같이 소프트맥스 함수의 분자는 입력신호 ak의 지수 함수이며 분모는 모든 입력 신호의 지수 함수의 합으로 구성된다. 이 소프트맥스 함수를 이용하여 모델의 추론결과 내 영상 데이터의 병충해 존재 여부를 확률적으로 표현할 수 있다.
4. 병징에 특화된 분할 이미지 데이터 세트 구축
딥러닝 모델이 학습 영상 데이터의 배경과 같은 잡음으로 인해 병충해 검출 정확도가 저하되는 문제를 개선하기 위해 Fig. 5와 같이 분할 이미지 데이터 세트를 구축하여 학습을 진행하였다. 분할 이미지 데이터는 Fig. 2와 같은 분류된 병충해의 바운딩 박스를 잘라내어 구축한 데이터를 의미한다. 분할 이미지 데이터 구축을 위해 일반적인 데이터 세트 구축 시 도출된 바운딩 박스의 좌표를 사용하였다. 딥러닝 모델은 분할 이미지 데이터 세트를 이용하여 전체 영상 데이터가 아닌 분할된 병징 영상에서 병충해를 구분하는 특징을 학습한다. 이러한 데이터 세트는 딥러닝 모델이 병충해 검출 시 병징 영상의 특징을 강조함으로 모델이 병충해 존재 여부를 쉽게 판단할 수 있어 모델의 병충해 검출 정확도를 향상한다.

5. CNN을 이용한 병충해 검출 알고리즘
본 논문은 CNN 알고리즘을 이용하여 병충해 검출 프로세스를 구축하였다. 병충해 검출 프로세스는 학습 단계와 실증 단계로 설정하였다. 학습 단계는 학습을 위한 2종류의 학습 데이터 세트를 구축하는데 첫 번째 학습 데이터 세트는 Fig. 2와 같이 분류 작업을 거친 후 구축하며 두 번째 학습 데이터 세트는 Fig. 5와 같이 첫 번째 학습 데이터 세트를 구축시 도출된 바운딩 박스 좌표를 이용하여 분할 이미지 학습 데이터 세트를 구축한다. 이후 딥러닝 모델은 구축된 학습 데이터 세트를 입력받아 GPU 컴퓨팅의 연산수행으로 학습을 진행한다. 사용자는 자동으로 수집된 딸기 영상 데이터를 학습된 딥러닝 모델에 입력하면 CNN 알고리즘은 해당 영상 속 병충해 존재 여부를 확률화 하여 사용자에게 제공한다.
6. 병충해 검출 모델 학습
실험은 본 논문에서 제안한 분할 이미지 데이터 세트와 일반적인 데이터 세트를 이용하여 학습한 딥러닝 모델의 성능을 비교 분석하였다. 일반적인 데이터 세트(Data Set)의 크기는 5,000장의 영상 데이터를 사용하였으며, 4,500장은 학습 데이터 세트(Training Data Set)로 설정하였고, 500장은 검증데이터 세트(Validation Data Set)로 구축하였다. 분할 이미지 데이터 세트(Segmented Image Dataset)의 크기는 21,000장의 영상 데이터를 사용하였으며, 18,000장은 학습 데이터 세트로 설정하였고, 3,000장은 검증데이터 세트로 구축하였다. 각 데이터 세트별 딥러닝 모델의 학습 횟수는 900번 학습하였고, 72시간이 소요되었다. 실제 영상에서 딸기의 병충해 검출률 평가를 위하여 학습 데이터 세트에서 사용하지 않은 10장의 딸기 이미지를 사용하였다.
결과 및 고찰
1. 병충해 검출 재현율 비교
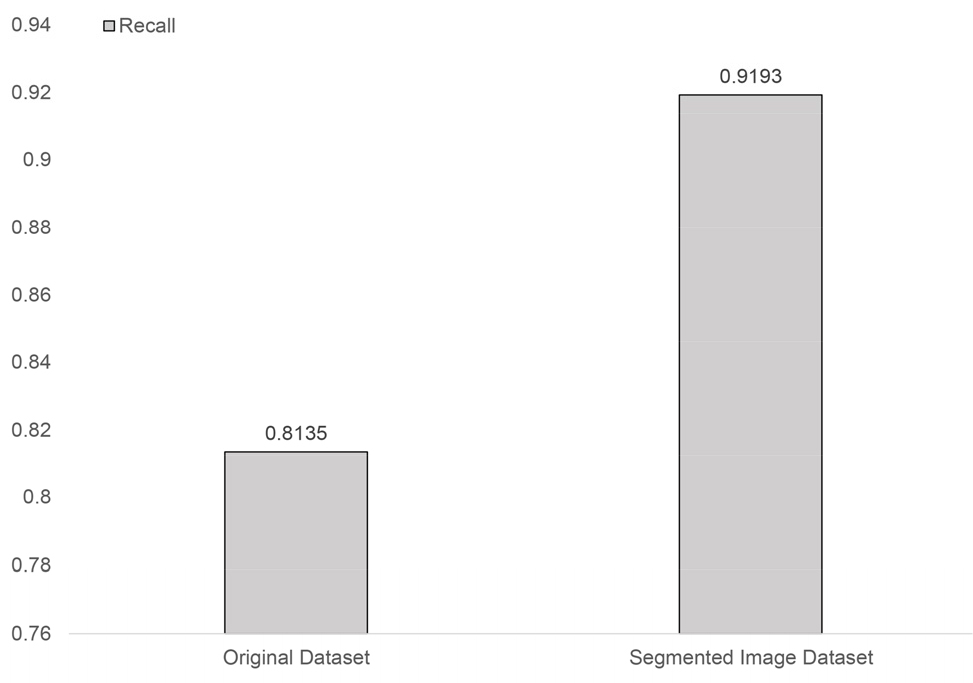
병충해 검출 재현율은 딥러닝 모델이 영상 데이터 속 병충해를 검출하는 비율이다. 재현율이 높을수록 딥러닝 모델은 영상 데이터 속 많은 병충해를 검출할 수 있으며 수식2로 표현된다(Olson과 Delen, 2008). TP(True Positive)는 실제 병충해를 딥러닝 모델이 병충해로 검출한 비율이며 FN(False Neative)는 딥러닝 모델이 실제 병충해를 병충해로 검출하지 못한 비율이다. 따라서 재현율은 실제 병충해 중 딥러닝 모델이 병충해라고 검출한 것의 비율이다. Fig. 6은 10장의 병충해가 포함된 영상 데이터를 딥러닝 모델을 통하여 검출한 결과를 백분율인 검출 재현율로 표현한 것이다. Original Dataset은 일반적인 데이터 세트를 이용하여 학습한 딥러닝 모델의 결과이며 전체 영상 데이터 속 병충해를 81.35% 검출한다. Segmented Image Dataset은 분할 이미지 데이터 세트를 이용하여 학습한 딥러닝 모델의 결과이며 전체 영상 데이터 속 병충해를 91.93% 검출한다. 본 논문에서 제안한 분할 이미지 데이터 세트가 일반적인 데이터 세트보다 검출 재현율이 13% 향상됨을 알 수 있다.
2. 병충해 검출 신뢰도 비교
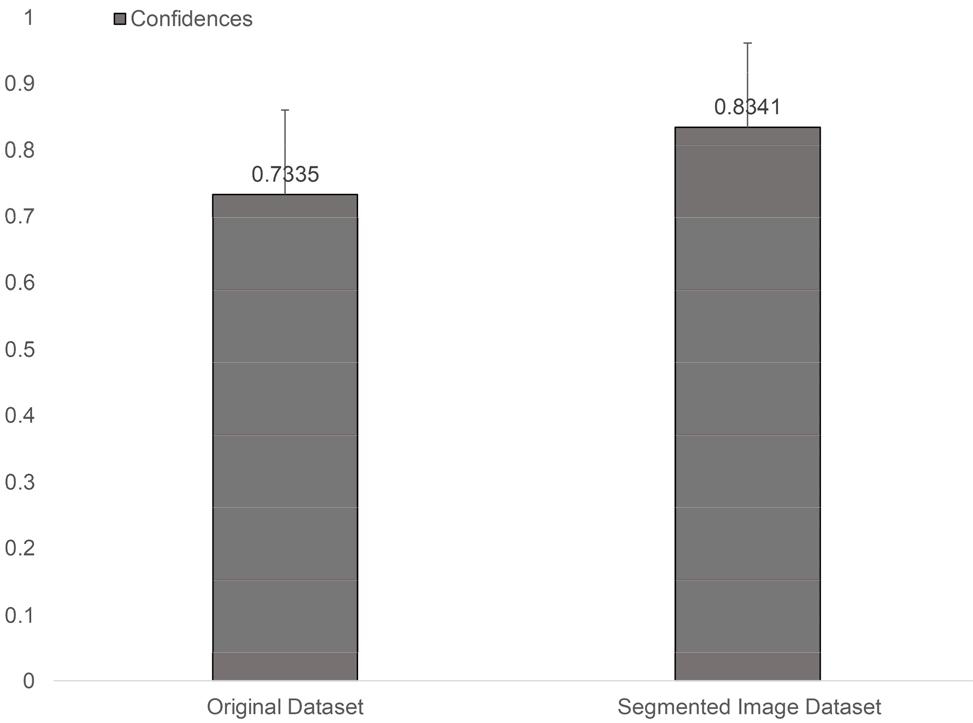
병충해 검출 신뢰도는 딥러닝 모델이 검출한 병충해를 신뢰할 수 있는 비율이다. Fig. 7은 10장의 병충해가 포함된 영상 데이터를 딥러닝 모델이 검출한 결과의 신뢰도를 백분율로 표현한 것이다. 임계 값은 50%로 설정하여 50% 미만의 병충해 검출 결과는 제외되었으며 딥러닝 모델이 검출한 50개의 병충해 객체의 신뢰도를 기준으로 하였다. Original Dataset은 일반적인 데이터 세트를 이용하여 학습한 딥러닝 모델의 결과이며 평균적으로 73.35% 병충해 검출 신뢰도를 보인다. Segmented Image Dataset은 분할 이미지 데이터 세트를 이용하여 학습한 딥러닝 모델의 결과이며 평균적으로 83.41% 병충해 검출 신뢰도를 보인다. 본 논문에서 제안한 분할 이미지 데이터 세트가 일반적인 데이터 세트보다 검출 신뢰도가 14% 향상됨을 알 수 있다.
본 논문은 병충해 검출 모델이 기존의 학습 데이터 세트와 제안하는 병징에 특화된 데이터 세트를 별개의 학습을 통해 각 모델의 성능을 비교분석 하였다. 검출 대상으로 선정한 딸기 병충해는 전염성과 작물에 끼치는 영향이 치명적이기 때문에 조기 발견이 매우 중요하다. 하지만 해당 병충해들은 발병 초기에 큰 변화가 없어 발견하기 어렵고, 작물에 병징이 나타난 후에도 육안으로 병충해를 발견해야 하므로 많은 인력이 소모된다. 반면 딥러닝을 이용한 병충해 검출은 주기적으로 촬영한 작물의 영상 데이터 속 병충해를 감지한다. 주기적으로 촬영된 영상 데이터는 작물의 병충해를 조기 발견할 수 있으며 자동으로 병충해를 검출하기 때문에 별도의 인력도 필요하지 않다. 따라서 딥러닝을 이용한 병충해 검출법이 기존의 검출법보다 병충해에 빠르게 대응할 수 있다. 또한 본 논문에서 제안하는 병징에 특화된 학습 데이터 세트를 구축하여 모델을 학습한다면, 모델의 성능을 개선할 수 있다. 후속 연구에서 더 많은 학습 데이터 세트와 최적화된 딥러닝 모델을 이용한다면, 병충해 검출 성능이 기존보다 개선될 수 있으며 실제 농가에서의 서비스도 기대할 수 있다. 결국 개선된 병충해 검출 모델은 더욱 체계화된 스마트팜 시스템 구축에 활용되고, 발전하는 AI 기술을 통하여 알고리즘은 농업에 최적화되어 농업에 진입하는 장벽을 완화할 수 있을 것으로 판단된다.
